Python中一切皆对象, 对象本质上就是一个存储数据的内存块, 有时候, 我们需要将内存块数据保存到硬盘上, 或者通过网络传输到其他的计算机上. 这时候, 就需要对象的序列化和反序列化, 对象的序列化机制广泛运用到分布式, 并行系统上
序列化指的是: 将对象转化成串行化数据形式, 存储到硬盘或通过网络传输到其他地方. 反序列化指的是相反的过程, 将读取到的串行化数据转化成对象. 我们可以通过pickle模块中的函数, 实现序列化和反序列化操作
序列化我们使用:
pickle.dump(obj,file) obj就是要被序列化的对象, file指的是存储的文件
pickle.load(file) 从file中读取数据, 反序列化成对象
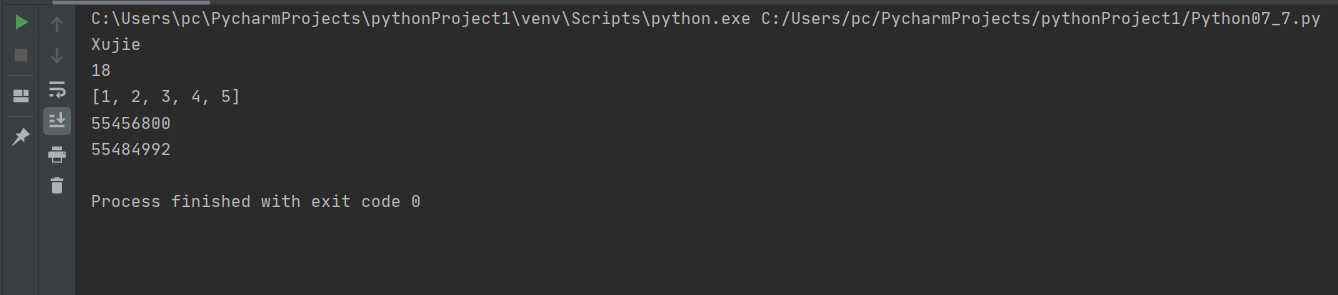
1 import pickle 2 3 a1 = ‘Xujie‘ 4 a2 = ‘18‘ 5 a3 = [1,2,3,4,5] 6 7 with open(‘g.bat‘,‘wb‘) as f: 8 pickle.dump(a1,f) 9 pickle.dump(a2,f) 10 pickle.dump(a3,f) 11 12 with open(‘g.bat‘,‘rb‘) as f: 13 b1 = pickle.load(f) 14 b2 = pickle.load(f) 15 b3 = pickle.load(f) 16 print(b1) 17 print(b2) 18 print(b3) 19 print(id(a1)) 20 print(id(b1))
原文:https://www.cnblogs.com/xujie-0528/p/13689543.html