scrapy 分页爬取以及xapth使用小技巧
这里以爬取www.javaquan.com为例:
1.构建出下一页的url:
很显然通过dom树,可以发现下一页所在的a标签
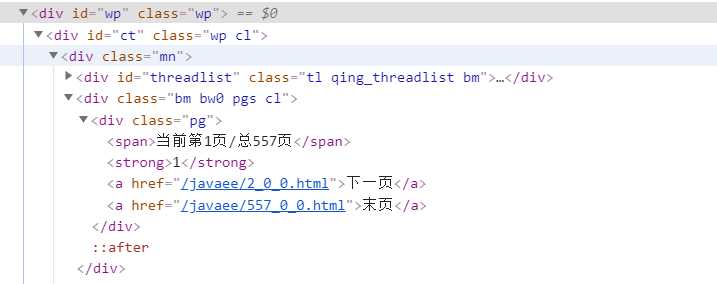
2.使用scrapy的yield scrapy.Reqeust(next_url,callback=self.parse) 构造下一页爬取的请求

【Scrapy(四)】scrapy 分页爬取以及xapth使用小技巧
原文:https://www.cnblogs.com/july-sunny/p/13703140.html