在Jenkins 1.x中,对于job的配置大多是基于图形界面的,也就是说,要在GUI页面手动设置相关的job参数。
随着不同类型和用途的job越来越多,参数越来越复杂,难以有效地管理数量庞大的图形界面配置信息,也无法有效追踪和记录配置的更改。
在Jenkins 2.0中,基于Pipeline,用户可以在一个 JenkinsFile 中快速实现一个项目的从构建、测试以到发布的完整流程,灵活方便地实现持续交付。
并且通过“pipeline script from SCM”方式,可以保存这个流水线的定义,进行版本化管理。
在实际使用中,一开始大都会制作一个尽可能通用的pipeline脚本样例,让搭建者只需要修改几个赋值参数就可以在项目中应用。
但不可避免的是,不同的项目往往有不同的需求,随着定制化需求越来越多,加入了不同的功能实现代码,导致pipeline也会越来越复杂,可读性差,也不利于维护。
而且随着pipeline数目不断的增多,将会发现同一类型和用途的pipeline,它们的很多功能其实是相同的,这时如果对某个功能做改动,往往需要更新数量众多的JenkinsFile。
针对pipeline的扩展和管理问题,共享库功能(Shared Libraries)应运而生。
共享库可以将整个pipeline脚本的实现和复杂度就被封装到Shared Library中,在各种项目之间共享pipeline核心实现,减少冗余代码,
也就是说,Shared Libraries的方式抽象了各种项目之间共享的代码(甚至整条完整的pipeline),有效降低了使用pipeline的复杂度。
而且通过外部源代码控制(SCM)的方式,保证所有job在构建的时候会调用最新的共享库代码。
共享库中存储的每个文件都是一个groovy的类,每个文件(类)中包含一个或多个方法,每个方法包含groovy语句块。
Shared Library遵循固定的代码目录结构:
+- src # Groovy source files
| +- org
| +- foo
| +- Bar.groovy # for org.foo.Bar class
+- vars
| +- foo.groovy # for global ‘foo‘ variable
| +- foo.txt # help for ‘foo‘ variable
+- resources # resource files (external libraries only)
| +- org
| +- foo
| +- bar.json # static helper data for org.foo.Bar
src目录:
.groovyvars目录:
.groovy.groovy文件中,可以通过import的方式,引入src目录的类库resources目录:
doc目录:
Manage Jenkins >> Configure System >> Global Pipeline Libraries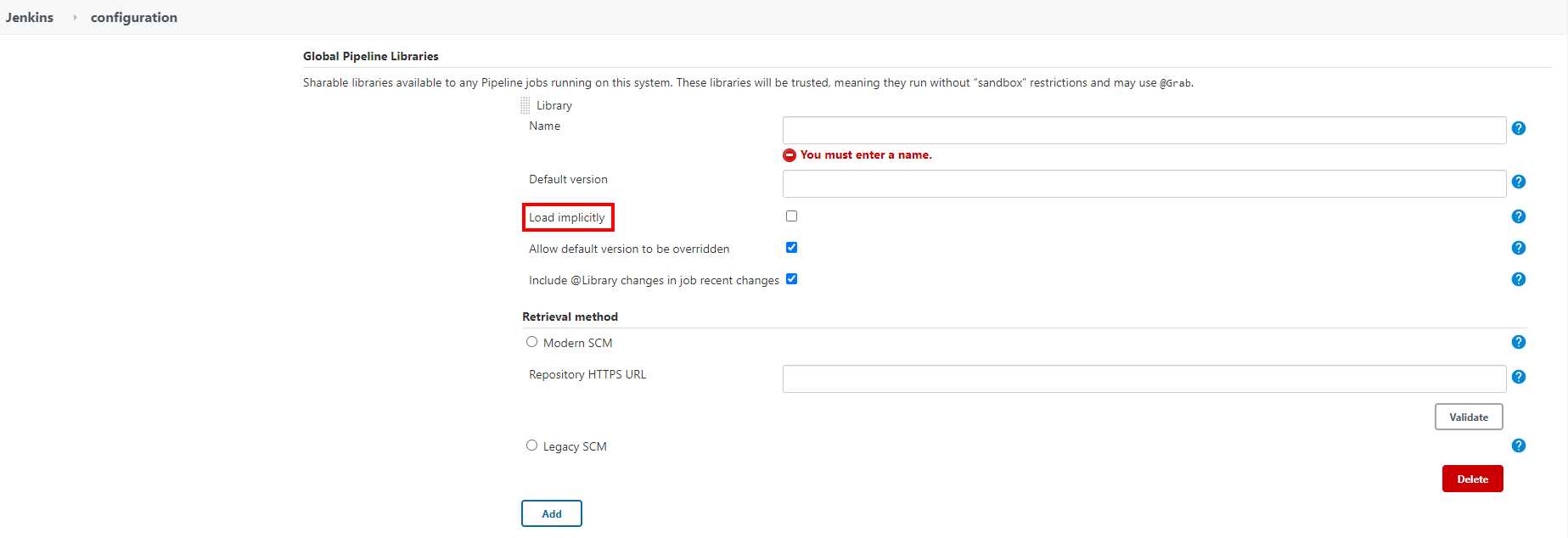
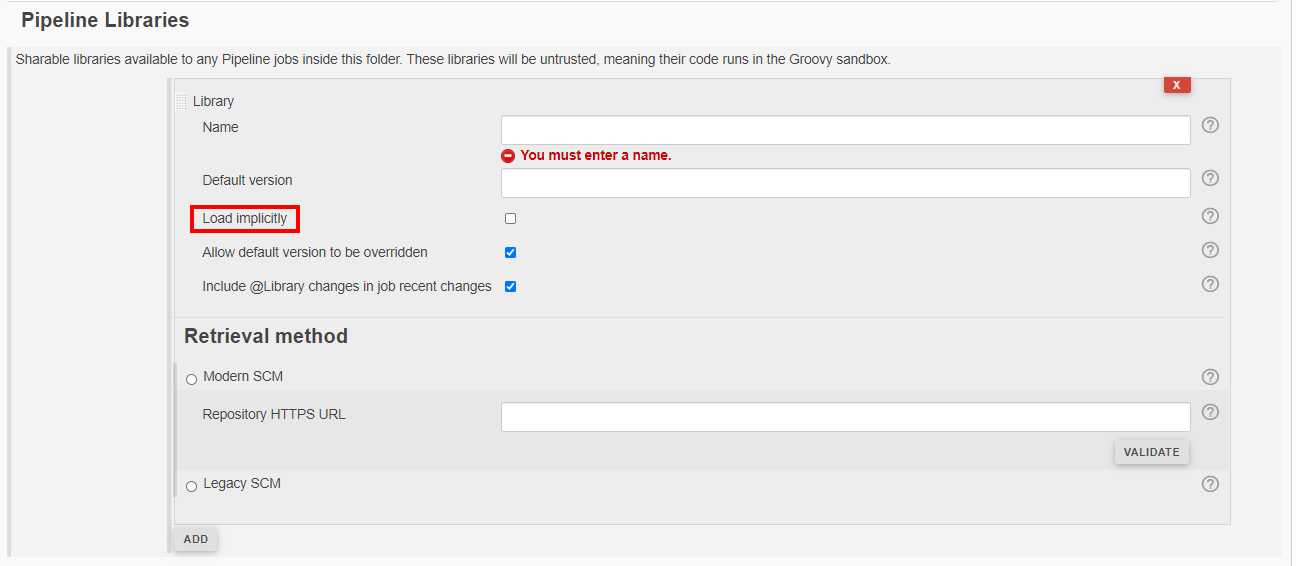
Load implicitly的共享库允许流水线立即使用任何此库定义的类或全局变量。@Library(‘my-shared-library‘) _有助于保持代码简洁。Jenkins - 共享库(Shared Libraries)
原文:https://www.cnblogs.com/anliven/p/13693871.html