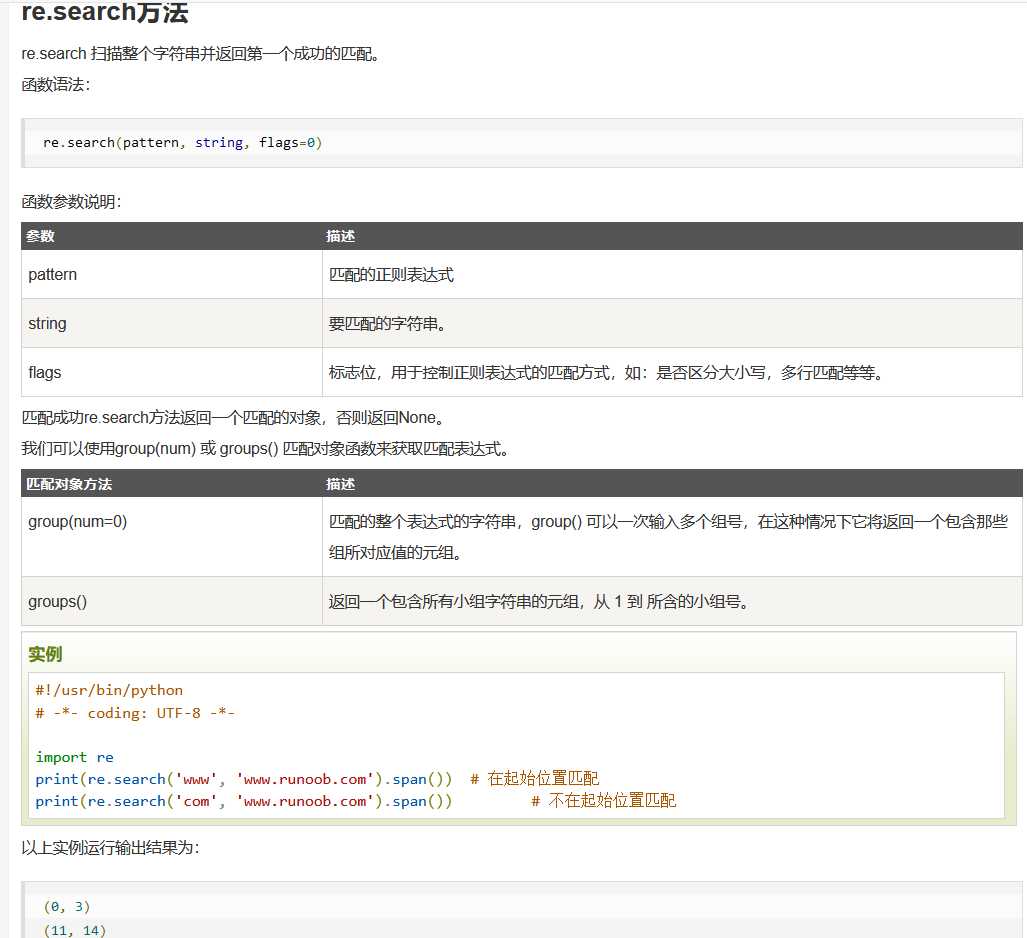
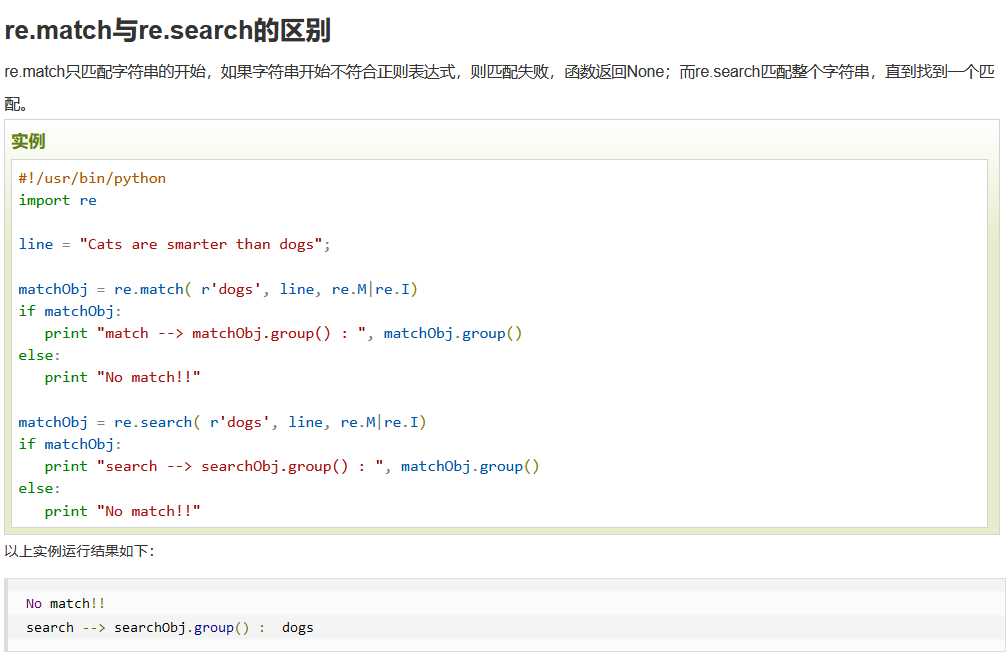
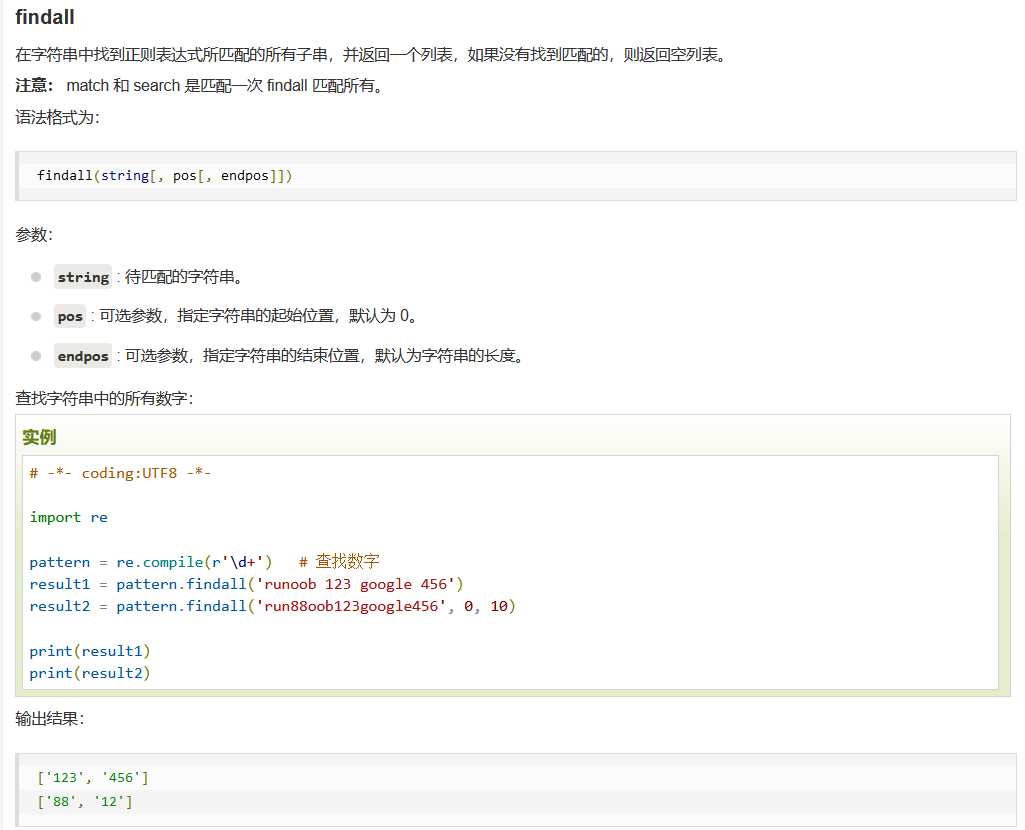
面试举例:
正则表达式匹配第一个URL,s = ‘<img data-original="https://rpic.douyucdn.cn/appCovers/2016/11/13/124871_23424435_small.jpg" ‘ \
‘src="https://rpic.douyucdn.cn/appCovers/2016/11/13/124871_23424435_small.jpg" style="display: incline;">‘
findall结果无需加group(),search需要加group()提取
1 import re 2 s = ‘<img data-original="https://rpic.douyucdn.cn/appCovers/2016/11/13/124871_23424435_small.jpg" ‘ 3 ‘src="https://rpic.douyucdn.cn/appCovers/2016/11/13/124871_23424435_small.jpg" style="display: incline;">‘ 4 # re.findall在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。 5 # 注意: match 和 search 是匹配一次 findall 匹配所有。 6 res = re.findall(r"https://.*?\.jpg", s)[0] 7 print(res) 8 9 # re.search 扫描整个字符串并返回第一个成功的匹配。匹配成功re.search方法返回一个匹配的对象,否则返回None。 10 res = re.search(r"https://.*?\.jpg", s) 11 print(res.group())
运行结果:

如果修改如下,则报错:
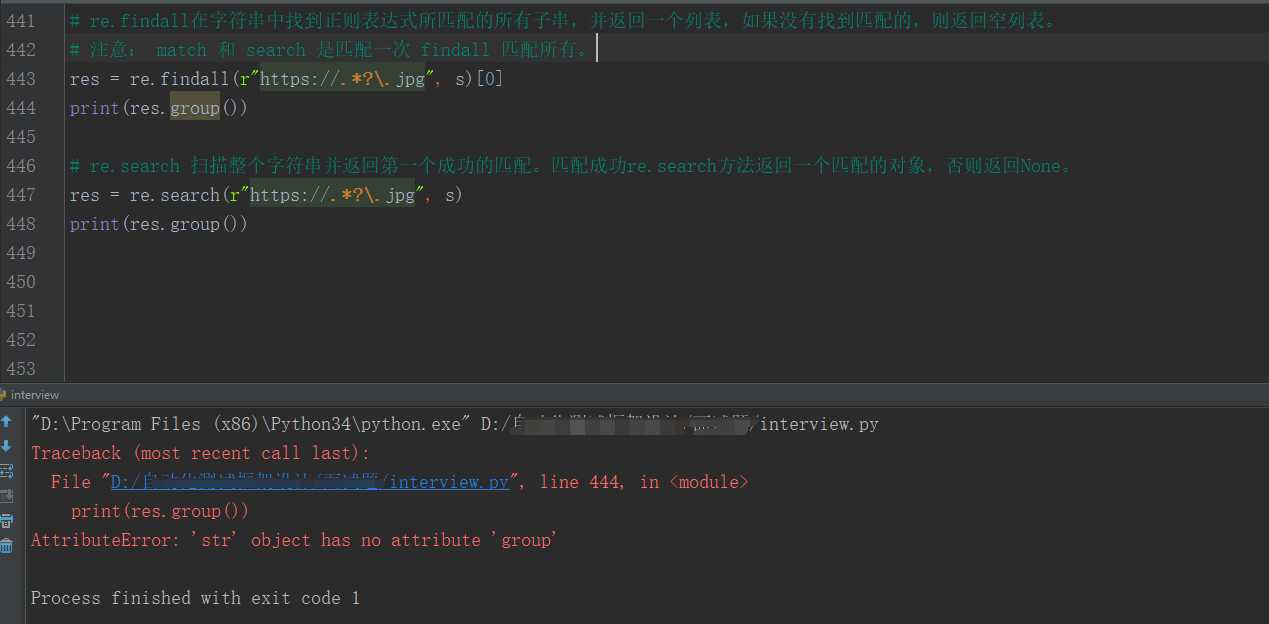
下面的验证证明了re.search方法返回的是一个匹配成功的对象,而不是返回一个列表之类的。
正则表达式re.findall和re.search的使用---面试
原文:https://www.cnblogs.com/annatest/p/13630311.html