正常情况下,每个字或其他可寻址单位(字节、半字等)是作为一个整体数据单元看待的。但是,某些时候还需要将一个n位数据看成由n个1位数据组成,每个取值为0或1。例如,有时需要存储一个布尔或二进制数据阵列,阵列中的每项只能取值为1或0;有时可能需要提取一个数据项中的某位进行诸如“置位”或“清零”等操作。当数据以这种方式看待时,就被认为是逻辑数据。因此n位二进制数可表示n个逻辑值。逻辑数据只能参加逻辑运算,并且是按位进行的,如按位“与”、按位“或”、逻辑左移、逻辑右移等。
逻辑数据和数值数据都是一串0/1序列,在形式上无任何差异,需要通过指令的操作码类型来识别它们。
西文由拉丁字母、数字、标点符号及一些特殊符号所组成,它们统称为字符。所有字符的集合叫做字符集。字符不能直接在计算机内部进行处理,因而也必须对其进行数字化编码,字符集中每一个字符都有一个代码(即二进制编码的0/1序列),构成了该字符集的代码表,简称码表。码表中的代码具有唯一性。
字符主要用于外部设备和计算机之间交换信息。一旦确定了所使用的字符集和编码方法后,计算机内部所表示的二进制代码和外部设备输人、打印和显示的字符之间就有唯一的对应关系。字符集有多种,每个字符集的编码方法也多种多样。目前计算机中使用最广泛的西文字符集及其编码是ASCII码。
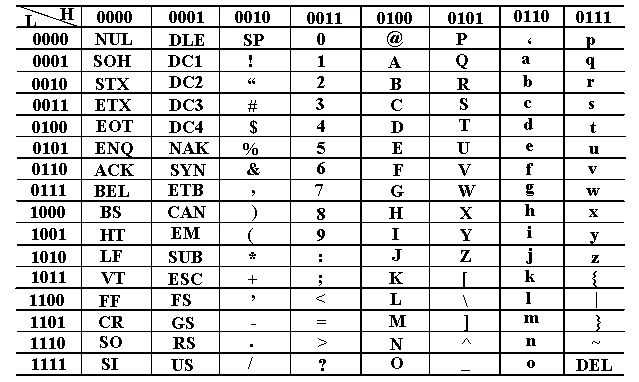
(1)字符0~9这10个数字字符的高3位编码为011,低4位分别为0000~1001。当去掉高3位时﹐低4位正好是0~9这10个数字的8421码。
这样既满足了正常的排序关系,又有利于实现 ASCII码与十进制数之间的转换。
(2)英文字母字符的编码值也满足正常的字母排序关系,而且大,小写字母的编码之间有简单的对应关系,差别仅在b。这一位上,若这一位为0,则是大写字母;若为1,则是小写字母。
中文信息的基本组成单位是汉字,汉字也是字符。但汉字是表意文字,一个字就是一个方块图形。计算机要对汉字信息进行处理,就必须对汉字本身进行编码,但汉字的总数超过6万字,数量巨大,给汉字在计算机内部的表示、汉字的传输与交换、汉字的输人和输出等带来了一系列问题。为了适应汉字系统各组成部分对汉字信息处理的不同需要,汉字系统必须处理以下几种汉字代码:输人码、内码、字模点阵码。
计算机内部任何信息都被表示成二进制编码形式。二进制数据的每一位(0 或1)是组成二进制信息的最小单位,称为一个比特,或称位元,简称位。 比特是计算机中处理、存储和传输信息的最小单位。
每个西文字符需要用8个比特表示,而每个汉字需要用16个比特才能表示。在计算机内部,二进制信息的计量单位是字节,也称位组。一个字节等于8个比特。
字长通常是指CPU内部用于整数运算的数据通路的宽度。CPU内部数据通路是指CPU内部的数据流经的路径以及路径上的部件,主要是CPU内部进行数据运算、存储和传送的部件,这此部件的宽度基本上要一致,才能相互匹配。因此字长等于CPU内部用于整数运算的运算器位数和通用寄存器宽度。
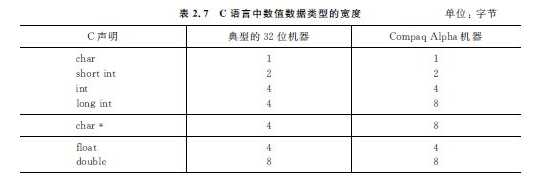
一般用最低有效位(LSB)和最高有效位(MSB)来分别表示数的最低位和最高位。对于带符号数,最高位是符号位,所以MSB就是符号位。
数据在计算机内部进行计算、存取和传送过程中,由于元器件故障或噪音干扰等原因会出现差错,为了减少和避免这些错误,一方面要从计算机硬件本身的可靠性入手,在电路、电源、布线等各方面采取必要的措施,提高计算机抗干扰能力;另一方面要采取相应的数据检错和校正措施,自动的的发现并纠正错误。
最简单的数据校验。在奇偶校验码中,若两个数据位不同,则他们的校验位就不同;若有偶数位不同,则虽校验位相同,但至少有两位数据位不同,因而任意两个码之间至少有两位不同。根据码距和检错/纠错能力的关系可知,他只能发现奇数位出错,不能发现偶数位出错,而且不能发现出错的位置,不具备纠错能力。但奇偶校验法所用的开销小,它常被用储存器读写检查或按字节传输过程中的数据校验,所以奇偶叫校验法用于校验字节长的代码还是有效的。
将数据按某种规律分成若干组,对每组进行相应的奇偶检测,以提供多位校验信息,从而可对错误位置进行定位,并将其纠正。海明校验码实质上就是一种多重奇偶校验码。
循环冗余校验码是一种具有较强检错,纠错能力的校验码,常用于外存储器和计算机同步通信。奇偶校验码和海明校验码都是采用奇偶检测为手段检错和纠错的(奇偶校验码不具有纠错能力),而循环冗余校验则是通过某种数学运算来建立数据位和校验位的约定关系的。
原文:https://www.cnblogs.com/liumingjiedexiaohuolong/p/13697317.html