在分组聚合的split-apply-combine过程中,apply是核心。Python 本身有高阶函数 apply() 来实现它
自定义聚合方式:aggregate(),或agg()
之前的聚合方式,所有列只能应用一个相同的聚合函数
聚合参数是列表
对数据每列应用多个相同的聚合函数
聚合参数是字典
对数据的每列应用一个或多个不同的聚合函数
聚合参数是自定义函数
对数据进行一些复杂的操作
agg 方法将一个函数使用在一个数列上,然后返回一个标量的值。也就是说agg每次传入的是一列数据,对其聚合后返回标量
自定义聚合方式可以:
每个列应用不同的聚合方式
一个列应用多个聚合方式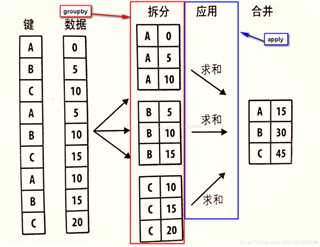
df = pd.DataFrame({
‘name‘: [‘张三‘,‘李四‘,‘王五‘,‘李四‘,‘王五‘,‘王五‘,‘赵六‘],
‘chinese‘: [18, 53, 67, 63, 59, 70, 94],
‘math‘: [82, 63, 41, 59, 46, 39, 58],
‘english‘: [68, 52, 80, 86, 60, 98, 64],
‘test‘: [‘一‘,‘一‘,‘一‘,‘二‘,‘二‘,‘三‘,‘一‘]
})
# 使用自定义聚合方式实现
df.groupby(‘name‘).agg(sum)
#聚合参数是列表
df.groupby(‘name‘).agg([sum, ‘mean‘, np.min]) # 列表参数函数可以有多种不同写法:直接写函数名(容易出错),函数名写成字符串,ndarray数组函数
# 将聚合列索引改为自定义方式,元组实现
df.groupby(‘name‘)[‘chinese‘, ‘math‘].agg([(‘求和‘, sum), (‘平均值‘, ‘mean‘), (‘最小值‘, min)])
# 语文列聚合函数:求和
df.groupby(‘name‘).agg({‘chinese‘: sum})
# 选中的多个列,每列都应用不同的多个聚合函数
df.groupby(‘name‘).agg({‘chinese‘: [sum, ‘mean‘], ‘math‘: [np.min, np.max]})
用于一些较为复杂的聚合工作
def aaa(x):
return x.max() - x.min()
df.groupby(‘name‘).agg(aaa)
# 匿名函数实现
df.groupby(‘name‘).agg(lambda x: x.max() - x.min())
#例:返回 DataFrame 某一列中 n 个最大值
# 定一个 top 函数,返回 DataFrame 某一列中 n 个最大值
def top(df, n=2, column=‘chinese‘):
return df.sort_values(by=column, ascending=False)[:n]
# 自定义函数分组聚合参数
df.groupby(‘name‘).apply(top, n=1, column=‘math‘)
总结在学习apply函数用法时候,他是可以作用dataframe.series,所以
def bbb(x):
return x[‘chinese‘].mean() >= 60
df.groupby(‘name‘).agg(bbb) # 报错
df.groupby(‘name‘).apply(bbb) # 返回seies
def bbb(x):
return x.mean() >= 60
df.groupby(‘name‘).agg(bbb) # 返回datafrmae布尔值
df.groupby(‘name‘).apply(bbb) # 返回dataframe布尔值
例子:输出所有语文考试平均分及格的数据
def bbb(x):
return x.mean() >= 60
df.groupby(‘name‘).agg(bbb) # 返回布尔值
df.groupby(‘name‘).filter(bbb)
#输出所有语文平均分及格的学生
df.groupby(‘name‘).filter(bbb).groupby(‘name‘).mean()
def ccc(x):
return x + 10
df.groupby(‘name‘).transform(ccc)
# 使用向量化运算方式实现
df[[‘chinese‘, ‘math‘, ‘english‘]] + 10
原文:https://www.cnblogs.com/harden13/p/13693850.html