1.引言
如果用一句话定义xgboost,很简单:Xgboost就是由很多CART树集成。但,什么是CART树?
数据挖掘或机器学习中使用的决策树有两种主要类型:
而术语分类回归树(CART,Classification And Regression Tree)分析是用于指代上述两种树的总称,由Breiman等人首先提出。
2.回归树
事实上,分类与回归是两个很接近的问题,分类的目标是根据已知样本的某些特征,判断一个新的样本属于哪种已知的样本类,它的结果是离散值。而回归的结果是连续的值。当然,本质是一样的,都是特征(feature)到结果/标签(label)之间的映射。
理清了什么是分类和回归之后,理解分类树和回归树就不难了。
分类树的样本输出(即响应值)是类的形式,比如判断这个救命药是真的还是假的,周末去看电影《风语咒》还是不去。而回归树的样本输出是数值的形式,比如给某人发放房屋贷款的数额就是具体的数值,可以是0到300万元之间的任意值。
所以,对于回归树,你没法再用分类树那套信息增益、信息增益率、基尼系数来判定树的节点分裂了,你需要采取新的方式评估效果,包括预测误差(常用的有均方误差、对数误差等)。而且节点不再是类别,是数值(预测值),那么怎么确定呢?有的是节点内样本均值,有的是最优化算出来的比如Xgboost。
CART回归树是假设树为二叉树,通过不断将特征进行分裂。比如当前树结点是基于第j个特征值进行分裂的,设该特征值小于s的样本划分为左子树,大于s的样本划分为右子树。
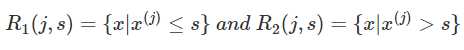
而CART回归树实质上就是在该特征维度对样本空间进行划分,而这种空间划分的优化是一种NP难问题,因此,在决策树模型中是使用启发式方法解决。典型CART回归树产生的目标函数为:
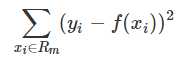
因此,当我们为了求解最优的切分特征j和最优的切分点s,就转化为求解这么一个目标函数:
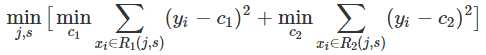
所以我们只要遍历所有特征的的所有切分点,就能找到最优的切分特征和切分点。最终得到一棵回归树。
原文:https://www.cnblogs.com/GumpYan/p/13641144.html