在ml模型的学习过程中,算法本身还是在偏差和方差上做权衡
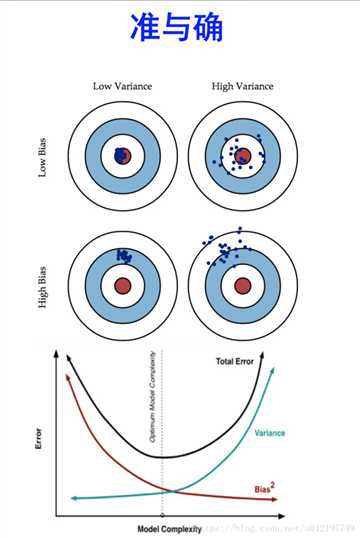
欠拟合: 不能很好的拟合数据, 训练集上很差
过拟合: 训练集上表现好,测试集上表现差
方差: Variance反映的是模型每一次输出结果与模型输出期望之间的误差,即模型的稳定性。反应预测的波动情况。
偏差: Bias反映的是模型在样本上的输出与真实值之间的误差,即模型本身的精准度,即算法本身的拟合能力
欠拟合对应着高偏差, 过拟合对应着高方差
判断方法: 我们可以通过交叉验证, 来判断模型的偏差与方差情况: 我们计算没一折交叉验证时候, 模型的偏差和方差,
然后分析模型究竟是高偏差呢还是高方差. 如果有时候模型性能好, 有时候又不好, 那么可以断定, 出现了高方差的情况
一般来说,模型出现过拟合很有可能是数据太小,其次是验证集和训练集分布不一致,再或者,验证集和训练集的数据预处理方式不一致。其次后面才更大可能是模型过于复杂,模型结构存在问题等原因。
遇到过拟合的时候,一般有以下几种处理策略
early stopping非常的有用,但如果没两个epoch就overfitting了,那就比较麻烦了
DL里主要就是在隐藏层对神经元之间的权重做L1 和 L2了,L1导致稀疏向量,L2权重衰减.
也有XGB的loss加正则控制模型复杂度以控制结构风险,线性模型+L1=Lasso, 线性model+L2=Righe regression,线性model+L1+L2=Elestic Net
DL里,其实drop out已经有了模型融合的味道在里面了,比较每次train的时候,被drop掉的neural连接都是随机的。从被drop掉的角度来看,和L1也有的拼
bn更多时候是为了防止梯度消失而提出的,但发现也有能缓解over fitting
其实很多时候L2也叫做weight decay,但是这里说的weight decay和L2最大的区别就是:它对梯度较大的变量进行正则化
具体的可以参看这篇文章Decoupled Weight Decay Regularization
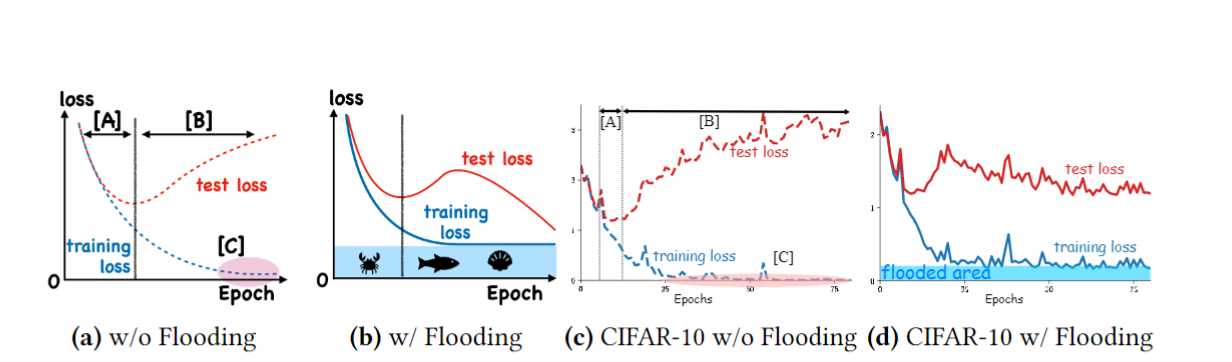
这是2020年ICML的一篇工作,代码就只有一行。意识就是当出现过拟合的时候,对损失函数加上一个超参b,使其做方向梯度上升,这时候神奇的发现,val loss做了2次梯度下降
不过实操一遍发现,好像也不是那么回事,也许是我任务的原因。
文章链接:Do We Need Zero Training Loss Per Achieving Zero Training Error
原文:https://www.cnblogs.com/zhouyc/p/13620203.html