1、了解对比Hadoop不同版本的特性,可以用图表的形式呈现。
0.20.x版本最后演化成了现在的1.0.x版本
0.23.x版本最后演化成了现在的2.x版本
hadoop 1.0 指的是1.x(0.20.x),0.21,0.22
hadoop 2.0 指的是2.x,0.23.x
CDH3,CDH4分别对应了hadoop1.0 hadoop2.0
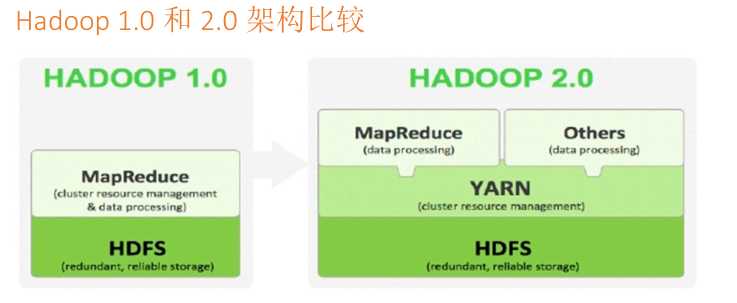
Hadoop2.x由HDFS、MapReduce和YARN三个分支构成。
HDFS:NN Federation(联邦)、HA(只支持2个节点,3.0实现了一主多从)。
MapReduce:运行在YARN上的MR;离线计算,基于磁盘l/O计算。
YARN:资源管理系统。
Hadoop 是一个能够对大量数据进行分布式处理的软件框架。具有可靠、高效、可伸缩的特点。
Hadoop 的核心是 HDFS 和 Mapreduce,HDFS 还包括 YARN。
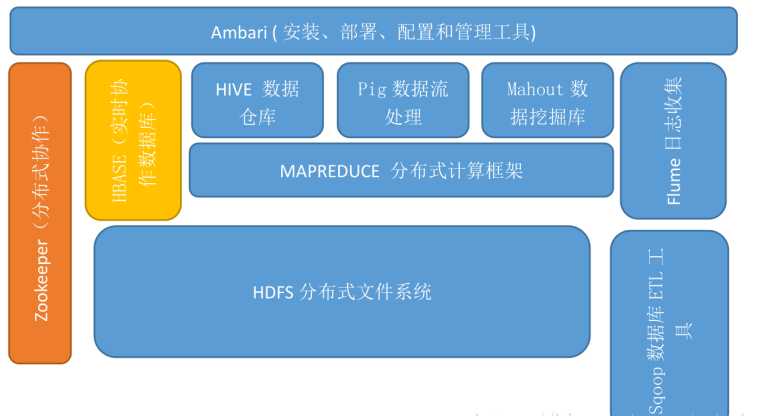
2、Hadoop生态的组成、每个组件的作用、组件之间的相互关系,以图例加文字描述呈现。
Hadoop主要组件以及作用:
Hadoop:Java编写的软件框架,以支持数据密集型分布式应用
ZooKeeper:高可靠性分布式协调系统
MapReduce:针对大数据的灵活的并行数据处理框架
HDFS:Hadoop分布式文件系统
Oozie:负责MapReduce作业调度
HBase:Key-value数据库
Hive:构建在MapRudece之上的数据仓库软件包
Pig:Pig是架构在Hadoop之上的高级数据处理层。Pig Latin语言为编程人员提供了更直观的定制数据流的方法。
3、官网学习Hadoop的安装与使用,用文档的方式列出步骤与注意事项。
安装步骤:首先需要Linux作为安装平台。
(第一步)下载HadoopJavaVersions所描述的java版本;
(第二步)安装软件,在Ubuntu Linux上:
$ sudo apt-get install ssh
$ sudo apt-get install pdsh
(第三步)下载需要安装的Hadoop发行版本,最好在官网下载稳定版本,
(第四步)准备启动Hadoop集群:
解压缩下载的Hadoop发行版。在发行版中,编辑文件etc / hadoop / hadoop-env.sh以定义一些参数,如下所示:
#设置为Java安装的根目录
export JAVA_HOME = / usr / java / latest
尝试以下命令:
$ bin / hadoop
这将显示hadoop脚本的用法文档。
现在,您可以以三种支持的模式之一启动Hadoop集群:
本地独立模式
伪分布式模式
全分布式模式
(第五步)独立运行:
默认情况下,Hadoop被配置为在非分布式模式下作为单个Java进程运行。这对于调试很有用。
下面的示例复制解压缩的conf目录以用作输入,然后查找并显示给定正则表达式的每个匹配项。输出被写入给定的输出目录。
$ mkdir input
$ cp etc/hadoop/*.xml input
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output ‘dfs[a-z.]+‘
$ cat output/*
(第六步)伪分式操作
组态:使用以下内容:
etc/hadoop/core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
etc/hadoop/hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
设置无密码SSH:
现在检查您是否可以在不使用密码的情况下SSH到本地主机:
$ ssh localhost
如果没有密码就无法SSH到本地主机,请执行以下命令:
$ ssh-keygen -t rsa -P ‘‘ -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
(第七步)全分布式运行。
原文:https://www.cnblogs.com/chen34/p/13695852.html