作者|SUNIL RAY
编译|Flin
来源|analyticsvidhya
如果你要问我机器学习中2种最直观的算法——那就是k最近邻(kNN)和基于树的算法。两者都易于理解,易于解释,并且很容易向人们展示。有趣的是,上个月我们对这两种算法进行了技能测试。
如果你不熟悉机器学习,请确保在了解这两种算法的基础上进行测试。它们虽然简单,但是功能强大,并且在工业中得到广泛使用。此技能测试将帮助你在k最近邻算法上进行自我测试。它是专为你测试有关kNN及其应用程序的知识而设计的。
超过650人注册了该测试。如果你是错过这项技能测试的人之一,那么这篇文章是测试问题和解决方案。这是参加考试的参与者的排行榜。
这里有一些资源可以深入了解该主题。
A)真
B)假
解决方案:A
该算法的训练阶段仅包括存储训练样本的特征向量和类别标签。
在测试阶段,通过分配最接近该查询点的k个训练样本中最频繁使用的标签来对测试点进行分类——因此需要更高的计算量。
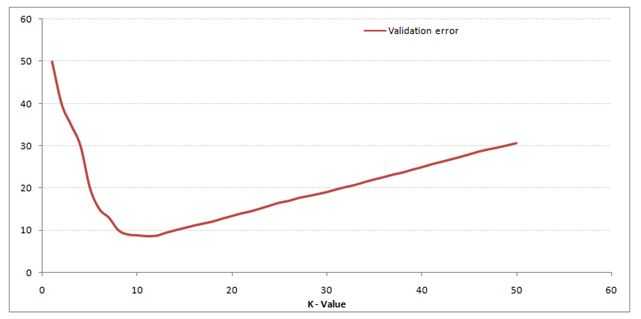
A) 3
B) 10
C) 20
D) 50
解决方案:B
当k的值为10时,验证误差最小。
A) Manhattan
B) Minkowski
C) Tanimoto
D) Jaccard
E) Mahalanobis
F)都可以使用
解决方案:F
所有这些距离度量都可以用作k-NN的距离度量。
A)可用于分类
B)可用于回归
C)可用于分类和回归
解决方案:C
我们还可以将k-NN用于回归问题。在这种情况下,预测可以基于k个最相似实例的均值或中位数。
A)1和2
B)1和3
C)仅1
D)以上所有
解决方案:D
以上陈述是kNN算法的假设
A)K-NN
B)线性回归
C)Logistic回归
解决方案:A
k-NN算法可用于估算分类变量和连续变量的缺失值。
A)可用于连续变量
B)可用于分类变量
C)可用于分类变量和连续变量
D)无
解决方案:A
曼哈顿距离是为计算实际值特征之间的距离而设计的。
A)1
B)2
C)3
D)1和2
E)2和3
F)1,2和3
解决方案:A
在连续变量的情况下使用欧氏距离和曼哈顿距离,而在分类变量的情况下使用汉明距离。
A)1
B)2
C)4
D)8
解决方案:A
sqrt((1-2)^ 2 +(3-3)^ 2)= sqrt(1 ^ 2 + 0 ^ 2)= 1
A)1
B)2
C)4
D)8
解决方案:A
sqrt(mod((1-2))+ mod((3-3)))= sqrt(1 + 0)= 1
假设你给出了以下数据,其中x和y是2个输入变量,而Class是因变量。

以下是散点图,显示了2D空间中的上述数据。
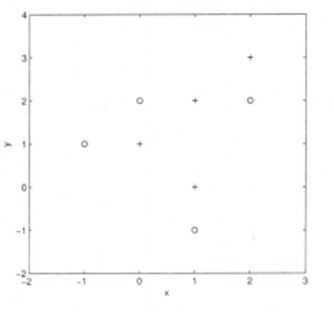
A)+ 类
B)– 类
C)不能判断
D)这些都不是
解决方案:A
所有三个最近点均为 + 类,因此此点将归为+ 类。
A)+ 类
B)– 类
C)不能判断
解决方案:B
现在,此点将归类为 – 类,因为在最近的圆圈中有4个 – 类点和3个 + 类点。
假设你提供了以下2类数据,其中“+”代表正类,“-”代表负类。
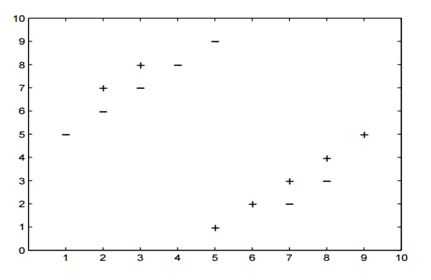
A)3
B)5
C)两者都相同
D)没有一个
解决方案:B
5-NN将至少留下一个交叉验证错误。
A)2/14
B)4/14
C)6/14
D)8/14
E)以上都不是
解决方案:E
在5-NN中,我们将有10/14的交叉验证精度。
A)当你增加k时,偏差会增加
B)当你减少k时,偏差会增加
C)不能判断
D)这些都不是
解决方案:A
大K表示简单模型,简单模型始终被视为高偏差
A)当你增加k时,方差会增加
B)当你减少k时,方差会增加
C)不能判断
D)这些都不是
解决方案:B
简单模型将被视为方差较小模型
你的任务是通过查看以下两个图形来标记两个距离。关于下图,以下哪个选项是正确的?

A)左为曼哈顿距离,右为欧几里得距离
B)左为欧几里得距离,右为曼哈顿距离
C)左或右都不是曼哈顿距离
D)左或右都不是欧几里得距离
解决方案:B
左图是欧几里得距离的工作原理,右图是曼哈顿距离。
A)我将增加k的值
B)我将减少k的值
C)噪声不能取决于k
D)这些都不是
解决方案:A
为了确保你进行的分类,你可以尝试增加k的值。
A)1
B)2
C)1和2
D)这些都不是
解决方案:C
在这种情况下,你可以使用降维算法或特征选择算法
A)1
B)2
C)1和2
D)这些都不是
解决方案:C
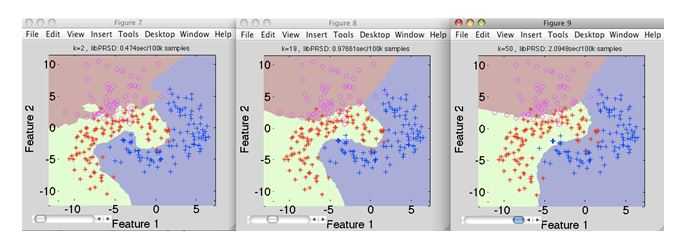
A)k1 > k2 > k3
B)k1 < k2
C)k1 = k2 = k3
D)这些都不是
解决方案:D
k值在k3中最高,而在k1中则最低
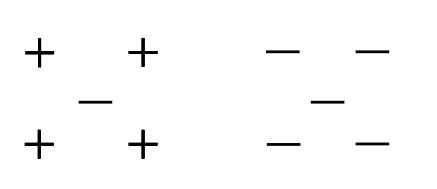
A)1
B)2
C)3
D)5
解决方案:B
如果将k的值保持为2,则交叉验证的准确性最低。你可以自己尝试。
注意:模型已成功部署,除了模型性能外,在客户端没有发现任何技术问题
A)可能是模型过拟合
B)可能是模型未拟合
C)不能判断
D)这些都不是
解决方案:A
在一个过拟合的模块中,它似乎会在训练数据上表现良好,但它还不够普遍,无法在新数据上给出相同的结果。
A)1
B)2
C)1和2
D)这些都不是
解决方案:C
这两个选项都是正确的,并且都是不言而喻的。
A) k值越大,分类精度越好
B) k值越小,决策边界越光滑
C) 决策边界是线性的
D) k-NN不需要显式的训练步骤
解决方案:D
选项A:并非总是如此。你必须确保k的值不要太高或太低。
选项B:此陈述不正确。决策边界可能有些参差不齐
选项C:与选项B相同
选项D:此说法正确
A)真
B)假
解决方案:A
你可以通过组合1-NN分类器来实现2-NN分类器
A) K值越大,边界越光滑
B) 随着K值的减小,边界变得更平滑
C) 边界的光滑性与K值无关
D) 这些都不是
解决方案:A
通过增加K的值,决策边界将变得更平滑
A)1
B)2
C)1和2
D)这些都不是
解决方案:C
两种说法都是正确的
注意:计算两个观测值之间的距离将花费时间D。
A)N * D
B)N * D * 2
C)(N * D)/ 2
D)这些都不是
解决方案:A
N的值非常大,因此选项A是正确的
A)1-NN > 2-NN > 3-NN
B)1-NN < 2-NN < 3-NN
C)1-NN ~ 2-NN ~ 3-NN
D)这些都不是
解决方案:C
在kNN算法中,任何k值的训练时间都是相同的。
以下是参与者的分数分布:
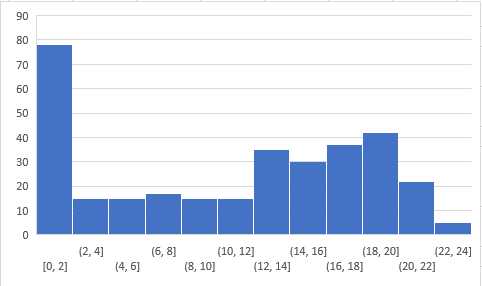
你可以在此处(https://datahack.analyticsvidhya.com/contest/skilltest-logistics-regression/#LeaderBoard) 访问分数。超过250人参加了技能测试,获得的最高分是24。
原文链接:https://www.analyticsvidhya.com/blog/2017/09/30-questions-test-k-nearest-neighbors-algorithm/
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
原文:https://www.cnblogs.com/panchuangai/p/13733044.html