定义:将元素顺序地存放在一块连续的存储区里,元素间的顺序关系由它们的存储顺序自然表示。
顺序表包含:表头和数据区
连续内存存放表头和数据区:表头包括:容量、元素个数
在数据区地址前开辟8个字节内存分别存储容量和元素个数(都是整型,存储整型需要4字节)
容量不够需开辟新的内存时,数据区和表头区都要重新拷贝覆盖
表头和数据区分离存储:表头包括:容量、元素个数、数据区地址
单独开辟一块内存用来存储表头,表头保存数据区的地址
容量不够需开辟新的内存时,只需要拷贝数据区,然后将表头指向新的内存地址
定义:将元素存放在通过链接构造起来的一系列存储块中。
一种线性表,不像顺序表一样连续存储数据,而是在每个节点(存储单元)里存放下一个节点的地址
每个结点保存元素的值和指向下一个结点的内存地址
链表查找元素时需要每次从头结点开始查找
链表失去了顺序表直接定位读取的优点。同时链表由于增加了结点的指针域,空间开销比较大,但对于存储空间的使用要相对灵活
链表与顺序表各操作的复杂度如下:
| 操作 | 链表 | 顺序表 |
|---|---|---|
| 访问元素 | O(n) | O(1) |
| 头部插入/删除 | O(1) | O(n) |
| 尾部插入/删除 | O(n) | O(1) |
| 中间插入/删除 | O(n) 在于遍历 | O(n) 在于数据挪位 |
注意虽然表面看起来复杂度都是O(n), 但是链表和顺序表在插入和删除时进行的是完全不同的操作。链表的主要耗时操作是遍历查找,删除和插入操作本身复杂度是O(1)。顺序表查找很快,主要耗时操作是拷贝覆盖;因为除了目标元素在尾部的特殊情况,顺序表进行插入和删除时需要对操作点之后的所有元素进行后移位操作,则只能通过拷贝和覆盖的方法进行。
class Node: """结点实现类""" def __init__(self, item): self.elem = item self.next = None ? # node = Node(100) ? class SingleLinkList: """单链表""" def __init__(self, node=None): self.__head = node def is_empty(self): """链表是否为空""" return self.__head == None ? def length(self): """链表长度""" # cur游标,用来移动遍历结点 cur = self.__head # count记录数量 count = 0 while cur != None: count += 1 cur = cur.next return count ? def travel(self): """遍历整个链表""" cur = self.__head while cur != None: print(cur.elem, end=" ") cur = cur.next print("") ? def add(self, item): """链表头部添加元素,头插法""" node = Node(item) node.next = self.__head self.__head = node # 新插入的结点作为头结点 ? def append(self, item): """链表尾部添加元素,尾插法""" node = Node(item) if self.is_empty(): self.__head = node else: cur = self.__head while cur.next != None: cur = cur.next cur.next = node ? def insert(self, pos, item): """指定位置添加元素 :params pos 从0开始 """ if pos <= 0: self.add(item) elif pos > (self.length()-1): self.append(item) else: pre = self.__head count = 0 while count < (pos-1): count += 1 pre = pre.next # 当退出循环后,pre指向pos-1位置 node = Node(item) node.next = pre.next pre.next = node ? def remove(self, item): """删除结点""" cur = self.__head pre = None while cur != None: if cur.elem == item: # 先判断此节点是否是头结点 if cur == self.__head: self.__head = cur.next else: pre.next = cur.next break else: pre = cur cur = cur.next ? def search(self, item): """查找结点是否存在""" cur = self.__head while cur != None: if cur.elem == item: return True else: cur = cur.next return False
class Node: def __init__(self, item): self.elem = item self.next = None ? ? class SingleCycleLinkList: """单向循环链表""" def __init__(self, node=None): self.__head = node if node: node.next=node # 循环 指向自己 def is_empty(self): """链表是否为空""" return self.__head == None ? def length(self): """链表长度""" if self.is_empty(): return 0 # cur游标,用来移动遍历结点 cur = self.__head # count记录数量 count = 1 while cur.next != self.__head: count += 1 cur = cur.next return count ? def travel(self): """遍历整个链表""" if self.is_empty(): return cur = self.__head while cur.next != self.__head: print(cur.elem, end=" ") cur = cur.next # 退出循环,cur指向尾节点,但尾结点的元素未打印 print(cur.elem) ? def add(self, item): """链表头部添加元素,头插法""" node = Node(item) if self.is_empty(): self.__head = node node.next = node else: cur = self.__head while cur.next != self.__head: cur = cur.next # 退出循环 node.next = self.__head self.__head = node # cur.next = node cur.next = self.__head ? def append(self, item): """链表尾部添加元素,尾插法""" node = Node(item) if self.is_empty(): self.__head = node node.next = node else: cur = self.__head while cur.next != self.__head: cur = cur.next node.next = self.__head cur.next = node ? ? def insert(self, pos, item): """指定位置添加元素 :params pos 从0开始 """ if pos <= 0: self.add(item) elif pos > (self.length()-1): self.append(item) else: pre = self.__head count = 0 while count < (pos-1): count += 1 pre = pre.next # 当退出循环后,pre指向pos-1位置 node = Node(item) node.next = pre.next pre.next = node ? def remove(self, item): """删除结点""" cur = self.__head pre = None while cur.next != self.__head: if cur.elem == item: # 先判断此节点是否是头结点 if cur == self.__head: # 头结点的情况 # 找尾结点 rear = self.__head while rear.next != self.__head: rear = rear.next self.__head = cur.next rear.next = self.__head else: # 中间结点 pre.next = cur.next return else: pre = cur cur = cur.next # 退出循环,cur指向尾结点 if cur.elem == item: if cur == self.__head: # 链表只有一个结点 self.__head = None else: pre.next = cur.next ? def search(self, item): """查找结点是否存在""" if self.is_empty(): return False cur = self.__head while cur.next != self.__head: if cur.elem == item: return True else: cur = cur.next # 退出循环,cur指向尾结点 if cur.elem == item: return True return False ?
class Stack: """栈""" def __init__(self): self.__list = [] # 私有,防止绕过栈直接操作列表头尾都能插入 ? def push(self, item) """添加一个新元素,入栈""" self.__list.append(item) ? def pop(self): """弹出栈顶元素""" return self.__list.pop() ? def peek(self): """返回栈顶元素""" if self.__list: return self.__list[-1] else: return None ? def is_empty(self): """判断栈是否为空""" return self.__list == [] ? def size(self): """返回栈的元素个数""" return len(self.__list)
?
class Queue: """队列""" def __init__(self): self.__list = [] ? def enqueue(self, item): """往队列中添加一个元素,入队""" self.__list.append(item) # 1 时间复杂度 O(1) # self.__list.insert(0, item) # 2 时间复杂度 O(n) ? def dequeue(self): """从队列头部弹出一个元素,出队""" return self.__list.pop(0) # 1 时间复杂度 O(n) # return self.pop() # 2 时间复杂度 O(1) ? # 无论选择顺序表的哪一端出入,总有一个操作是O(n) # 需要看使用中入队和出队哪种操作更常用,再做选择 ? def is_empty(self): """判断队列是否为空""" return self.__list == [] ? def size(self): """返回队列的元素个数""" return len(self.__list)
class Deque: """双端队列""" def __init__(self): self.__list = [] ? def add_front(self, item): """从头部往队列中添加一个元素""" self.__list.insert(0, item) ? def add_rear(self, item): """从尾部往队列中添加一个元素""" self.__list.append(item) ? def pop_front(self): """从队列头部弹出一个元素""" return self.__list.pop(0) ? def pop_rear(self): """从队列尾部弹出一个元素""" return self.__list.pop() ? def is_empty(self): """判断队列是否为空""" return self.__list == [] ? def size(self): """返回队列的元素个数""" return len(self.__list)
节点的度:一个节点含有的子树的个数称为该节点的度
树的度:一棵树中,最大的节点的度称为树的度
叶节点或终端节点:度为零的节点
父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点
子节点:一个节点含有的子树的根节点称为该节点的子节点
兄弟节点:具有相同父节点的节点互称为兄弟节点
节点的层次:从根开始定义起,根为第一层,根的子节点为第二层,以此类推
树的高度或深度:树中节点的最大层次
堂兄弟节点:父节点在同一层的的节点互为堂兄弟
节点的祖先:从根到该节点所经分支上的所有节点
子孙:以某节点为根的子树中任一节点都称为该节点的子孙
森林:由m(m>=0) 棵互不相交的树的集合称为森林
无序树:树中任意节点的子节点之间没有顺序关系,这种树称为无序树,也称为自由树
有序树:树中任意节点的子节点之间有顺序关系,这种树称为有序树
二叉树:每个节点最多含有两个子树的树称为二叉树
完全二叉树:对于一棵二叉树,假设其深度为d(d>1),除了第d层外,其它各层的节点数目均已达到最大值,且第d层所有节点从左往右连续紧密排列,这样的二叉树称为完全二叉树,其中满二叉树的定义是所有叶子节点都在最底层的完全二叉树;
平衡二叉树(AVL树):当且仅当任何节点的两棵子树的高度差不大于1的二叉树
排序二叉树(二叉查找树):也称二叉搜索树,有序二叉树
霍夫曼树(用于信息编码):带权路径最短的二叉树称为哈夫曼树或最优二叉树
B树:一种对读写操作进行优化的自平衡的二叉查找树,能够保持数据有序,拥有多余两个子树
性质1:在二叉树的第i层上至多有 2^(i-1) 个节点 (i>0)
性质2:深度为k的二叉树至多有 2^k - 1 个节点 (k>0)
性质3:对于任意一棵二叉树,如果其叶节点树为N0,而度数为2的节点总数为N2,则N0=N2+1
性质4:具有n个节点的完全二叉树的深度必为log(n+1)
性质5:对完全二叉树,若从上至下,从左至右编号,则编号为i的节点,其左孩子编号必为2i,其右孩子编号必为2i+1;其双亲编号必为i/2(i=1时为根,除外)
也叫层次遍历:从上到下,从左到右
先序遍历:根节点——> 左节点——> 右节点
中序遍历:左节点——> 根节点——> 右节点
后序遍历:左节点——> 右节点——> 根节点
左右节点顺序不变,只是改动根节点的位置
由于是深度遍历,每次遍历都会将该节点往下的子树节点继续按同样的规则遍历,直到没有子节点。
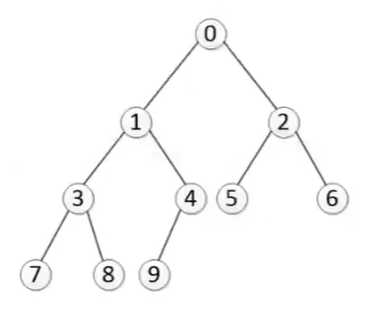
层次遍历(广度优先):0 1 2 3 4 5 6 7 8 9 ? 先序遍历:0 1 3 7 8 4 9 2 5 6 ? 中序遍历:7 3 8 1 9 4 0 5 2 6 ? 后序遍历:7 8 3 9 4 1 5 6 2 0
class Node(object): def __init__(self, item): self.elem = item self.lchild = None self.rchild = None ? ? class Tree(object): """二叉树""" def __init__(self): self.root = None ? def add(self, item): """添加节点""" node = Node(item) if self.root is None: self.root = node return # 队列 queue = [self.root] while queue: cur_node = queue.pop(0) if cur_node.lchild is None: cur_node.lchild = node return else: queue.append(cur_node.lchild) if cur_node.rchild is None: cur_node.rchild = node return else: queue.append(cur_node.rchild) ? def breadth_travel(self): """广度遍历 每次从队列头部取出一个节点,查看它的两个子节点,若不为None则放入队列 """ if self.root is None: return ? queue = [self.root] # 队列 while queue: cur_node = queue.pop(0) print(cur_node.elem, end=‘ ‘) if cur_node.lchild is not None: queue.append(cur_node.lchild) if cur_node.rchild is not None: queue.append(cur_node.rchild) ? ? def preorder(self, node): """先序遍历 每次传入当前子树的父节点,打印该节点,并递归它的左右子节点 """ if node is None: return print(node.elem, end=‘ ‘) self.preorder(node.lchild) self.preorder(node.rchild) ? def inorder(self, node): """中序遍历 """ if node is None: return ? self.inorder(node.lchild) print(node.elem, end=‘ ‘) self.inorder(node.rchild) ? def postorder(self, node): """后序遍历 """ if node is None: return ? self.postorder(node.lchild) self.postorder(node.rchild) print(node.elem, end=‘ ‘)
变量保存的不是元素的值,而是值的地址
如:a,b=b,a 只是将a和b保存的地址做了交换;
python中一个变量a之所以无需声明类型,但能够保存各种不同的类型,包括基础类型,函数等,就是因为变量仅保存的是对象的地址,通过地址获取具体的值(不像c等语言一样,变量使用前必须声明类型)

原文:https://www.cnblogs.com/Deaseyy/p/13700902.html