对于Bug的处理是每一位开发者都必须面对的问题,该处理主要分为四个步骤:知晓故障——定位故障——分析故障——修复故障(打补丁)。人工修复bug基本上就是人工编写代码补丁并检验补丁正确性的过程。在实际应用程序中bug往往是比较难以发现的,因此对于程序的修复也遇到了一系列问题。

如上图所示,程序是越来越复杂的,修复工作对于开发人员的技术有很高的要求。在修复的过程中会消耗大量的时间和人力成本;与此同时补丁的质量问题以及程序员对于同一个bug不同的修复方式也带来了一系列问题。
测试用例是一系列人工编写的代码,能够被自动工具读取,用于描述软件行为。
测试驱动的程序修复流程如下:
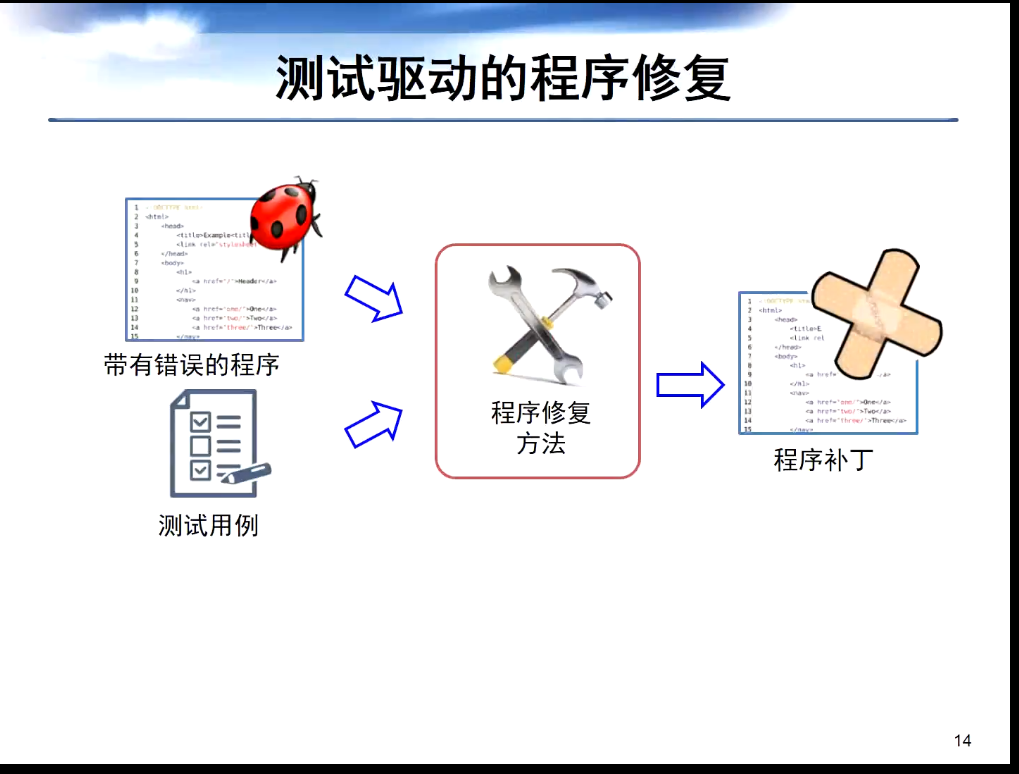
可以看到我们将带有错误的程序和测试用例作为输入传给程序修复方法,然后程序修复方法生成程序补丁。
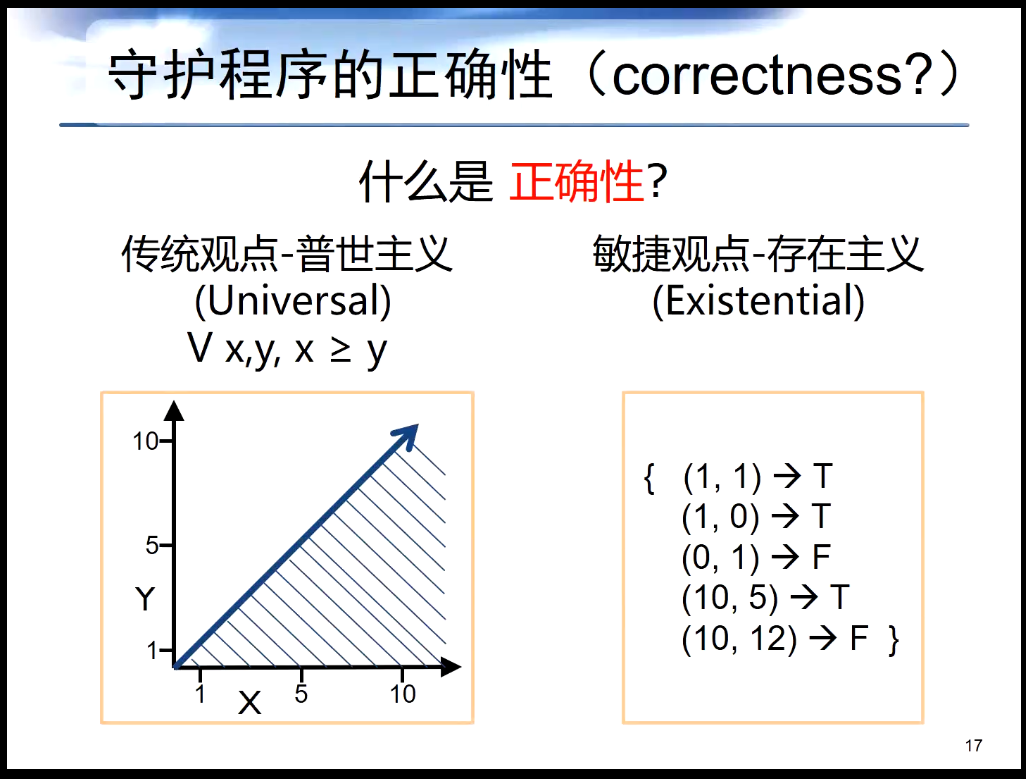
如下图所示,正确性在这里为两种,第一种是传统观点上的普世主义(Universal),普世主义认为万物都可以用表达式表达出来,但是在实际应用中我们发现很多事情很难用表达式表达出来,因此又提出了一个新的哲学流派即敏捷观点的存在主义(Existential),存在主义衍生出了敏捷观点。一定程度上我们可以通过测试用例描述整体的图形(左边)
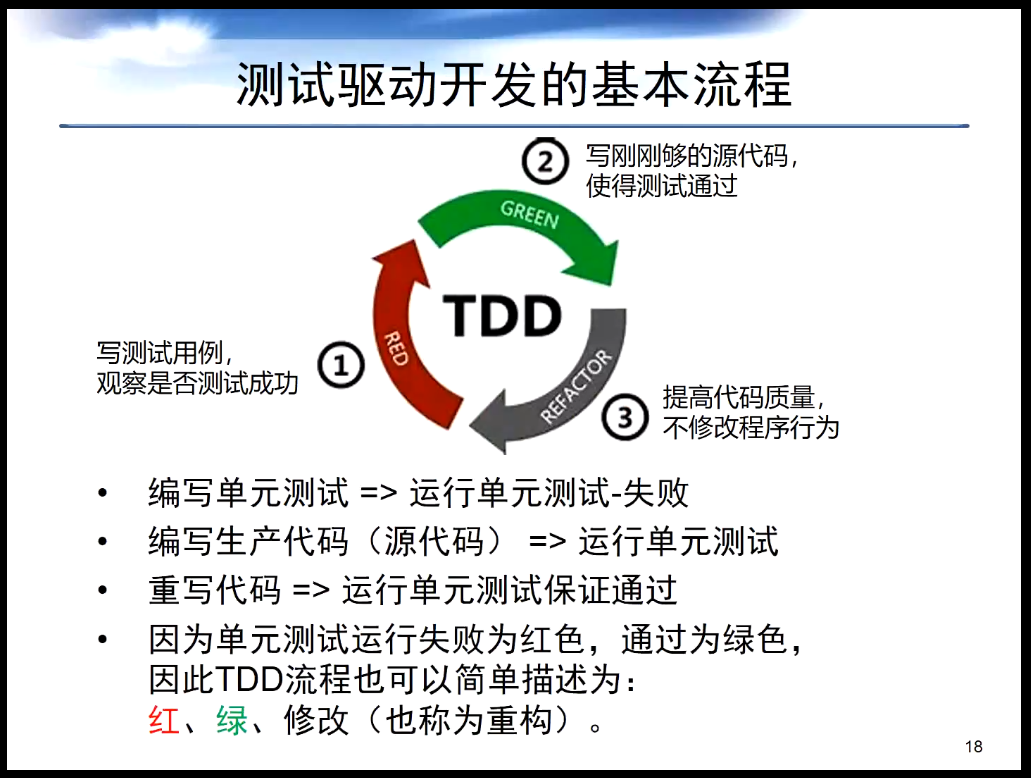
如图所示,测试驱动开发(TDD)不要求程序员一定了解开发的接口以及它本身的功能,而是通过三个迭代的步骤去解决这个问题。第一步是写测试用例并观察是否测试成功,第二部是写能够通过测试用例的代码,第三步是在不修改程序行为的前提下提高代码质量,接下来再返回前面的第一步继续进行迭代。TDD流程也可以简单描述为红、绿、改。
测试驱动开发在国际国内的工业界已经广泛接受和应用,但仍然存在一些挑战:
目标:精准和高效的生成代码补丁,以通过测试用例
现有方法基于尝试并验证的策略,补丁的检查依赖于多次测试用例执行。算法精度低,时间消耗高,难以用于真实程序。
2012年正式提出的修复方法GenProg就是将程序转化为AST,通过某些技术将AST变化并将变化后的结果转化成代码,它是基于演化计算对AST进行转换。GenProg方法消耗的时间成本可能非常大,因此它的实际应用并不乐观。
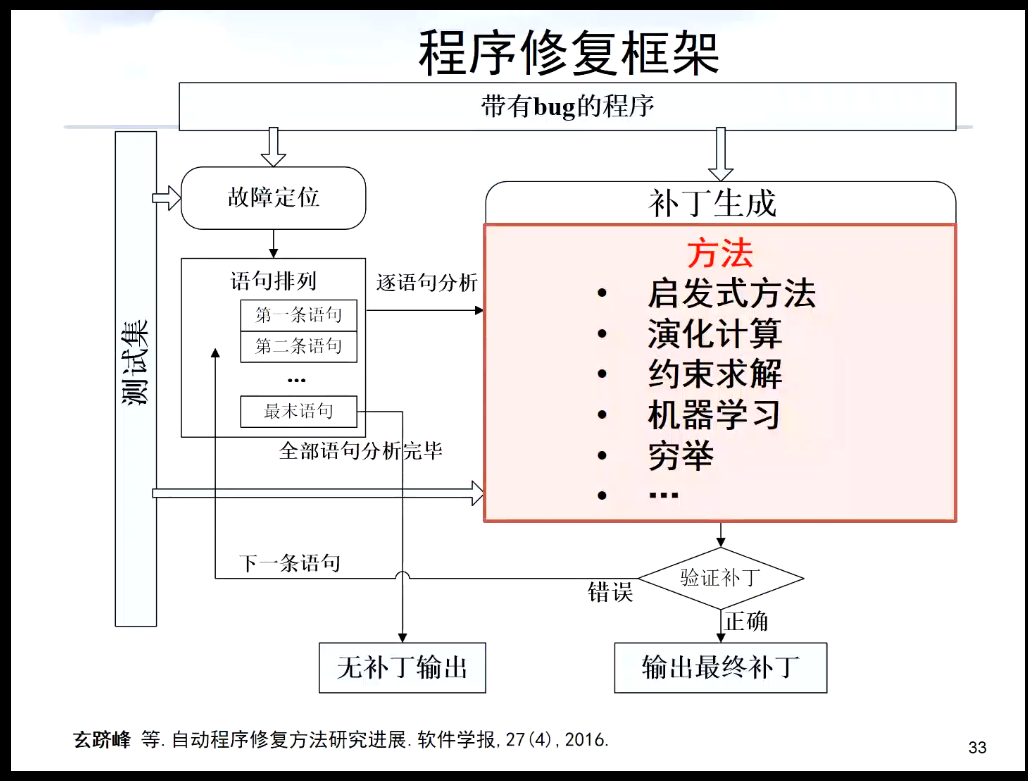
玄老师等人在2016年发表的《自动程序修复方法研究进展》中归纳总结了当时一些常用的补丁生成方法,其中有:
方法:从程序执行到代码补丁推断的自动转换
主要技术
应用:玄老师在他2017年有关Nopol修复工具的论文中使用了以上两个技术。其中补丁的输入为动态上下文编码(将面向对象语义编码成动态值);补丁的输出为自动的输出推断(动态推测补丁的运行时数值);最后将补丁生成转换为约束求解,合成补丁。
Nopol使用了天使修复点定位(Angelic fix localization)技术,为条件语句预估值。为了提高算法精度,将被修复程序编码为约束求解问题(SMT),一次求解,避免多次尝试以降低时间消耗。与此同时,针对面向对象程序,收集运行时(runtime)面向对象域和方法返回值,作为程序补丁的一部分(包括收集对象是否初始化以及一些可以取得的方法值,如string.length()等)
使用基础约束和功能约束等将所有前面得到的输入转换成逻辑表达式的形式 ,这样就能得到一大堆逻辑不等式,对这些不等式进行求解,得到的结果再转换成源代码,就生成了补丁。
工具生成的补丁往往可读性很差,不便于后续开发人员的开发。
崩溃(Crash)是一种严重的故障,指程序异常中断。也就是开发者预料之外的故障。
堆栈迹(Stack Trace)指的是程序崩溃后报出的错误日志。包括程序的异常类型,函数调用顺序以及异常位置。
崩溃定位(Crash Localization)需要耗费程序员大量的精力,为了解决崩溃定位问题,传统上尝试将崩溃代码转换为代码位置推荐,输出具体的代码行转换为输出代码行序列。即便如此实际应用中崩溃代码的定位还是很困难,玄老师转换了一下思路,将错误的自动定位转化成了错误的自动分离,问题就变成了研究引发崩溃的源代码是否被记录在stack trace中了,这样就将定位问题转化为预测问题(二元分类问题)。
推断修复受限于约束求解工具的能力,不易应用。为了解决这个问题,玄老师提出了一系列解决办法,如下图所示:
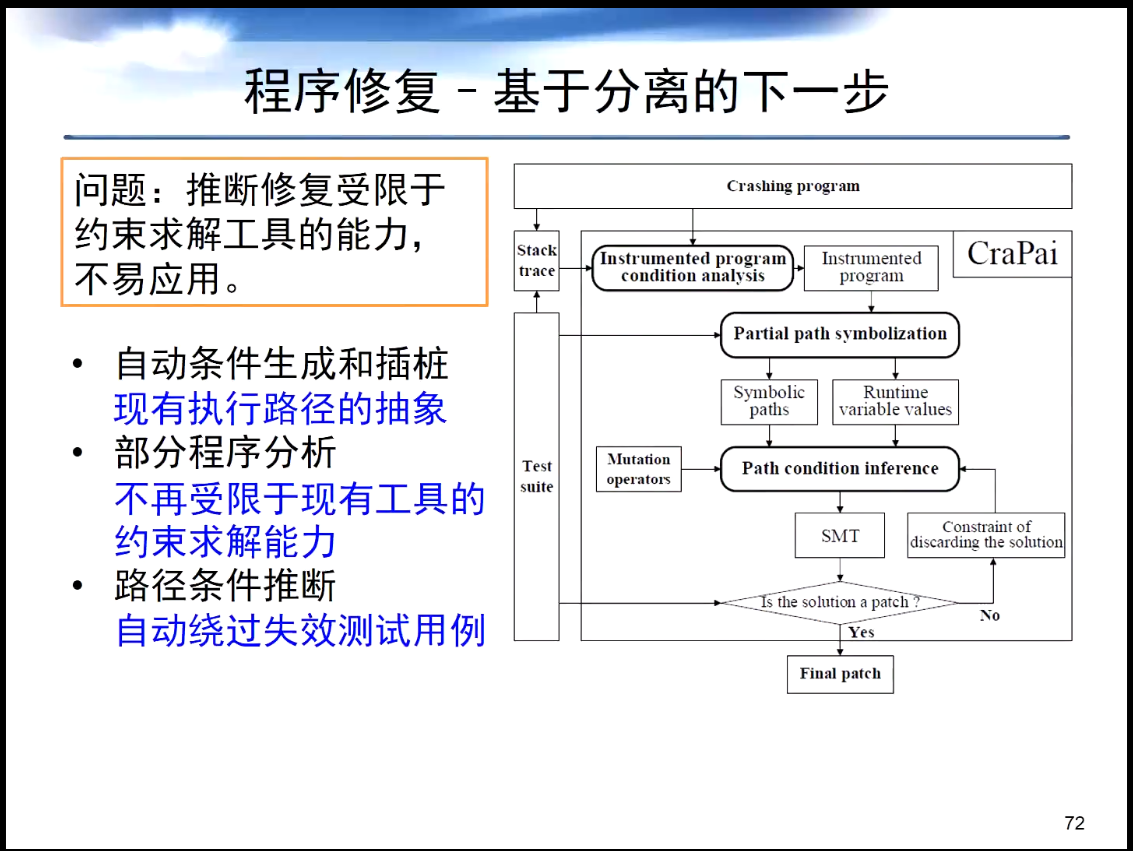
测试用例的冲突和冗余:通过自动化重构技术将复杂的测试用例转化为简单的测试用例以剔除噪声。
测试数据增强及优化:模糊测试结合符号执行,如何混合两种测试方法,提升精度和效率,玄老师提出了面向二进制代码的基于概率路径排序的混合模糊测试方法。
原文:https://www.cnblogs.com/crossain/p/13693549.html