大家都知道HashMap是线程不安全的,我们应该使用ConcurrentHashMap。但是为什么HashMap是线程不安全的呢,今天就一起来探讨这个问题。
注意
HashMap的线程不安全体现在会造成死循环、数据丢失、数据覆盖这些问题。其中死循环和数据丢失是在JDK1.7中出现的问题,在JDK1.8中已经得到解决,然而1.8中仍会有数据覆盖这样的问题。
HashMap的线程不安全主要是发生在扩容函数中,即根源是在transfer函数中,JDK1.7中HashMap的transfer函数如下:
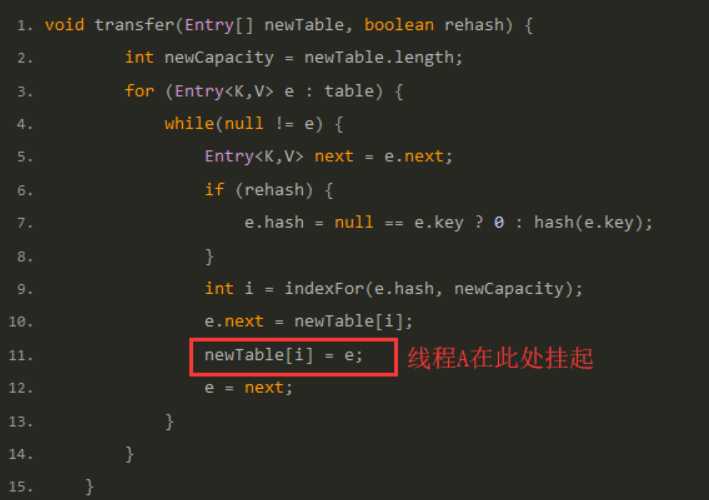
1 void transfer(Entry[] newTable, boolean rehash) { 2 int newCapacity = newTable.length; 3 for (Entry<K,V> e : table) { 4 while(null != e) { 5 Entry<K,V> next = e.next; 6 if (rehash) { 7 e.hash = null == e.key ? 0 : hash(e.key); 8 } 9 int i = indexFor(e.hash, newCapacity); 10 e.next = newTable[i]; 11 newTable[i] = e; 12 e = next; 13 } 14 } 15 }
这段代码是HashMap的扩容操作,重新定位每个桶的下标,并采用头插法将元素迁移到新数组中。头插法会将链表的顺序翻转,这也是形成死循环的关键点。理解了头插法后再继续往下看是如何造成死循环以及数据丢失的。
假设现在有两个线程A、B同时对下面这个HashMap进行扩容操作:
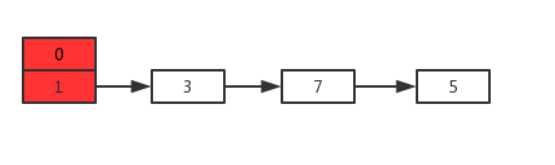
正常扩容后的结果是下面这样的:
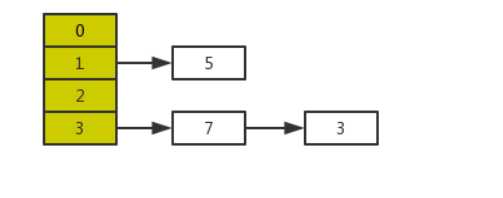
但是当线程A执行到上面transfer函数的第11行代码时,CPU时间片耗尽,线程A被挂起。即如下图中位置所示:
此时线程A中:e=3、next=7、e.next=null
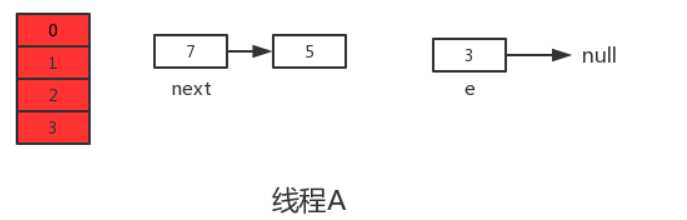
接着继续执行下一轮循环,此时e=7,从主内存中读取e.next时发现主内存中7.next=3,于是乎next=3,并将7采用头插法的方式放入新数组中,并继续执行完此轮循环,结果如下:
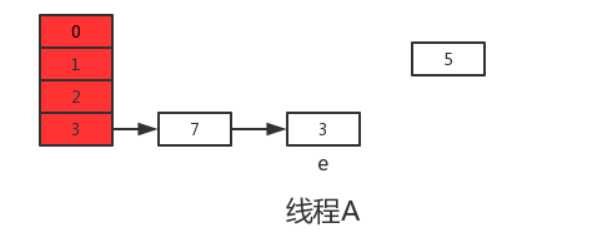
执行下一次循环可以发现,next=e.next=null,所以此轮循环将会是最后一轮循环。接下来当执行完e.next=newTable[i]即3.next=7后,3和7之间就相互连接了,当执行完newTable[i]=e后,3被头插法重新插入到链表中,执行结果如下图所示:
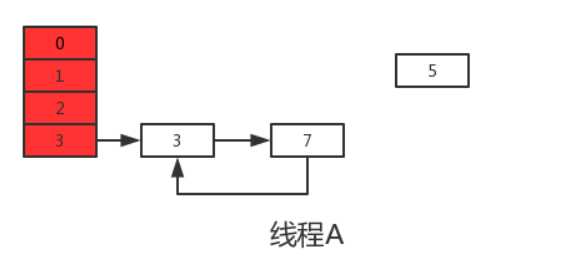
上面说了此时e.next=null即next=null,当执行完e=null后,将不会进行下一轮循环。到此线程A、B的扩容操作完成,很明显当线程A执行完后,HashMap中出现了环形结构,当在以后对该HashMap进行操作时会出现死循环。
并且从上图可以发现,元素5在扩容期间被莫名的丢失了,这就发生了数据丢失的问题。
根据上面JDK1.7出现的问题,在JDK1.8中已经得到了很好的解决,如果你去阅读1.8的源码会发现找不到transfer函数,因为JDK1.8直接在resize函数中完成了数据迁移。另外说一句,JDK1.8在进行元素插入时使用的是尾插法。
为什么说JDK1.8会出现数据覆盖的情况喃,我们来看一下下面这段JDK1.8中的put操作代码:
1 final V putVal(int hash, K key, V value, boolean onlyIfAbsent, 2 boolean evict) { 3 Node<K,V>[] tab; Node<K,V> p; int n, i; 4 if ((tab = table) == null || (n = tab.length) == 0) 5 n = (tab = resize()).length; 6 if ((p = tab[i = (n - 1) & hash]) == null) // 如果没有hash碰撞则直接插入元素 7 tab[i] = newNode(hash, key, value, null); 8 else { 9 Node<K,V> e; K k; 10 if (p.hash == hash && 11 ((k = p.key) == key || (key != null && key.equals(k)))) 12 e = p; 13 else if (p instanceof TreeNode) 14 e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); 15 else { 16 for (int binCount = 0; ; ++binCount) { 17 if ((e = p.next) == null) { 18 p.next = newNode(hash, key, value, null); 19 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st 20 treeifyBin(tab, hash); 21 break; 22 } 23 if (e.hash == hash && 24 ((k = e.key) == key || (key != null && key.equals(k)))) 25 break; 26 p = e; 27 } 28 } 29 if (e != null) { // existing mapping for key 30 V oldValue = e.value; 31 if (!onlyIfAbsent || oldValue == null) 32 e.value = value; 33 afterNodeAccess(e); 34 return oldValue; 35 } 36 } 37 ++modCount; 38 if (++size > threshold) 39 resize(); 40 afterNodeInsertion(evict); 41 return null; 42 }
其中第六行代码是判断是否出现hash碰撞,假设两个线程A、B都在进行put操作,并且hash函数计算出的插入下标是相同的,当线程A执行完第六行代码后由于时间片耗尽导致被挂起,而线程B得到时间片后在该下标处插入了元素,完成了正常的插入,然后线程A获得时间片,由于之前已经进行了hash碰撞的判断,所有此时不会再进行判断,而是直接进行插入,这就导致了线程B插入的数据被线程A覆盖了,从而线程不安全。
除此之前,还有就是代码的第38行处有个++size,我们这样想,还是线程A、B,这两个线程同时进行put操作时,假设当前HashMap的zise大小为10,当线程A执行到第38行代码时,从主内存中获得size的值为10后准备进行+1操作,但是由于时间片耗尽只好让出CPU,线程B快乐的拿到CPU还是从主内存中拿到size的值10进行+1操作,完成了put操作并将size=11写回主内存,然后线程A再次拿到CPU并继续执行(此时size的值仍为10),当执行完put操作后,还是将size=11写回内存,此时,线程A、B都执行了一次put操作,但是size的值只增加了1,所有说还是由于数据覆盖又导致了线程不安全
HashMap的线程不安全主要体现在下面两个方面:
1.在JDK1.7中,当并发执行扩容操作时会造成环形链和数据丢失的情况。
2.在JDK1.8中,在并发执行put操作时会发生数据覆盖的情况。
原文:https://www.cnblogs.com/JonaLin/p/13616245.html