爬取梨视频网站某模块全部信息;
字段信息为:视频标题、作者、点赞数,纯视频链接,并且存入txt文档。
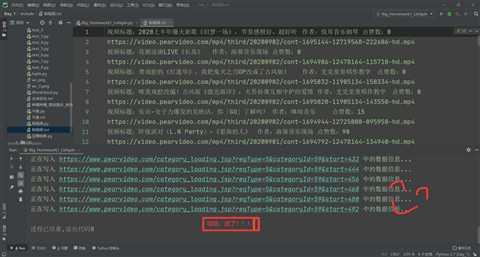
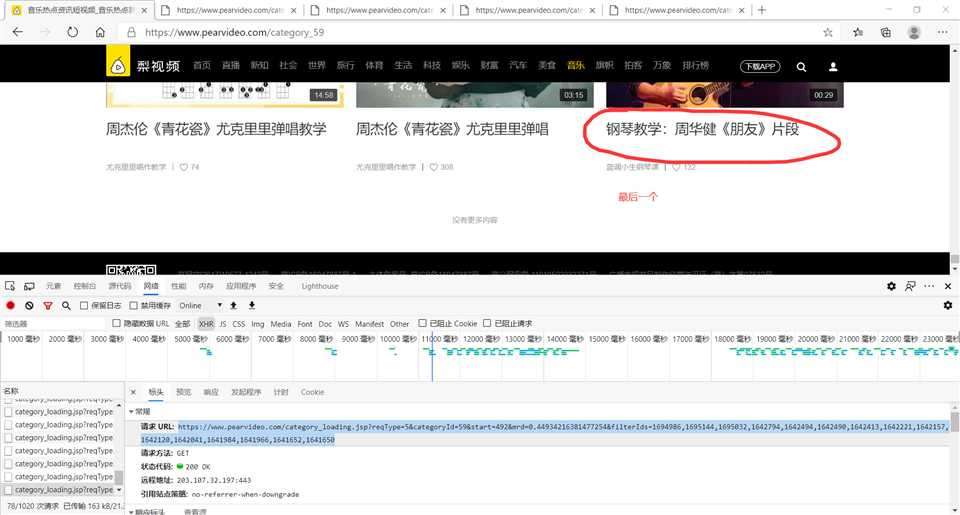
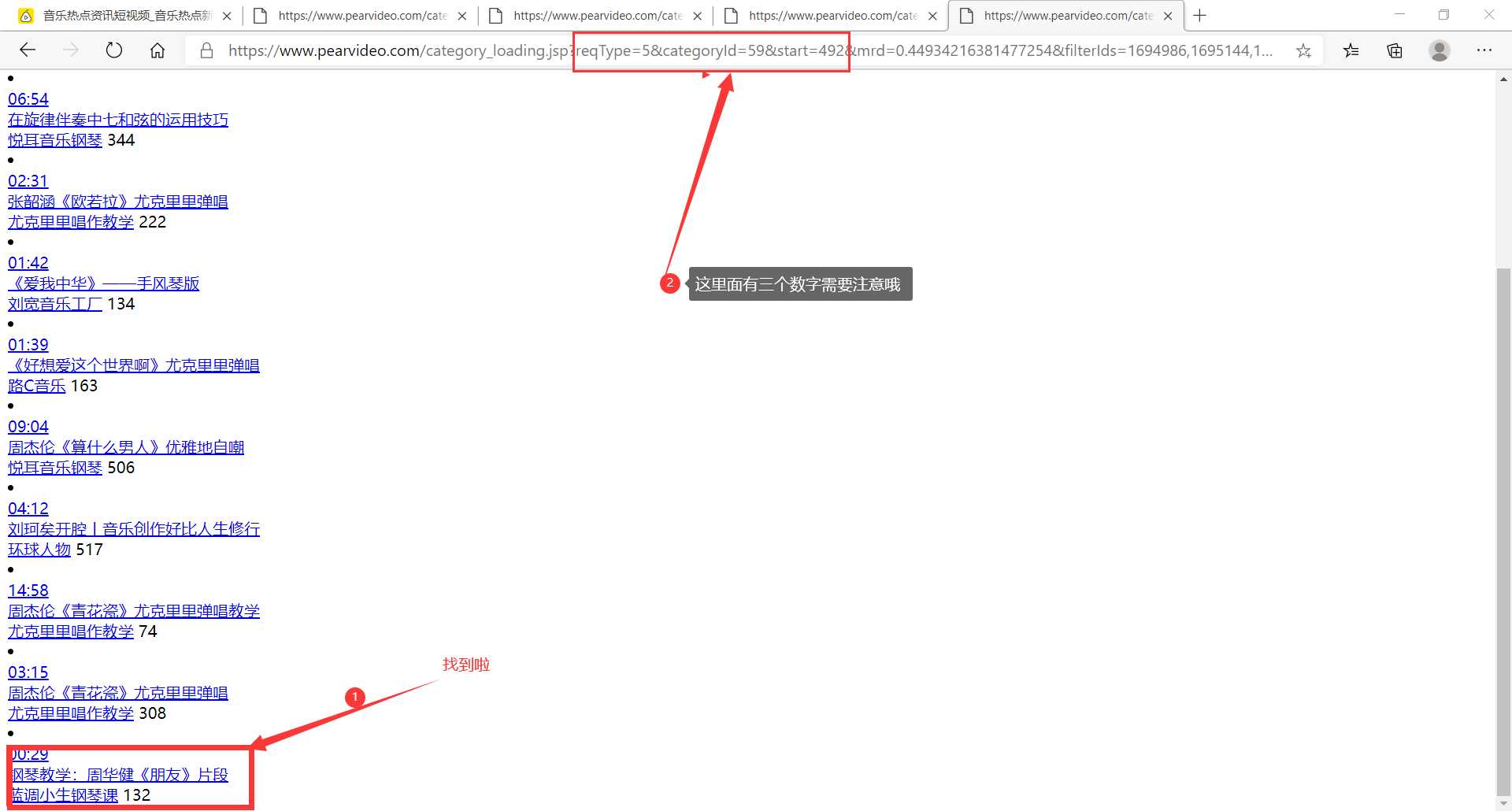
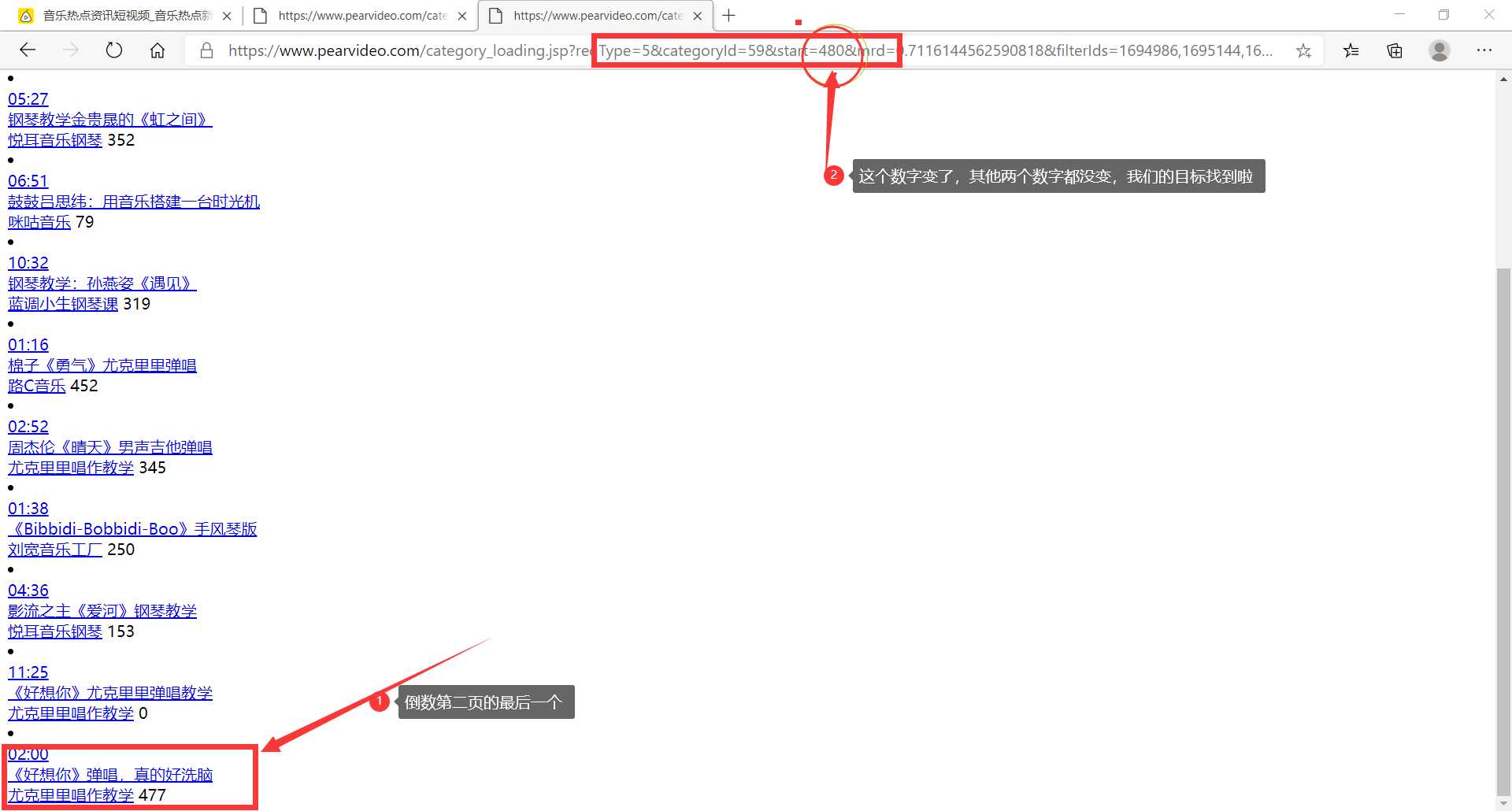
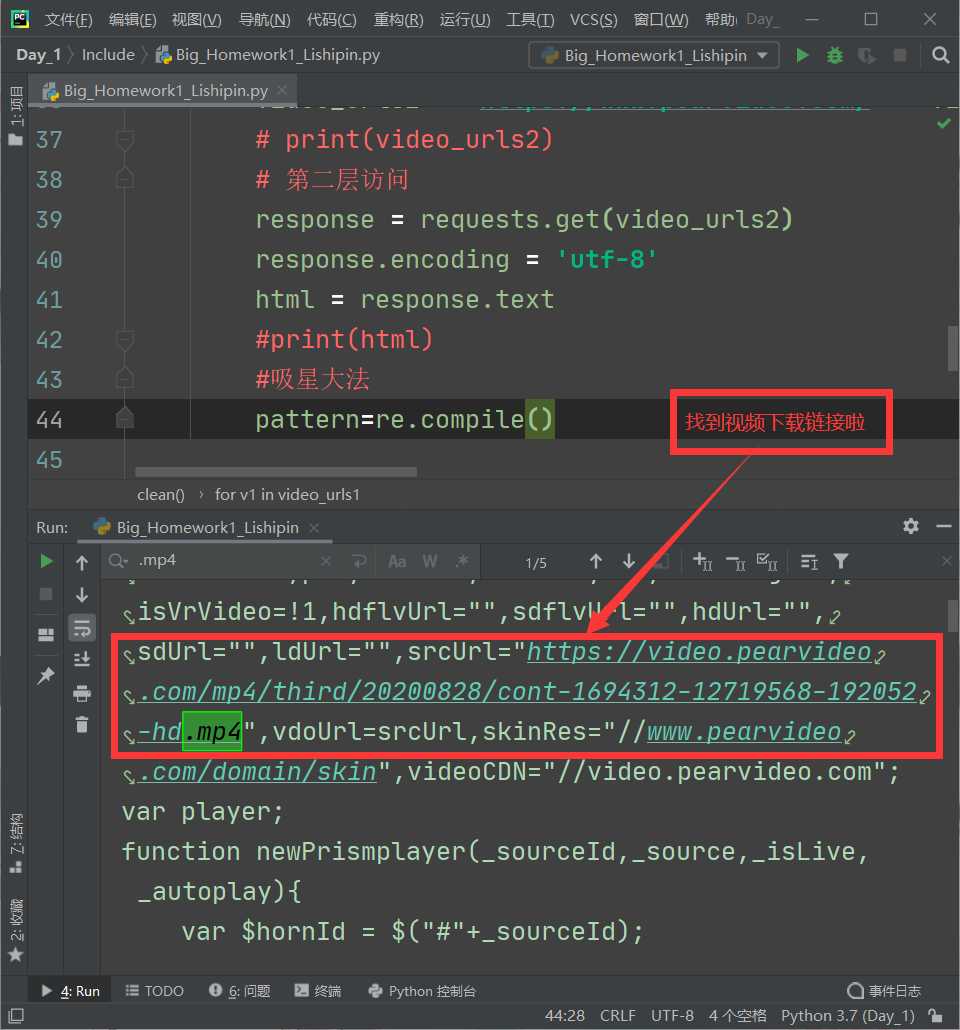

1 import requests 2 from lxml import etree 3 from urllib import request 4 import re 5 6 # 全局变量(请求头+文件IO对象) 7 headers = { 8 ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36 Edg/85.0.564.44‘} 9 file = open(‘./梨视频.txt‘, ‘w‘, encoding=‘utf-8‘) 10 11 12 # 采集前端源码 13 def index(): 14 for num in range(0, 493, 12): 15 base_url = ‘https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=59&start={}‘.format(num) 16 print(‘正在写入‘, base_url, ‘中的数据信息...‘) 17 response = requests.get(base_url, headers=headers) # 模拟访问+请求头 18 response.encoding = ‘utf-8‘ # 解码 19 html = response.text # 获取源码 20 clean(html) # 清洗数据 21 22 23 # 清洗数据 24 def clean(html): 25 htmls = etree.HTML(html) # 预处理 26 video_titles = htmls.xpath(‘//div[@class="vervideo-bd"]/a/div[2]/text()‘) 27 # print(video_titles),视频标题 28 video_authors = htmls.xpath(‘//div[@class="vervideo-bd"]/div/a/text()‘) 29 # print(video_authors),作者 30 video_likes = htmls.xpath(‘//div[@class="vervideo-bd"]/div/span/text()‘) 31 # print(video_likes),点赞数 32 video_urls1 = htmls.xpath(‘//div[@class="vervideo-bd"]/a/@href‘) 33 # print(video_urls1),不完整的视频链接 34 printt(video_titles,video_authors,video_likes,video_urls1) 35 36 37 # 打印数据 38 def printt(video_titles,video_authors,video_likes,video_urls1): 39 # 拼接 40 for vu,vt,va,vl in zip(video_urls1,video_titles,video_authors,video_likes): 41 video_urls2 = ‘https://www.pearvideo.com/‘ + vu 42 # print(video_urls2) 43 # 第二层访问 44 response = requests.get(video_urls2) 45 response.encoding = ‘utf-8‘ 46 html = response.text 47 # print(html) 48 # 吸星大法 49 pattern = re.compile(‘srcUrl="(.*?)",vdoUrl‘) 50 video_url = pattern.findall(html)[0] 51 # print(video_url) 52 full_info=‘视频标题:‘+vt+‘\t‘+‘作者:‘+va+‘\t‘+‘点赞数:‘+str(vl)+‘\n‘+video_url 53 file.write(full_info+‘\n‘) 54 55 56 # 下载模块 57 def download(): 58 pass 59 60 61 if __name__ == ‘__main__‘: 62 index() 63 file.close()
因为我先写的大作业2,所以这个写的顺的一批,中间也没遇到什么烦人的bug,又是一段开心的编程经历。
Python爬虫实验报告之Big_Homework1_Lishipin
原文:https://www.cnblogs.com/Aoke/p/13610747.html
