在php中有两套正则表达式,两者功能相似,一套是由PCRE,使用"preg_"为前缀命名的函数,一套是由POSIX拓展提供的,使用以"ereg_"命名的函数
| 函数名 | 功能 |
|---|---|
| preg_match() | 进行正则表达式匹配 |
| preg_match_all() | 进行全局正则表达式匹配 |
| preg_replace() | 执行正则表达式的搜索和替换 |
| preg_split() | 用正则表达式分割字符串 |
| preg_grep() | 返回与模式匹配的数组单元 |
| preg_replace_callback | 用回调函数执行正则表达式的搜索和替换 |
2.1 定界符
2.2 原子
2.3 元字符
2.4 模式修正符
正则表达式作为一个匹配的模版,是由原子(普通字符,例如字符a到z)、特殊字符(元字符,例如*、+和?等)、以及模式修正符三部分组成的文字模式。
一个最简单正则表达式至少包含一个原子。
将下面的正则表达式拆分如下:
‘/<a.*?(?:|\\t|\\r|\\n)?href=[\"]?(.+?)[\"]?(?:(?:|\\t|\\r|\\n)+.*?)?>(.+?)<\/a.*?>/sim‘
定界符:两个斜线”/”。
原子用到了< a href = ‘ “ / >等普通字符和\t \r \n等转义字符
元字符使用了 [] () | . ? * + 等具有特殊含义的字符
用到了模式修正符是在定界符最后一个斜线之后的三个字符: s i m
比如
<?php
preg_match("/<a.*?(?:|\\t|\\r|\\n)?href=[\"]?(.+?)[\"]?(?:(?:|\\t|\\r|\\n)+.*?)?>(.+?)<\/a.*?>/sim","<div><a href=‘http://www.baidu.com‘>百度</a></div><a href=‘http://www.baidu.com‘>百度2</a>",$info);
var_dump($info);
?>
输出
array(3) {
[0]=>
string(41) "<a href=‘http://www.baidu.com‘>百度</a>"
[1]=>
string(1) "‘"
[2]=>
string(6) "百度"
}
这里只输出了一个,我们使用preg_match_all输出
array(3) {
[0]=>
array(2) {
[0]=>
string(41) "<a href=‘http://www.baidu.com‘>百度</a>"
[1]=>
string(42) "<a href=‘http://www.baidu.com‘>百度2</a>"
}
[1]=>
array(2) {
[0]=>
string(1) "‘"
[1]=>
string(1) "‘"
}
[2]=>
array(2) {
[0]=>
string(6) "百度"
[1]=>
string(7) "百度2"
}
}
2.1定界符
在程序语言中,使用与Perl兼容的正则表达式,通常都需要将模式表达式放入定界符之间,如“/”。
作为定界符常使用反斜线“/”,如“/apple/”。用户只要把需要匹配的模式内容放入定界符之间即可。作为定界的字符也不仅仅局限于“/”。除了字母、数字和斜线“\”以外的任何字符都可以作为定界符,像 ‘#’、’|’、’!’ 等都可以的。
/<\/\w+>/ --使用反斜线作为定界符合法
|(\d{3})-\d+|Sm --使用竖线”|”作为定界符合法
!^(?i)php[34]! --使用竖线”!”作为定界符合法
{^\s+(\s+)?$} --使用竖线”}”作为定界符合法
/href=‘(.*)’ --非法定界符,缺少结束定界符
1-\d3-\d3-\d4| --非法定界符,缺少其实定界符
<?php
preg_match("/apple/", "apple test",$info);
var_dump($info)
?>
输出
array(1) {
[0]=>
string(5) "apple"
}
2.2原子
原子是正则表达式的最基本的组成单元,而且在每个模式中最少要少包含一个原子。原子是由所有那些未显示指定为元字符的打印和非打印字符组成,具体分为5类。
1. 普通字符作为原子: 如 az、AZ、0~9 等
2. 一些特殊字符和转义后元字符作为原子:
所有标点符号,但语句特殊意义的符号需要转义后才可作为原子,如:\” \’ * + ? . 等
3. 一些非打印字符作为原子: 如:\f \n \r \t \v \cx
4. 使用“通用字符类型”作为原子:如:\d \D \w \W \s \S。
5. 自定义原子表([])作为原子:如:’/[apj]sp/’ ’/[^apj]sp/’
<?php
preg_match_all("/[0-9a-zA-Z]/", "AZ",$info);
var_dump($info)
?>
输出
array(1) {
[0]=>
array(2) {
[0]=>
string(1) "A"
[1]=>
string(1) "Z"
}
}
正则表达式中常用的非打印字符
| 字符 | 含义 |
|---|---|
| \cx | 匹配由x指明的控制字符。如\cM匹配一个Control-M或回车符。x的值必须为AZ或az之一 |
| \f | 匹配一个换页符。等价于 \x0c或\cL |
| \n | 匹配一个换行符。等价于 \x0a或\cJ |
| \r | 匹配一个回车符。等价于 \x0d或\cM |
| \t | 匹配一个制表符。等价于 \x09或\cI |
| \v | 匹配一个垂直制表符。等价于 \x0b或\cK |
正则表达式中常用的“通用字符类型”
| 原子字符 | 含义 |
|---|---|
| \d | 匹配任意一个十进制数字,等价于[0-9] |
| \D | 匹配任意一个除十进制数字以外的字符,等价于[^0-9] |
| \s | 匹配任意一个空白符,等价于[\f\n\r\t\v] |
| \S | 匹配除空白符以外任何字符,等价于[^\f\n\r\t\v] |
| \w | 匹配任意一个数字、字母或下画线,等价于[0-9a-zA-Z_] |
| \W | 匹配一个除数字、字母或下画线以外的任意一个字符,等价于[^0-9a-zA-Z_] |
2.3元字符
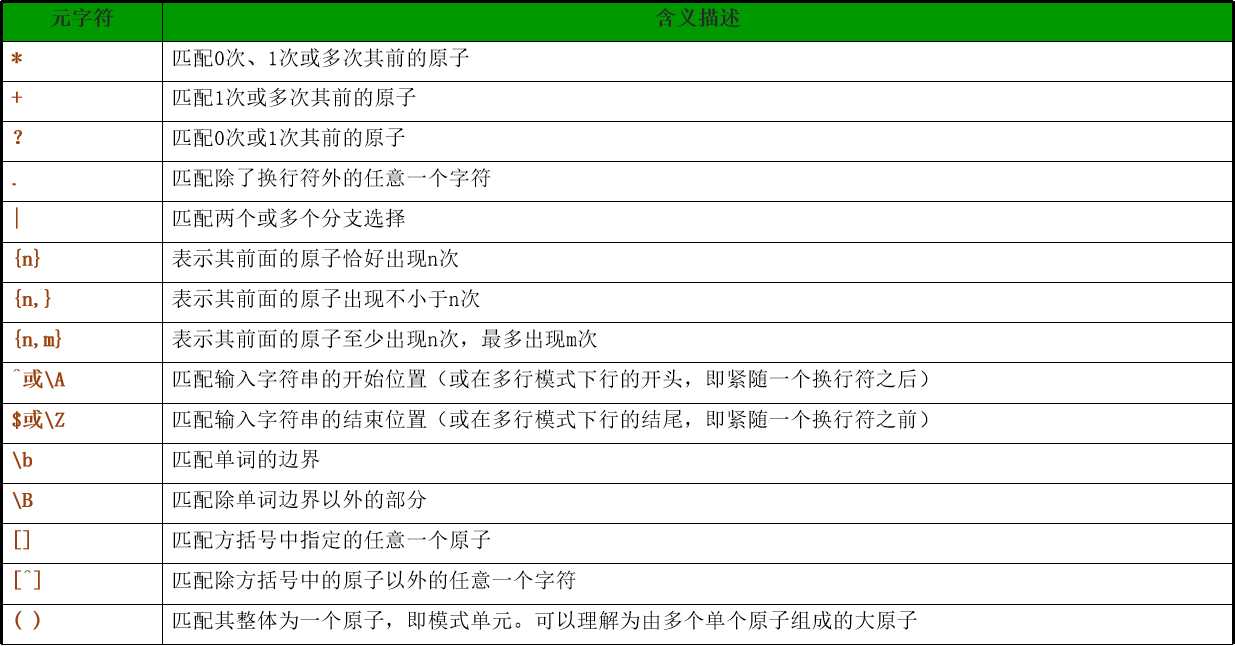
字符串边界限制
在某些情况下,需要对匹配范围进行限定,以获得更准确的匹配结果。
^和$分别指定字符串的开始和结束。
例如,在字符串“Tom and Jerry chased each other in the house until tom’s uncel come in”中元字符“^”或“\A” 置于字符串的开始确保模式匹配出现在字符串首端;
/^Tom/
元字符“$”或“\Z” 置于字符串的结束,确保模式匹配出现字符串尾端。
/in$/
如果不加边界限制元字符,将获得更多的匹配结果。
/^Tom$/精确匹配 /Tom/模糊匹配
<?php
preg_match_all("^Tom$", "Tom and Jerry chased each other in the house until tom’s uncel come in",$info);
var_dump($info)
?>
输出
array(1) {
[0]=>
array(0) {
}
}
为什么匹配不到呢,因为必须是以Tom开始和结束的,只有这样才行
<?php
preg_match_all("/^Tom$/", "Tom",$info);
var_dump($info)
?>
单词边界限制
在使用各种编辑软件的查找功能时,可以通过选择“按单词查找”获得更准确的结果。正则表达式中也提供类似的功能。
例如:在字符串“This island is a beautiful land”中
元字符“\b”对单词的边界进行匹配;
/\bis\b/ 匹配单词“is”,不匹配“This”和“island”。
/\bis 匹配单词“is”和“island”中的“is”,不匹配“This”
元字符“\B”对除单词边界以外的部分进行匹配。
/\Bis\B/ 将明确的指示不与单词的左、右边界匹配,只匹配单词的内部。所以在这个例子中没有结果。
/\Bis 匹配单词“This”中的“is”
重复匹配
正则表达式中有一些用于重复匹配某些原子的元字符:“?”、“”、“+”。他们主要的区别是重复匹配的次数不同。
元字符“?”:表示0次或1次匹配紧接在其前的原子。
例如:/colou?r/匹配“colour”或“color”。
元字符“”:表示0次、1次或多次匹配紧接在其前的原子。
例如:/zo*/可以匹配z、zoo
元字符“+”:表示1次或多次匹配紧接在其前的原子。
例如:/go+gle/匹配“gogle”、“google”或“gooogle”等中间含有多个o的字符串。
原子表 -方括号表达式
原子表”[]”中存放一组原子,彼此地位平等,且仅匹配其中的一个原子。如果想匹配一个 ”a” 或 ”e” 使用 [ae]。
例如: Pr[ae]y 匹配 ”Pray” 或者 ”Prey ”。
原子表 ”[^]” 或者称为排除原子表,匹配除表内原子外的任意一个字符。
例如:/p[^u]/匹配“part”中的“pa”,但无法匹配“computer”中的“pu”因为“u”在匹配中被排除。
原子表“[-]”用于连接一组按ASCII码顺序排列的原子,简化书写。
例如:/x[0123456789]/可以写成x[0-9],用来匹配一个由 “x” 字母与一个数字组成的字符串。
例如:
/[a-zA-Z]/匹配所有大小写字母
/^[a-z][0-9]$/匹配比如“z2”、 “t6” 、“g7”
/0[xX][0-9a-fA-F]/匹配一个简单的十六进制数字,如“0x9”。
/[^0-9a-zA-Z_]/匹配除英文字母、数字和下划线以外任何一个字符,其等价于\W。
/0?[ xX][0-9a-fA-F]+/匹配十六进制数字,可以匹配“0x9B3C”或者“X800”等。
/<[A-Za-z][A-Za-z0-9]*>/可以匹配“<P>”、“<hl>”或“<Body>”等HTML标签,并且不严格的控制大小写
模式选择符
元字符“|”又称模式选择符。在正则表达式中匹配两个或更多的选择之一。
例如:
在字符串“There are many apples and pears.”中, /apple|pear/在第一次运行时匹配“apple”;
再次运行时匹配“ pear”。也可以继续增加选项,如: /apple|pear|banana|lemon/
模式单元
元字符“()”将其中的正则表达式变为原子(或称模式单元)使用。与数学表达式中的括号类似,“()”可以做一个单元被单独使用。
例如:
/(Dog)+/匹配的“Dog”、“DogDog”、“DogDogDog”,因为紧接着“+”前的原子是元字符“()”括起来的字符串“Dog”。
/You (very )+ old/匹配“You very old”、“You very very old”
/Hello (world|earth)/匹配“Hello world”、“Hello earth”
一个模式单元中的表达式将被优先匹配或运算。
重新使用的模式单元*
系统自动将模式单元“()”中的匹配依次存储起来,在需要时可以用“\1”、“\2”、“\3”的形式进行引用。当正则表达式包含有相同的模式单元时,这种方法非常便于对其进行管理。注意使用时需要写成“\1”、“\2”
例如:
/^\d{2}([\W])\d{2}\1\d{4}$/匹配“12-31-2006”、“09/27/1996”、“86 01 4321”等字符串。但上述正则表达式不匹配“12/34-5678”的格式。这是因为模式“[\W]”的结果“/”已经被存储。下个位置“\1”引用时,其匹配模式也是字符“/”。
当不需要存储匹配结果时使用非存储模式单元“(?:)”
例如/(?:a|b|c)(D|E|F)\1g/ 将匹配“aEEg”。在一些正则表达式中,使用非存储模式单元是必要的。否则,需要改变其后引用的顺序。上例还可以写成/(a|b|c)(C|E|F)\2g/
比如说:
<?php
preg_match("/^\d{2}([\W])\d{2}\\1\d{4}$/", "12-31-2006",$info);
var_dump($info);
?>
输出
array(2) { [0]=> string(10) "12-31-2006" [1]=> string(1) "-" }
这里就是[0-9]{2} ([^0-9a-zA-Z])[0-9]{2} ([^0-9a-zA-Z]) [0-9]{4},这里的\1是重复()里面的内容\1就是转义,如果想用第二个就\2就行了
模式匹配的优先级
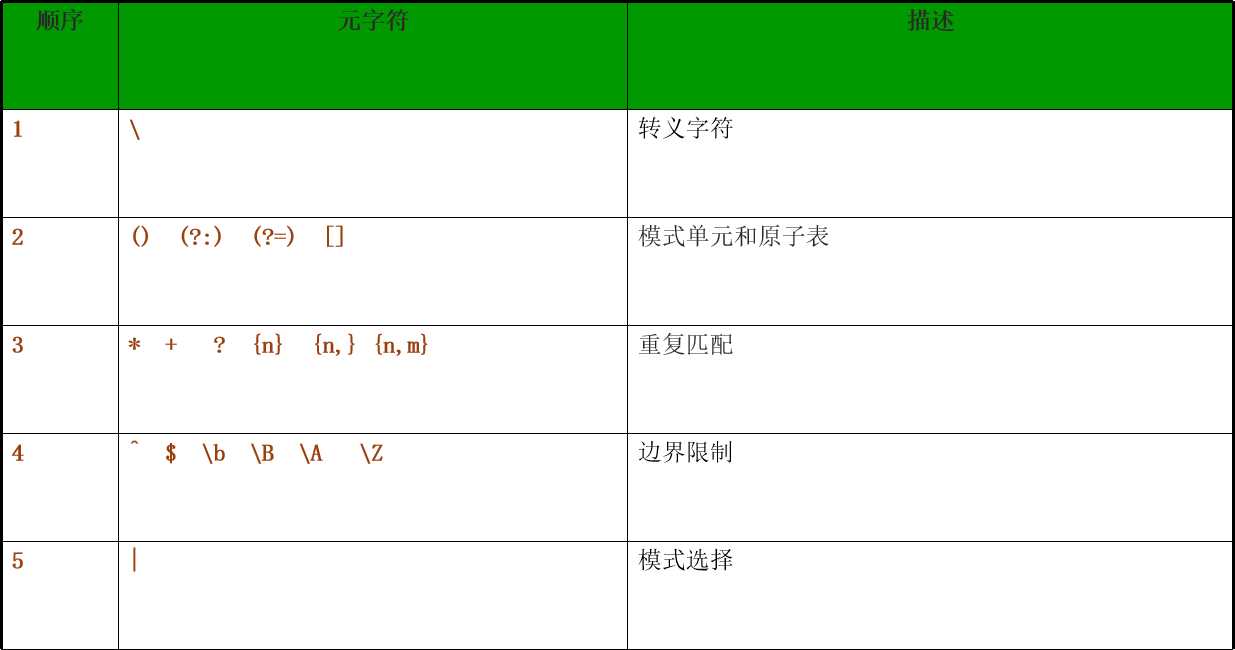
模式修正符

3.1 子符串的匹配与查找函数
1.函数preg_match() --执行一个正则表达式匹配
int preg_match(string $pattern, string $subject[,array &$matches])
搜索subject与pattern给定的正则表达式的一个匹配.
2.函数preg_match_all() --执行全局正则表达式匹配
int preg_match_all(string $pattern ,string $subject ,array &$matches [, int $flags])
搜索subject中所有匹配pattern给定正则表达式 的匹配结果并且将它们以flag指定顺序输出到matches中. 参数flags是指定matches的数组格式。
3.函数preg_grep() --返回匹配模式的数组条目
array preg_grep ( string $pattern , array $input [, int $flags = 0 ] )
返回给定数组input中与模式pattern 匹配的元素组成的数组。
4.其它子串处理函数:strstr()、strpos()、strrpos()、substr()
<?php
/**
用于获取URL中的文件名部分
@param string $url 任何一个URL格式的字符串
@return string URL中的文件名称部分
*/
function getFileName($url) {
//获取URL字符串中最后一个“/”出现的位置,再加1则为文件名开始的位置
$location = strrpos($url, "/")+1;
//获取在URL中从$location位置取到结尾的子字符串
$fileName = substr($url, $location);
//返回获取到的文件名称
return $fileName;
}
//获取网页文件名index.php
echo getFileName("https://www.cnblogs.com");
输出
www.cnblogs.com
为什么$location要+1呢因为strrpos是以0开始的而substr是以1开始的所以要加一获取位置
3.2 字符串的替换函数
preg_replace —执行一个正则表达式的搜索和替换
mixed preg_replace ( mixed $pattern , mixed $replacement,mixed $subject [,int $limit = -1])
搜索subject中匹配pattern的部分, 以replacement进行替换.
实例:
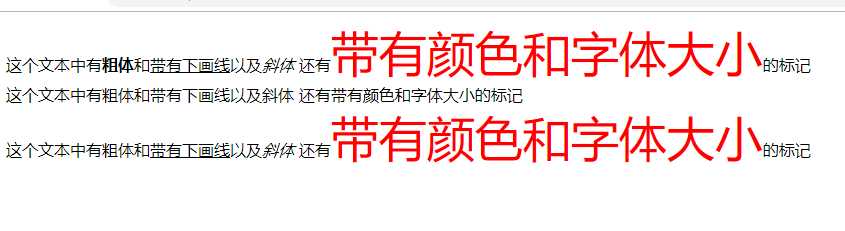
<?php
//可以匹配所有HTML标记的开始和结束的正则表达式
$pattern = "/<[\/\!]*?[^<>]*?>/is";
//声明一个带有多个HTML标记的文本
$text = "这个文本中有<b>粗体</b>和<u>带有下画线</u>以及<i>斜体</i>
还有<font color=‘red‘ size=‘7‘>带有颜色和字体大小</font>的标记";
echo "$text";
echo "<br>";
//将所有HTML标记替换为空,即删除所有HTML标记
echo preg_replace($pattern, "", $text);
echo "<br>";
//通过第四个参数传入数字2,替换前两个HTML标记
echo preg_replace($pattern, "", $text, 2);
输出
<?php
$pattern = "/(\d{2})\/(\d{2})\/(\d{4})/"; //日期格式的正则表达式
$text="今年国庆节放假日期为10/01/2012到10/07/2012共7天。"; //带有两个日期格式的字串
echo preg_replace($pattern, "\\3-\\1-\\2", $text); //将日期替换为以“-”分隔的格式
echo preg_replace($pattern, "\${3}-\${1}-\${2}",$text); //将“\\1”改为“\${1}”的形式
输出
今年国庆节放假日期为2012-10-01到2012-10-07共7天。今年国庆节放假日期为2012-10-01到2012-10-07共7天。
<?php
//元音字符数组
$vowels = array("a", "e", "i", "o", "u", "A", "E", "I", "O", "U");
//将第三个参数中的字符串,搜索到的数组中的元素值都被替换为空,区分大写小替换
echo str_replace($vowels, "", "Hello World of PHP"); //输出: Hll Wrld f PHP
//元音字符数组
$vowels = array("a", "e", "i", "o", "u");
//将第三个参数中的字符串,搜索到的数组中的元素值都被替换为空,不区分大写小替换
echo str_ireplace($vowels, "", "HELLO WORLD OF PHP"); //输出:HLL WRLD F PHP
<?php
//元音字符数组
$vowels = array("a", "e", "i", "o", "u", "A", "E", "I", "O", "U");
//将第三个参数中的字符串,搜索到的数组中的元素值都被替换为空,区分大写小替换
echo str_replace($vowels, "", "Hello World of PHP"); //输出: Hll Wrld f PHP
//元音字符数组
$vowels = array("a", "e", "i", "o", "u");
//将第三个参数中的字符串,搜索到的数组中的元素值都被替换为空,不区分大写小替换
echo str_ireplace($vowels, "", "HELLO WORLD OF PHP"); //输出:HLL WRLD F PHP
3.3 字符串的分割与连接
preg_split — 通过一个正则表达式分隔字符串
array preg_split ( string $pattern , string $subject [, int $limit = -1 [, int $flags = 0 ]] )
通过一个正则表达式$pattern分隔给定字符串$subject。其中$limit是最大替换个数。
flags可以是任何下面标记的组合
PREG_SPLIT_NO_EMPTY:返回分隔后的非空部分
PREG_SPLIT_DELIM_CAPTURE:用于分隔的模式中的括号表达式将被捕获并返回.
PREG_SPLIT_OFFSET_CAPTURE:返回附加字符串偏移量
<?php
//按任意数量的空格和逗号分隔字符串,其中包含" ", \r, \t, \n and \f
$keywords = preg_split ("/[\s,]+/", "hypertext language, programming");
print_r($keywords);
//分割后输出Array ( [0] => hypertext [1] => language [2] => programming )
//将字符串分割成字符
$chars = preg_split(‘//‘, "lamp", -1, PREG_SPLIT_NO_EMPTY);
print_r($chars); //分割后输出Array ( [0] => l [1] => a [2] => m [3] => p )
//将字符串分割为匹配项及其偏移量
$chars = preg_split(‘/ /‘,‘hypertext language programming‘, -1,
PREG_SPLIT_OFFSET_CAPTURE);
print_r($chars);
/* 分割后输出:
Array ( [0] => Array ( [0] => hypertext [1] => 0 )
[1] => Array ( [0] => language [1] => 10 )
[2] => Array ( [0] => programming [1] => 19 ) ) */
分割也可以用exlode
<?php
var_dump(explode(" ", "‘hypertext language programming‘"));
?>
输出
array(3) {
[0]=>
string(10) "‘hypertext"
[1]=>
string(8) "language"
[2]=>
string(12) "programming‘"
}
原文:https://www.cnblogs.com/yicunyiye/p/13660894.html