Generative Adversarial Nets, 生成式对抗网络
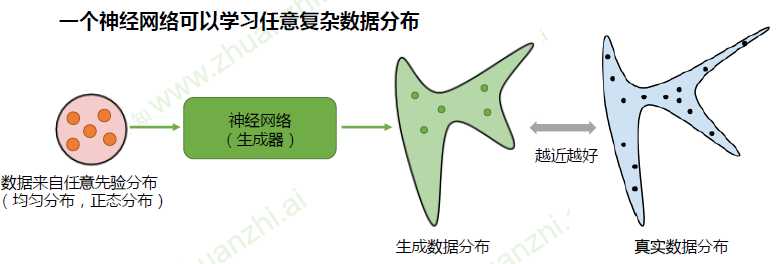
生成模型
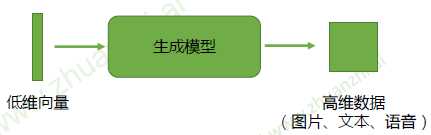
生成式对抗网络(GAN)的目的是训练这样一个生成模型,生成我们想要的数据
GAN框架
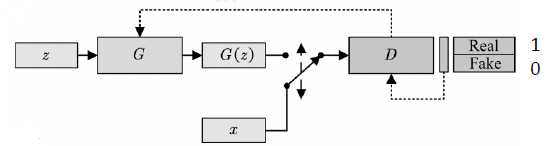
判别器(Discriminator):区分真实(real)样本和虚假(fake)样本。对于真实样本,尽可能给
出高的评分1;对于虚假数据,尽可能给出低个评分0
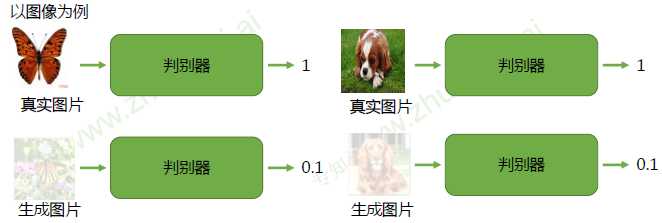
生成器(Generator):欺骗判别器。生成虚假数据,使得判别器D能够尽可能给出高的评分1

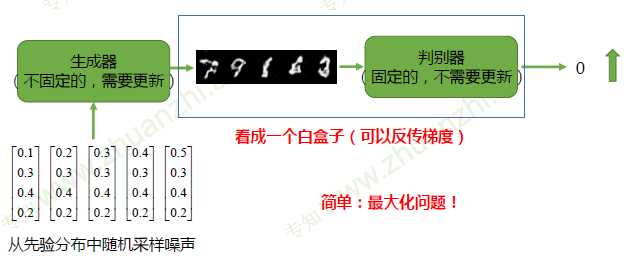
随机噪声z:从一个先验分布(人为定义,一般是均匀分布或者正态分布)中随机采样的向量(输入的向量维度越高,其生成图像的种类越多)
真实样本x:从数据库中采样的样本
合成样本G(z):生成模型G输出的样本
目标函数:
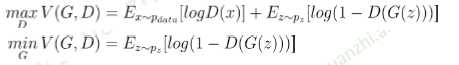
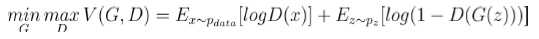
让真实样本的输出值尽可能大,同时让生成样本的输出值尽可能小
所以判别器D最大化的目标函数就是对于真实样本尽可能输出1,对于生成器的生成样本输出0
生成器G最小化目标函数就是让生成样本能够欺骗判别器,让其尽量输出1
训练算法
固定生成器G,训练判别器D区分真实图像与合成图像
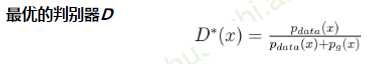

固定判别器D,训练生成器G欺骗判别器D
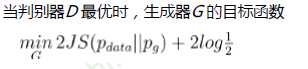
KL散度:一种衡量两个概率分布的匹配程度的指标
当\(P_1 = P_2\)时,KL散度为零
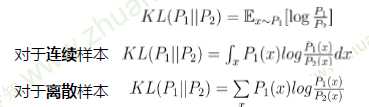
具有非负性,但存在不对称性(在优化的时候,会因为不对称性优化出不同的结果)
极大似然估计 等价于 最小化生成数据分布和真实分布的KL散度
JS散度
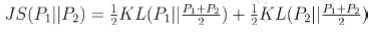
具有非负性,以及对称性
Conditional GAN, 条件生成式对抗网络
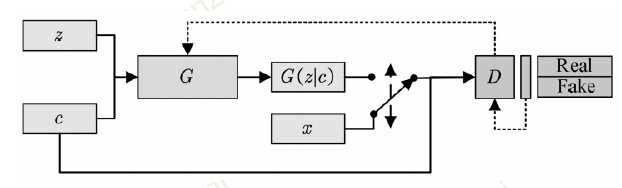
为了能够满足条件生成,所以需要添加一个class标签
对于生成器而言,没啥变化,只是增加了一个label输入
对于判别器而言,输入为图片以及对应标签;判别器不仅判断图片是否为真,同时也要判断时候和标签匹配
Deep Convlutional GAN, 深度卷积生成式对抗网络
原始GAN,使用全连接网络作为判别器和生成器
DCGAN,使用卷积神经网络作为判别器和生成器
通过大量的工程实践,经验性地提出一系列的网络结构和优化策略,来有效的建模图像数据
判别器
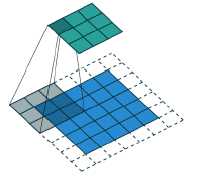
生成器:滑动反卷积

Wasserstein GAN with Weight Clipping/ Gradient Penalty
原始GAN存在的问题
JS散度
已知GAN网络的目标函数
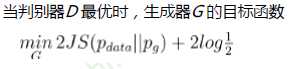
所以可以看到GAN网络的训练效果是和JS散度相关联的
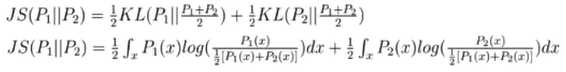
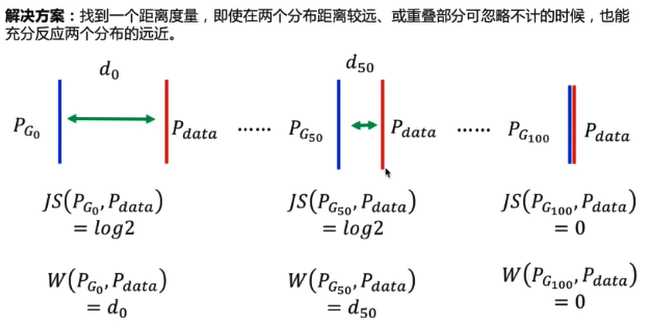
但\(P_{data}(x)\)与\(P_g(x)\)发生不重叠(或重叠部分可忽略)的可能性非常大,即\(P_1(x) != 0 and P_2(x)!=0\)这种情况发生概率很小
GAN:真实数据分布\(P_{data}\)和生成数据分布\(P_G\)是高维空间中的维度流形,它们重叠的区域可以忽略不记(能够提供梯度信息的数据可以忽略不记) == =》所以无论它们相距多少,其JS散度都是常数(仅当完全重合时,JS散度为零),导致生成器的梯度(近似)为零,造成梯度消失===》GAN优化困难
Wasserstein距离
\(W(P_1,P_2) = inf_{γ\sim\prod(P_1,P_2) E_{(x,y)\simγ}[||x-y||]}\)
\(\prod(P_1,P_2)\):P1和P2组合起来的所有可能的联合分布的集合
\(|| x - y ||\):样本x和y的距离
inf:所有可能的下界
假设对于P1和P2上的点x,y有一个联合分布γ;在这个联合分布上取一对点(x,y),计算他们的距离\(||x-y||\),然后通过很多的点,计算出它的期望;然后我们再遍历所有可能的联合分布,得到一个最小的距离,就是我们定义的W距离。
e.g
假设有两个离散的分布,每个分布只包含两个点(A、B和C、D),每个点的出现概率相等,横竖距离均为1
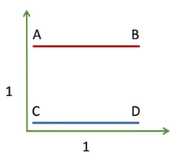
通过这个分布,可以计算出距离\(||x-y||\)
| 距离 | C | D |
|---|---|---|
| A | 1 | \(\sqrt{2}\) |
| B | \(\sqrt{2}\) | 1 |
下面讨论所有可能出现的联合分布形式,下面仅举例其中可能的两种
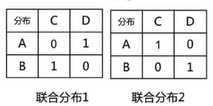
在联合分布1下,可以计算出期望\(2\sqrt2\)
同理,在联合分布2下,计算得出期望为2(可以得到是所有可能的联合分布中最小的期望值)
所以得到W距离为2
可以理解为:将分布P1移动到分布P2,已知彼此距离\(||x-y||\),选择一个合适的移动方案γ(联合分布),让走的路径最小,就是W距离。
但inf(穷举所有可能,取下界)项无法直接求解

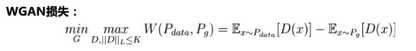
WGAN-GP
WGAN存在的问题
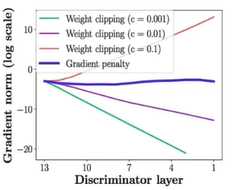
WGAN-GP:把Lipschitz限制作为一个正则项加到Wasserstein损失上,在优化GAN损失的同时,尽可能满足Lipschitz限制
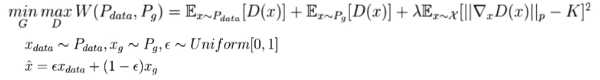
谱归一化层实现利普希茨连续
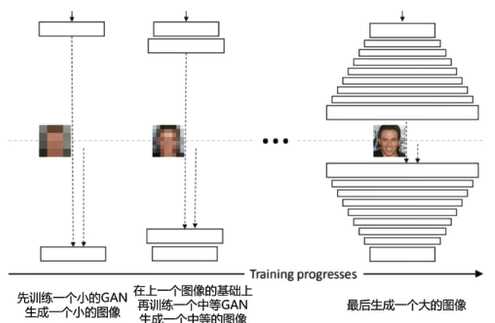
建模长距离依赖关系
建立一个长距离依赖关系
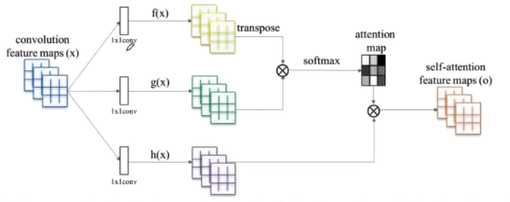
让最终的输出每一部分不仅仅是和对应的感受野相关,也和整体全局相关联
神经网络中,浅层卷积核提取Low-Level特征,深层卷积核提取High-Level特征
High-Level特征:分类、检测需要对图像深层理解等任务
Low-Level特征:保留更多图像细节
图像翻译任务:需要Low-Level和High-Level 特征
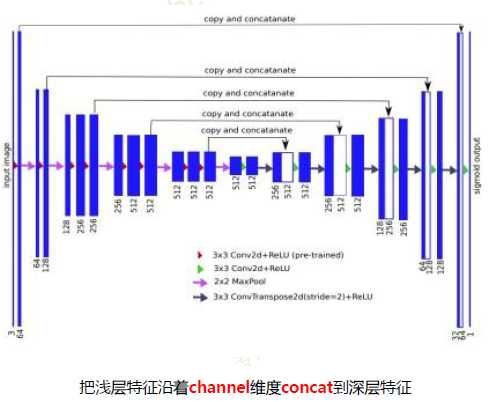
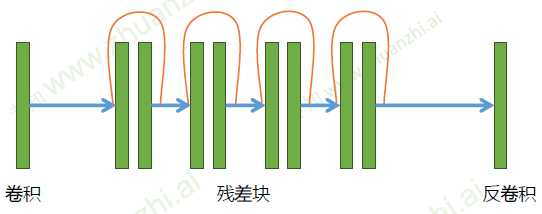
ResGenerator
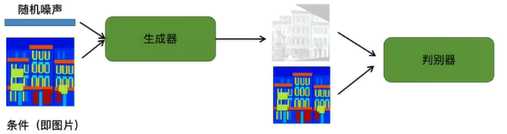
用cGAN实现图像翻译
首先输入轮廓和随机噪声,通过生成器生成建筑图像,再将输入和建筑图像输入到判别其中
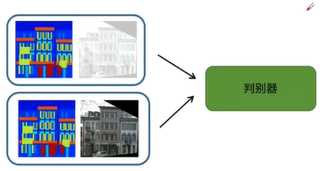
判别器进行判断,输出判别值
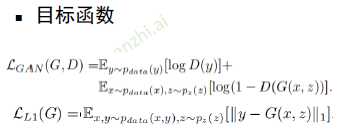
无须paired数据,学习图像翻译
有两组数组,但彼此之间并不是一一对应
因为没有很好的全局损失信息,可能会出现生成的结果不能保持对应的位置信息等
eg
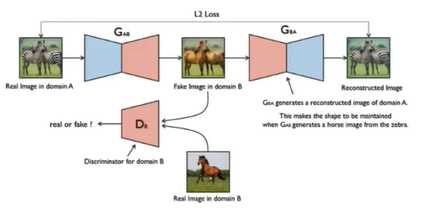
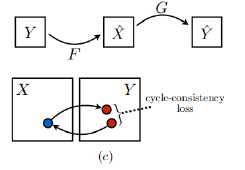
循环一致性损失
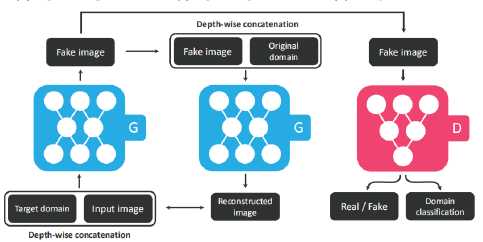
·对于输入图像:将生成图像重建回输入图像,应当让原始输入图像和重建的输入图像尽可能相似

同理,有
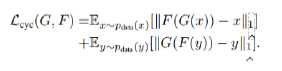
一个GAN,多种数据,任意变换
原文:https://www.cnblogs.com/hyzs1220/p/13658758.html