前言
之前有文章 《从0到1学习Flink》—— Flink 写入数据到 Kafka 写过 Flink 将处理后的数据后发到 Kafka 消息队列中去,当然我们常用的消息队列可不止这一种,还有 RocketMQ、RabbitMQ 等,刚好 Flink 也支持将数据写入到 RabbitMQ,所以今天我们就来写篇文章讲讲如何将 Flink 处理后的数据写入到 RabbitMQ。
前提准备
安装 RabbitMQ
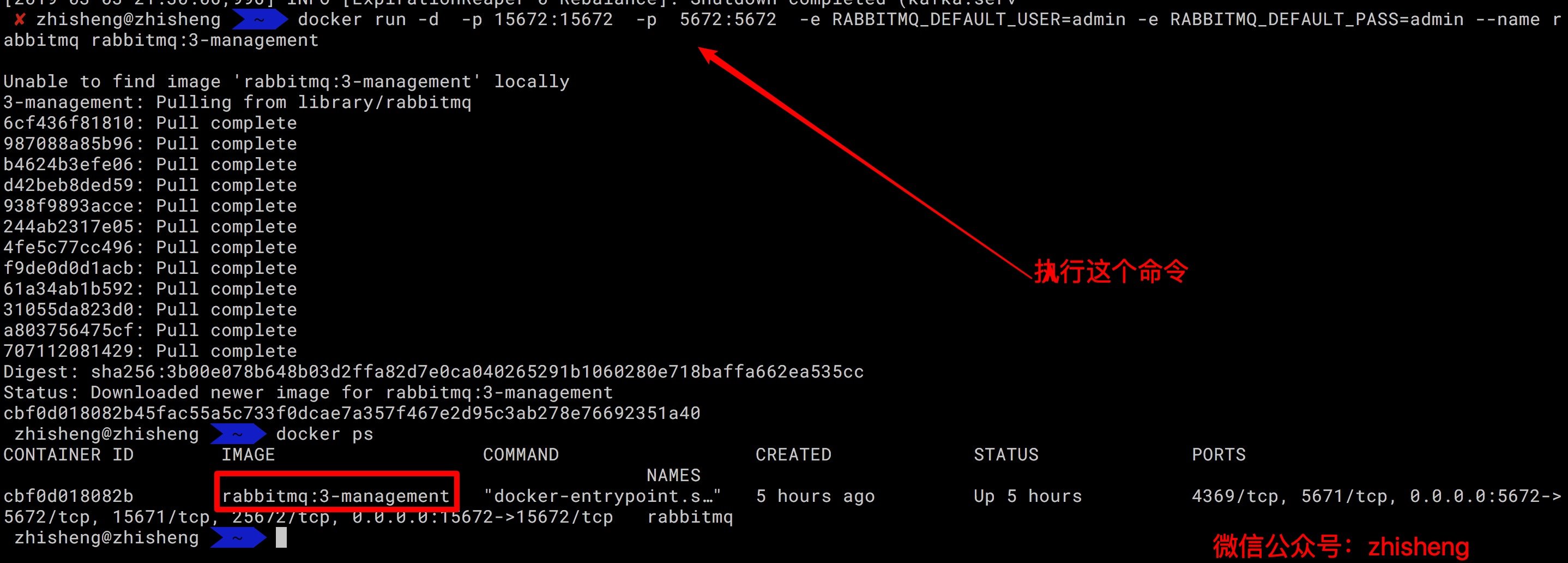
这里我直接用 docker 命令安装吧,先把 docker 在 mac 上启动起来。
在命令行中执行下面的命令:
1
|
docker run -d -p 15672:15672 -p 5672:5672 -e RABBITMQ_DEFAULT_USER=admin -e RABBITMQ_DEFAULT_PASS=admin --name rabbitmq rabbitmq:3-management
|
对这个命令不懂的童鞋可以看看我以前的文章:http://www.54tianzhisheng.cn/2018/01/26/SpringBoot-RabbitMQ/
登录用户名和密码分别是:admin / admin ,登录进去是这个样子就代表安装成功了:
依赖
pom.xml 中添加 Flink connector rabbitmq 的依赖如下:
1
2
3
4
5
|
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-rabbitmq_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
|
生产者
这里我们依旧自己写一个工具类一直的往 RabbitMQ 中的某个 queue 中发数据,然后由 Flink 去消费这些数据。
注意按照我的步骤来一步步操作,否则可能会出现一些错误!
RabbitMQProducerUtil.java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
public class RabbitMQProducerUtil {
public final static String QUEUE_NAME = "zhisheng";
public static void main(String[] args) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
factory.setUsername("admin");
factory.setPassword("admin");
factory.setPort(5672);
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
String message = "Hello zhisheng";
for (int i = 0; i < 1000; i++) {
channel.basicPublish("", QUEUE_NAME, null, (message + i).getBytes("UTF-8"));
System.out.println("Producer Send +‘" + message + i);
}
channel.close();
connection.close();
}
}
|
Flink 主程序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
import com.zhisheng.common.utils.ExecutionEnvUtil;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.rabbitmq.RMQSource;
import org.apache.flink.streaming.connectors.rabbitmq.common.RMQConnectionConfig;
public class Main {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
ParameterTool parameterTool = ExecutionEnvUtil.PARAMETER_TOOL;
final RMQConnectionConfig connectionConfig = new RMQConnectionConfig
.Builder().setHost("localhost").setVirtualHost("/")
.setPort(5672).setUserName("admin").setPassword("admin")
.build();
DataStreamSource<String> zhisheng = env.addSource(new RMQSource<>(connectionConfig,
"zhisheng",
true,
new SimpleStringSchema()))
.setParallelism(1);
zhisheng.print();
env.execute("flink learning connectors rabbitmq");
}
}
|
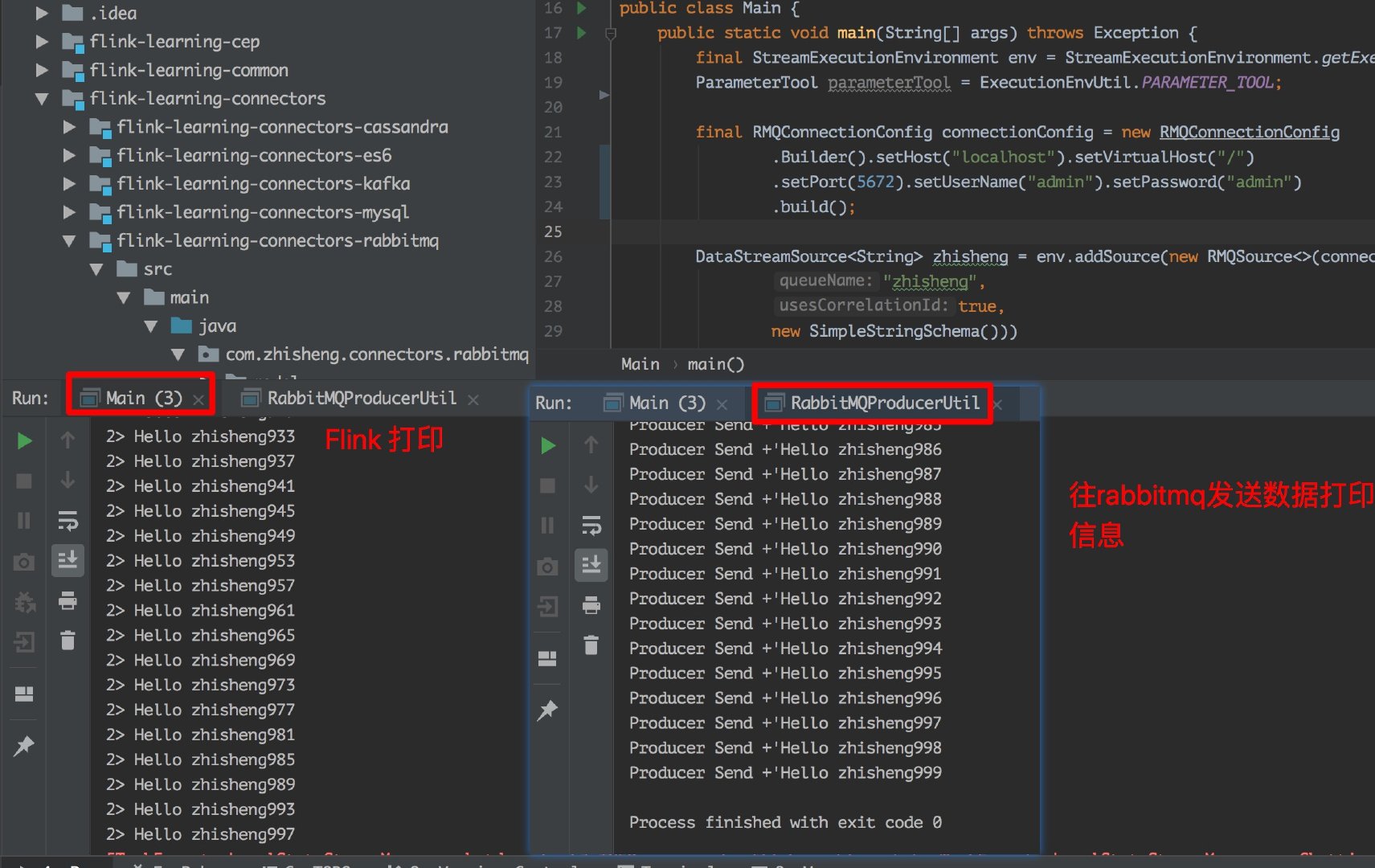
运行 RabbitMQProducerUtil 类,再运行 Main 类!
注意??:
1、RMQConnectionConfig 中设置的用户名和密码要设置成 admin/admin,如果你换成是 guest/guest,其实是在 RabbitMQ 里面是没有这个用户名和密码的,所以就会报这个错误:
1
|
nested exception is com.rabbitmq.client.AuthenticationFailureException: ACCESS_REFUSED - Login was refused using authentication mechanism PLAIN. For details see the broker logfile.
|
不出意外的话应该你运行 RabbitMQProducerUtil 类后,立马两个运行的结果都会出来,速度还是很快的。
2、如果你在 RabbitMQProducerUtil 工具类中把注释的那行代码打开的话:
就会出现这种错误:
1
|
Caused by: com.rabbitmq.client.ShutdownSignalException: channel error; protocol method: #method<channel.close>(reply-code=406, reply-text=PRECONDITION_FAILED - inequivalent arg ‘durable‘ for queue ‘zhisheng‘ in vhost ‘/‘: received ‘true‘ but current is ‘false‘, class-id=50, method-id=10)
|
这是因为你打开那个注释的话,一旦你运行了该类就会创建一个叫做 zhisheng 的 Queue,当你再运行 Main 类中的时候,它又会创建这样一个叫 zhisheng 的 Queue,然后因为已经有同名的 Queue 了,所以就有了冲突,解决方法就是把那行代码注释就好了。
3、该 connector(连接器)中提供了 RMQSource 类去消费 RabbitMQ queue 中的消息和确认 checkpoints 上的消息,它提供了三种不一样的保证:
- Exactly-once(只消费一次): 前提条件有,1 是要开启 checkpoint,因为只有在 checkpoint 完成后,才会返回确认消息给 RabbitMQ(这时,消息才会在 RabbitMQ 队列中删除);2 是要使用 Correlation ID,在将消息发往 RabbitMQ 时,必须在消息属性中设置 Correlation ID。数据源根据 Correlation ID 把从 checkpoint 恢复的数据进行去重;3 是数据源不能并行,这种限制主要是由于 RabbitMQ 将消息从单个队列分派给多个消费者。
- At-least-once(至少消费一次): 开启了 checkpoint,但未使用相 Correlation ID 或 数据源是并行的时候,那么就只能保证数据至少消费一次了
- No guarantees(无法保证): Flink 接收到数据就返回确认消息给 RabbitMQ
Sink 数据到 RabbitMQ
RabbitMQ 除了可以作为数据源,也可以当作下游,Flink 消费数据做了一些处理之后也能把数据发往 RabbitMQ,下面演示下 Flink 消费 Kafka 数据后写入到 RabbitMQ。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
public class Main1 {
public static void main(String[] args) throws Exception {
final ParameterTool parameterTool = ExecutionEnvUtil.createParameterTool(args);
StreamExecutionEnvironment env = ExecutionEnvUtil.prepare(parameterTool);
DataStreamSource<Metrics> data = KafkaConfigUtil.buildSource(env);
final RMQConnectionConfig connectionConfig = new RMQConnectionConfig
.Builder().setHost("localhost").setVirtualHost("/")
.setPort(5672).setUserName("admin").setPassword("admin")
.build();
data.addSink(new RMQSink<>(connectionConfig, "zhisheng001", new MetricSchema()));
env.execute("flink learning connectors rabbitmq");
}
}
|
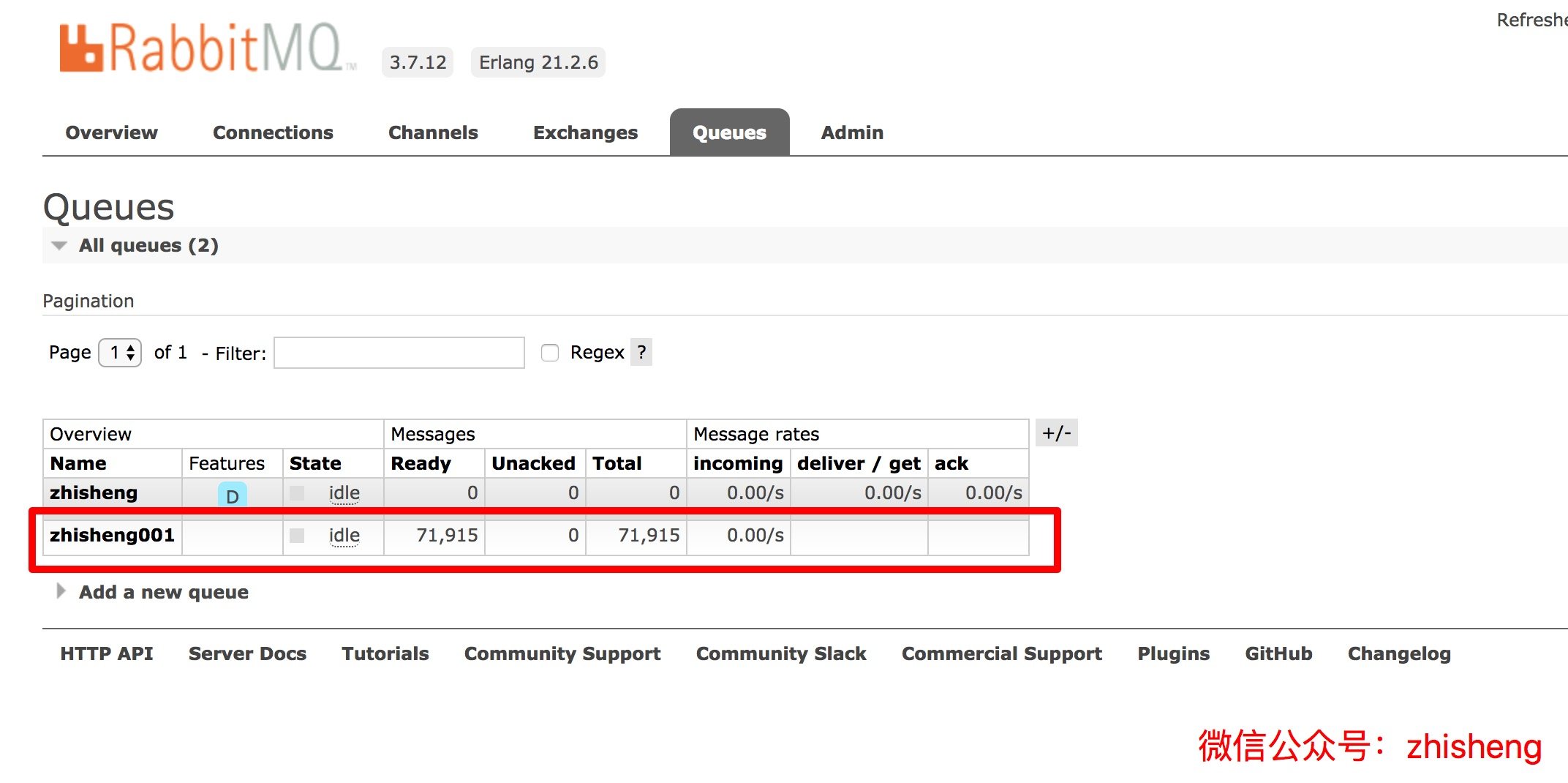
是不是很简单?但是需要注意的是,要换一个之前不存在的 queue,否则是会报错的。
不出意外的话,你可以看到 RabbitMQ 的监控页面会出现新的一个 queue 出来,如下图:
总结
本文先把 RabbitMQ 作为数据源,写了个 Flink 消费 RabbitMQ 队列里面的数据进行打印出来,然后又写了个 Flink 消费 Kafka 数据后写入到 RabbitMQ 的例子!