Scrapy爬虫支持多种HTML信息提取方法:
Beautiful Soup
lxml
re
XPath Selector
CSS Selector
***********************************************************
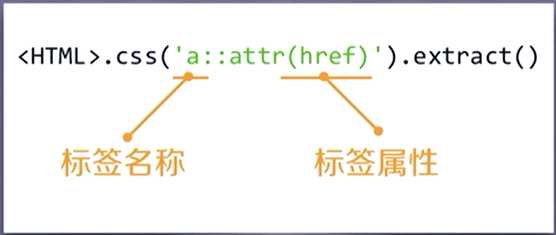
CSS Selector 的基本使用:
<HTML>.css(‘a::attr(href)‘).extract
scrapy必要类相关知识
原文:https://www.cnblogs.com/dingh/p/13733682.html