@羲凡——只为了更好的活着
特别强调楼主使用spark2.3.2版本,redis5.0.3版本
在pom.xml文件中要添加
<dependency> <groupId>com.redislabs</groupId> <artifactId>spark-redis</artifactId> <version>2.3.1-RC1</version> </dependency>
import org.apache.spark.sql.types.{IntegerType,StringType,StructField,StructType} import org.apache.spark.sql.{SaveMode, SparkSession} object SparkReadRedis { case class Person(name: String, age: Int) def main(args: Array[String]): Unit = { val spark = SparkSession.builder() .appName("SparkReadRedis") .master("local[*]") .config("spark.redis.host","10.101.12.104") .config("spark.redis.port", "6379") .config("spark.redis.auth","aaron227") //指定redis密码 .config("spark.redis.db","0") //指定redis库 .getOrCreate() // 将数据写入到redis中 val personSeq = Seq(Person("Aaron", 30), Person("Peter", 45)) val df = spark.createDataFrame(personSeq) df.write .format("org.apache.spark.sql.redis") .option("table", "person") .option("key.column", "name") .mode(SaveMode.Overwrite) .save() // 从redis中读取数据————方法一 val loadedDf = spark.read .format("org.apache.spark.sql.redis") .option("table", "person") .option("key.column", "name") .load() loadedDf.show(false) // 从redis中读取数据————方法二 spark.sql( s""" |CREATE TEMPORARY VIEW person |(name STRING, age INT,address STRING, salary DOUBLE) |USING org.apache.spark.sql.redis |OPTIONS (table ‘person‘,key.column "name")""".stripMargin) val loadedDf2 = spark.sql(s"SELECT * FROM person") loadedDf2.show(false) // 从redis中读取数据————方法三 val loadedDf3 = spark.read .format("org.apache.spark.sql.redis") .schema(StructType(Array(StructField("id", IntegerType), StructField("name", StringType), StructField("age", IntegerType)))) .option("keys.pattern", "person:*") .option("key.column", "name") .load() loadedDf3.show(false) spark.stop() } }
a. 检查写入是否成功,查询redis结果如下
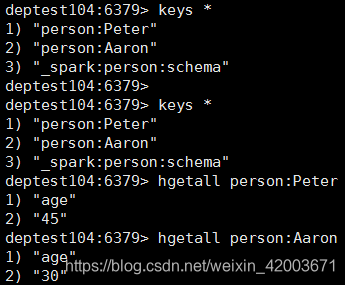
b. 检查读取是否成功,控制台打印结果展示
+-----+---+
|name |age|
+-----+---+
|Peter|45 |
|Aaron|30 |
+-----+---+
+-----+---+-------+------+
|name |age|address|salary|
+-----+---+-------+------+
|Peter|45 |null |null |
|Aaron|30 |null |null |
+-----+---+-------+------+
+----+-----+---+
|id |name |age|
+----+-----+---+
|null|Peter|45 |
|null|Aaron|30 |
+----+-----+---+
原文:https://www.cnblogs.com/huanghanyu/p/13634011.html