数据大家可以到官网去下载:https://tianchi.aliyun.com/competition/entrance/531830/information需要报名后才可以下载数据
赛题以预测用户贷款是否违约为任务,数据集报名后可见并可下载,该数据来自某信贷平台的贷款记录,总数据量超过120w,包含47列变量信息,其中15列为匿名变量。为了保证比赛的公平性,将会从中抽取80万条作为训练集,20万条作为测试集A,20万条作为测试集B,同时会对employmentTitle、purpose、postCode和title等信息进行脱敏。
| Field | Description |
|---|---|
| id | 为贷款清单分配的唯一信用证标识 |
| loanAmnt | 贷款金额 |
| term | 贷款期限(year) |
| interestRate | 贷款利率 |
| installment | 分期付款金额 |
| grade | 贷款等级 |
| subGrade | 贷款等级之子级 |
| employmentTitle | 就业职称 |
| employmentLength | 就业年限(年) |
| homeOwnership | 借款人在登记时提供的房屋所有权状况 |
| annualIncome | 年收入 |
| verificationStatus | 验证状态 |
| issueDate | 贷款发放的月份 |
| purpose | 借款人在贷款申请时的贷款用途类别 |
| postCode | 借款人在贷款申请中提供的邮政编码的前3位数字 |
| regionCode | 地区编码 |
| dti | 债务收入比 |
| delinquency_2years | 借款人过去2年信用档案中逾期30天以上的违约事件数 |
| ficoRangeLow | 借款人在贷款发放时的fico所属的下限范围 |
| ficoRangeHigh | 借款人在贷款发放时的fico所属的上限范围 |
| openAcc | 借款人信用档案中未结信用额度的数量 |
| pubRec | 贬损公共记录的数量 |
| pubRecBankruptcies | 公开记录清除的数量 |
| revolBal | 信贷周转余额合计 |
| revolUtil | 循环额度利用率,或借款人使用的相对于所有可用循环信贷的信贷金额 |
| totalAcc | 借款人信用档案中当前的信用额度总数 |
| initialListStatus | 贷款的初始列表状态 |
| applicationType | 表明贷款是个人申请还是与两个共同借款人的联合申请 |
| earliesCreditLine | 借款人最早报告的信用额度开立的月份 |
| title | 借款人提供的贷款名称 |
| policyCode | 公开可用的策略_代码=1新产品不公开可用的策略_代码=2 |
| n系列匿名特征 | 匿名特征n0-n14,为一些贷款人行为计数特征的处理 |
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns import datetime import warnings warnings.filterwarnings(‘ignore‘)
data_train = pd.read_csv(‘F:/python/阿里云金融风控-贷款违约预测/train.csv‘) data_test_a = pd.read_csv(‘F:/python/阿里云金融风控-贷款违约预测/testA.csv‘)
data_test_a.shape #(200000, 48) data_train.shape #(800000, 47) data_train.columns data_train.info() data_train.describe() data_train.head(3).append(data_train.tail(3))
print(f‘There are {data_train.isnull().any().sum()} columns in train dataset with missing values.‘) #There are 22 columns in train dataset with missing values. # nan可视化 missing = data_train.isnull().sum()/len(data_train) missing = missing[missing > 0] missing.sort_values(inplace=True) missing.plot.bar()
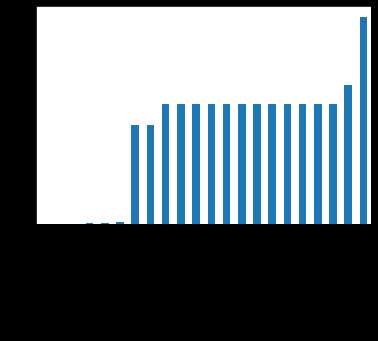
查看训练集测试集中特征属性只有一值的特征
one_value_fea = [col for col in data_train.columns if data_train[col].nunique() <= 1] one_value_fea_test = [col for col in data_test_a.columns if data_test_a[col].nunique() <= 1] print(one_value_fea,one_value_fea_test ) #[‘policyCode‘] [‘policyCode‘] data_train[‘policyCode‘].value_counts() #1.0 800000 #Name: policyCode, dtype: int64 #可以删除 data_train=data_train.drop([‘policyCode‘],axis=1) data_test_a=data_test_a.drop([‘policyCode‘],axis=1) print(data_train.shape,data_test_a.shape) data_train.columns,data_test_a.columns
data_train.info() numerical_fea = list(data_train.select_dtypes(exclude=[‘object‘]).columns) category_fea = list(filter(lambda x: x not in numerical_fea,list(data_train.columns)))
[‘id‘, ‘loanAmnt‘, ‘term‘, ‘interestRate‘, ‘installment‘, ‘employmentTitle‘, ‘homeOwnership‘, ‘annualIncome‘, ‘verificationStatus‘, ‘isDefault‘, ‘purpose‘, ‘postCode‘, ‘regionCode‘, ‘dti‘, ‘delinquency_2years‘, ‘ficoRangeLow‘, ‘ficoRangeHigh‘, ‘openAcc‘, ‘pubRec‘, ‘pubRecBankruptcies‘, ‘revolBal‘, ‘revolUtil‘, ‘totalAcc‘, ‘initialListStatus‘, ‘applicationType‘, ‘title‘, ‘n0‘, ‘n1‘, ‘n2‘, ‘n2.1‘, ‘n4‘, ‘n5‘, ‘n6‘, ‘n7‘, ‘n8‘, ‘n9‘, ‘n10‘, ‘n11‘, ‘n12‘, ‘n13‘, ‘n14‘]
[‘grade‘, ‘subGrade‘, ‘employmentLength‘, ‘issueDate‘, ‘earliesCreditLine‘]
数值型变量分析,数值型肯定是包括连续型变量和离散型变量的,找出来
#过滤数值型类别特征 def get_numerical_serial_fea(data,feas): ‘‘‘ 目的:划分数值型变量中的连续变量和分类变量 data:需要划分的数据集 feas:需要区分的特征的名称 返回:连续变量和分类变量 的list集合 ‘‘‘ numerical_serial_fea = [] numerical_noserial_fea = [] for fea in feas: temp = data[fea].nunique() if temp <= 10: numerical_noserial_fea.append(fea) continue numerical_serial_fea.append(fea) return numerical_serial_fea,numerical_noserial_fea numerical_serial_fea,numerical_noserial_fea = get_numerical_serial_fea(data_train,numerical_fea) numerical_serial_fea,numerical_noserial_fea
([‘id‘,
‘loanAmnt‘,
‘interestRate‘,
‘installment‘,
‘employmentTitle‘,
‘annualIncome‘,
‘purpose‘,
‘postCode‘,
‘regionCode‘,
‘dti‘,
‘delinquency_2years‘,
‘ficoRangeLow‘,
‘ficoRangeHigh‘,
‘openAcc‘,
‘pubRec‘,
‘pubRecBankruptcies‘,
‘revolBal‘,
‘revolUtil‘,
‘totalAcc‘,
‘title‘,
‘n0‘,
‘n1‘,
‘n2‘,
‘n2.1‘,
‘n4‘,
‘n5‘,
‘n6‘,
‘n7‘,
‘n8‘,
‘n9‘,
‘n10‘,
‘n13‘,
‘n14‘],
[‘term‘,
‘homeOwnership‘,
‘verificationStatus‘,
‘isDefault‘,
‘initialListStatus‘,
‘applicationType‘,
‘n11‘,
‘n12‘])
在仔细查看每个数值型的类别变量
原文:https://www.cnblogs.com/cgmcoding/p/13651921.html