一、简介(?:pattern)、(?=pattern)、 (?!pattern)、 (?<=pattern)、 (?<!pattern)
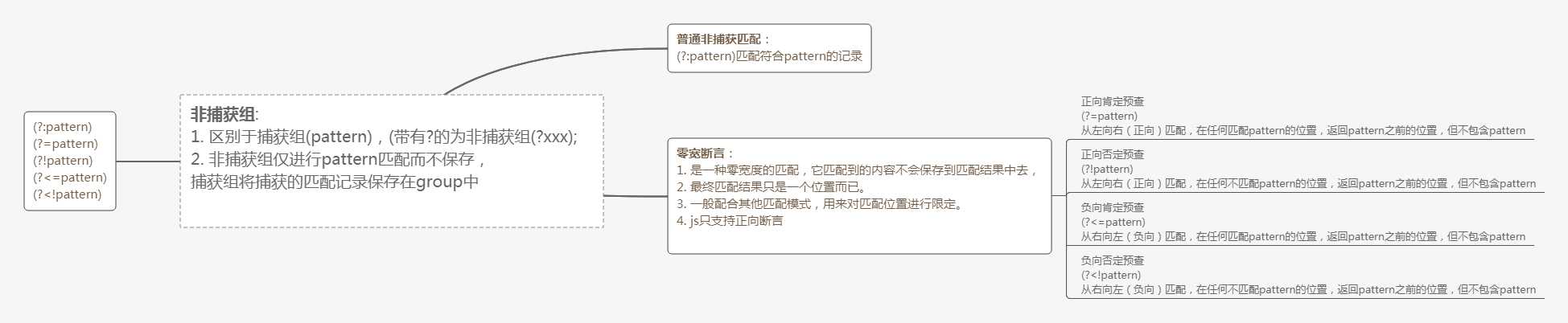
这是我做的一张思维导图,说一个容易被忽视的地方,就是零宽断言会匹配出任何满足pattern的位置,而不是像捕获组一样下次匹配是在上次匹配记录之后开始的。
例如:
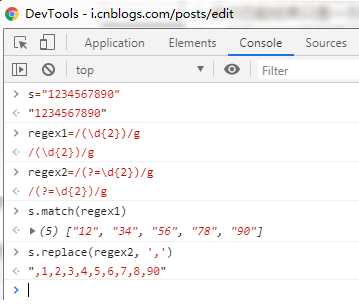
二、快速理解零宽断言
举个栗子,有以下文本:
1 我要吃好吃的 我要下班 我要睡觉 2 我不要吃好吃的 我要下班 我要睡觉 3 我要吃好吃的 我要下班 我不要睡觉 伪代码: positive_lookahead_regex = 我要下班(?=我要睡觉) //这里的含义为 匹配"我要下班"这个模式的同时满足"我要睡觉"这个模式。 negative_lookahead_regex = 我要下班(?!我要睡觉) // 这里的含义为 匹配"我要下班"这个模式的同时满足 不是"我要睡觉"这个模式。 positive_lookbehind_regex = (?<=我要吃好吃的)我要下班 negative_lookbehind_regex = (?<!我要吃好吃的)我要下班
快速记忆方法:
1、首先(? 开头 表示非捕获组
2、然后如果是负向的断言 则会跟 "<"
3、最后 肯定 是"=",否定是"!"
Q: 正向 肯定 预查 equals (?=pattern)
负向 否定 预查 equals (?<!pattern)
四、实践中不断理解
str1 = "123456789 12384" pattern = "\B(?=(?:\d{3})+(?!\d))" Q:如果用这个模式去 匹配str1,并且对匹配到的位置进行替换成"," 最终结果会是什么,这个过程是怎样的?
最好自己有答案,在看结果哦~

str1 = "123456789 12384" pattern = "/\B(?=(?:\d{3})+(?!\d))/g" str1.replace(pattern,‘,‘) // "123,456,789 12,384"
谈谈regex (?:) (?=) (?!) (?<=) (?<!)
原文:https://www.cnblogs.com/wikis/p/13727432.html
