一、in的用法
使用场景:查询的时候,条件字段的值存在于某个数据集
语法:select...from 表名 where 条件字段 in(数据集/子查询)
示例:
-- 查询用户id为7,8,9的用户 select * from test_zjx where id in(7,8,9);
扩展:not in 的用法
使用场景:查询的时候,条件字段的值不存在于某个数据集
语法:select...from 表名 where 条件字段 not in(数据集/子查询)
-- 查询用户id为不为7,8,9的用户 select * from test_zjx where id not in(7,8,9);
二、模糊查询(like)
使用场景:查询的时候,条件字段的值不完整的情况
语法:%用来匹配任意长度的字符串,%出现的位置不同代表的意义不同
_用来匹配一个长度的字符串
eg:1)条件字段的值以任意字符串开头,以XX结尾的值
select 字段1,字段2....字段n from 表名 where 条件字段 like ‘%XX’;
2)条件字段的值以XX开头,以任意字符串结尾的值
select 字段1,字段2....字段n from 表名 where 条件字段 like ‘XX%’;
3)条件字段的值包含了XX
select 字段1,字段2....字段n from 表名 where 条件字段 like ‘%XX%’;
-- 查找以任意字符串开头,以梦结尾的姓名 SELECT `name` FROM `test_zjx` WHERE `name`LIKE ‘%梦‘; -- 查找以一个字符串开头,以梦结尾的姓名 SELECT `name` FROM `test_zjx` WHERE `name`LIKE ‘_梦‘; -- 查找李某梦的人 SELECT `name` FROM `test_zjx` WHERE `name`LIKE ‘李_梦‘;

三、分组(group by)
使用场景:按照某一个,或者多个字段来分组,使用时至少需要一个分组字段。
语法:select 分组字段,聚合函数 from 查询涉及到的表 group by 分组字段 having 过滤条件
语法解释:
聚合函数:对一组值执行计算并返回单一值的函数。聚合函数经常与select语句的group by子句同时使用,常见的聚合函数有sum()、count()、avg()、min()、max()等。
having:在分完组以后如果想在这个分组结果的基础上继续过滤的话就必须把过滤条件写在having后面。
示例:
-- 按项目分组,统计投资表中各个项目的投资次数 select LoadID,count() from invest group by LoadID;


![]()
四、查询(between and)
使用场景:条件字段的取值处于两个数据范围内的情况。
语法:select ...from 表名 where 条件字段 between 数值A and 数值B;
示例:
-- 找出用户表可用余额在1000 到 4000 的用户信息(包含边界值). select * from member where LeaveAmount between 1000.00 and 4000.00;
五、去重(distinct)
使用场景:去除查询结果中的重复数据。
语法:select distinct 字段名1 from 表名;
示例:
-- 查询所有投资的用户ID select distinct MemberID from invest;
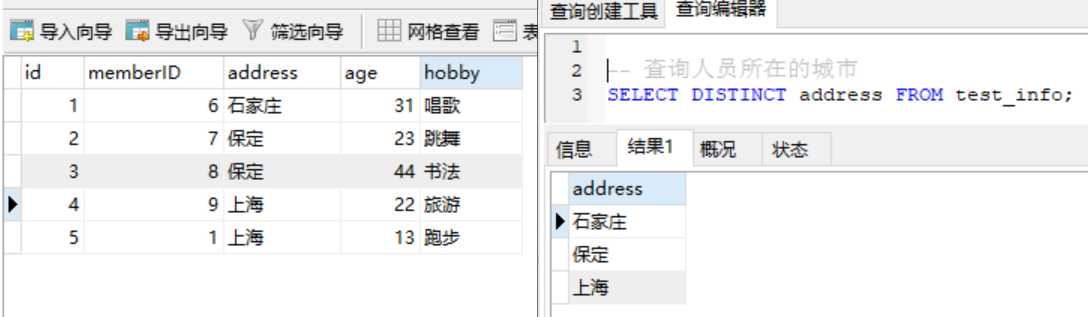
注意:distinct去重可以有多列,如果使用多列时,必须多列都相同才能去重。

六、分页(limit)
使用场景:取查询结果的前n条。
语法:select...from 表名 limit m,n;
示例:每页取十条展示:
第一页为:limit 0,10 表示取索引0开始取10条记录;
第二页为:limit 10,10 表示取索引10开始取10条记录;
第三页为:limit 20,10 表示取索引20开始取10条记录;
七、查询语句顺序



原文:https://www.cnblogs.com/zhangjx2457/p/13597947.html