数据驱动测试是自动化测试领域比较主流的设计模式之一,也是高级自动化测试工程师必备的技能之一。数据驱动框架是一种自动化测试框架,其目的在于可以让相同的脚本使用不同的测试数据,测试数据和测试行为(脚本)完全分离,便于测试的维护和扩展。
例如,测试登录操作时,需要用到多种用户来登录,然后验证系统的响应是否正确。这里,我们就可以先准备好要登录的用户数据(比如用户名和密码),只需一个自动化登录脚本即可实现。
数据驱动测试的一般步骤如下:
(1)编写脚本,脚本需要有可扩展性并且支持从对象、文件或者持久化数据库中读取测试数据。
(2)准备测试数据到文件或者数据库等外部介质中。
(3)循环调用介质中的数据库来驱动脚本执行。
(4)验证自动化测试结果。
在数据驱动框架中需要掌握 Python 对文件的基本操作等,在这一章中将详细讲解有关文件的相关操作。
之前的章节,我们都是将测试数据写在代码中,这种在程序中直接给代码赋值的形式俗称「hardcode」。直接将数据写在源代码中,若测试数据有变,并不利于数据的修改和维护,会造成程序的质量变低。
我们可以尝试通过将测试数据放到 Excel 文档中来实现测试数据的管理,而数据驱动框架的概念正是由此而来。
创建 Excel 文件「testdata.xlsx」以备测试之用,具体数据如图 10.29 所示。

图 10.29
下一步需要用 Python 实现读取 Excel 文件的函数功能以备测试之用。代码如下:

上述代码创建了命名为 read_excel 的函数,并设置了三个参数。其中,filename 是 Excel 文件名,可以指定为相对路径;Index 是 Sheet 的编号,比如 Excel 中 Sheet1 表格的 index 值为 0;column 是表格的列,比如 A 列对应的值为 0。
以上是用列表的方式来存储 Excel 中读取的数据,通过观察可以看到 A 列有 3 行数据,B 列有 4 行数据。其实这种情况下用字典的形式来存储数据比较好,每一列数据存储到一个列表中。新的读取 Excel 文件的函数代码如下:


以下代码调用为输出所有的 excel 文件中第一个 sheet 的所有数据,代码执行结果如图 10.30 所示,和 Excel 文件中的数据是一致的。从输出结果可以看到 Excel 文件有 3 行 2 列,还有数据的实际情况。
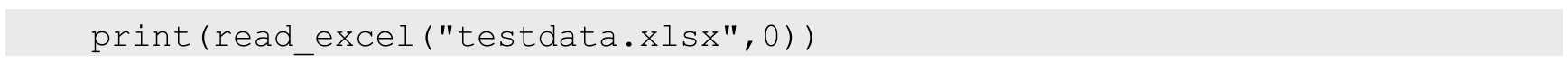

图 10.30
第 10 章 数据驱动测试(下) Selenium 3+Python 3 自动化测试
原文:https://www.cnblogs.com/MarlonKang/p/13694785.html