当前,智能手机制造行业已经由发展期迈入高度成熟期,智能手机制造企业,也开始以不同的角度为切入点,提升自家产品质量,进行差异化竞争。
对于消费者,成熟的产业加充分的竞争带来的好处就是市场上可供选择的商品越来越多,不同品牌的机型甚至同品牌不同型号的机型之间的差异也变得越来越明显,不同产品之间在拍照质量、游戏性能、网络质量等各个方面均有着相当大的不同。
此时,没有专业背景的消费者们在面对这些琳琅满目的商品时不免会陷入乱花渐欲迷人眼的尴尬境地。
鉴于智能手机质量硬指标较多,天生容易量化评估的特点,结合实际挑选推荐采购经验,“掌鉴”应运而生。
“掌鉴”是一款消费导购类产品,面对居民现实生活中的智能手机消费需求而创立,它将用户输入的需求模型与产品性能模型进行关联度匹配,将匹配后的结果依据关联度的高低顺序呈现给消费者,为消费者的购买决策提供了精准的辅助信息。
用户在购买手机时,通常考虑的是手机外观、手机信号、手机屏幕质量、手机拍照能力和手机续航能力这五个方面的内容,不同的用户对这5方面有着不同的需求,比如年轻人多看重手机玩游戏的性能,而生意人,更看重的是手机通讯能力和续航时间。
“掌鉴”,通过将智能手机各项性能参数逐一录入软件数据库,将智能手机依据消费者最为关注的产品性能精准划分为通讯、性能、屏幕、拍照、续航五个参数,而后通过简单直观的界面,将五个参数以可交互的模式摆在的用户面前,让用户确定自身需求模型,而后,系统利用用户提交的需求模型,采用后台推荐算法依据关联度生成产品推荐列表,最终实现了私人化的产品推荐结果,让用户获得最适合自己的智能手机。
在用户产生购买参数的购物意图后,可以进入“掌鉴”小程序,依据自身需求,选择产品需求模型。确定需求模型后,点击推荐按钮提交到推荐服务器,而后由服务器计算后返回产品推荐列表。
由“掌荐”小程序的“模型获取-结果推荐”的产品逻辑特点,可将该小程序划分为两个交互页面,第一个页面负责模型获取,第二个页面负责结果返回。
在模型获取页面,主要目的为由用户提供自身的产品需求模型,而需求模型由5个参数组成,故模型获取页面需呈现简明的包含五项内容信息的表单。
由于小程序为微信功能,为保持交互一致性,设计采微信原生的WeUI组件。在WeUI中,Slider滑块组件,可以将数字转化为动作交互,故选取其作为参数获取组件。
为了使用户对自身确定的需求模型有更为直观的了解,在全部滑块的上方,展示一个由当前所有滑块位置参数生成的雷达图,供用户参考。
在结果返回页面,主要呈现推荐的结果,在推荐的结果中,包含十款手机,每款均包含名称、简介、图片、价格四种信息。
为保持交互一致性,结果返回页面同样采用WeUI组件。在WeUI中,Panel面板中的图文组合列表排版包含图片与简明信息,与返回页面需求比较匹配,故依此设计,加入价格元素,组成最终列表。
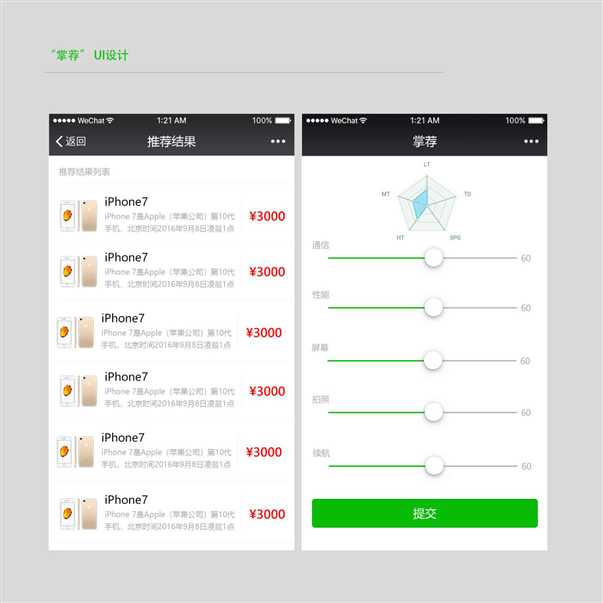
图 “掌荐”UI设计
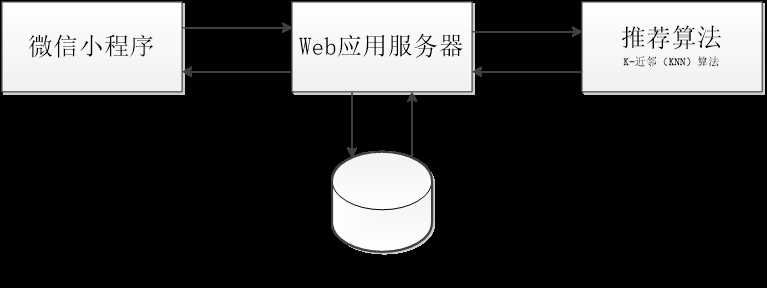
图 总体架构

图 雷达图展示模块
使用canvas绘制出来。当有数据变化的时候更新雷达图。
通过判断本地缓存是否有之前保存的数据来进行雷达图的绘制,如果有缓存数据(之前搜索过),那么就设置雷达图为之前的数据展示。如果没有缓存,那么就设置初始值,而不是0,让刚打开的时候雷达图不是那么的突兀。
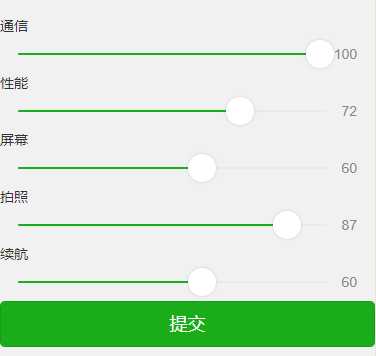
图 数据提交模块
使用form表单,将数据提交过去。
通过对submit事件的拦截,获得用户输入的各项数据,存入本地缓存中。再通过get方法提交到网站。如果成功则跳转到数据展示页面。
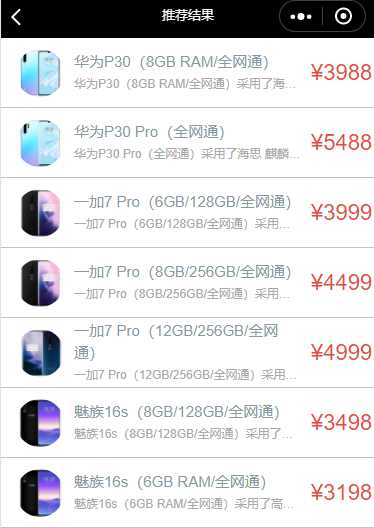
图 数据展示模块
从网站读取到相应数据,通过list列表的形式图文展示出来。
使用flex布局实现list列表,对于列表中的每一项通过absolute布局实现自适应的效果。
Tomcat是Apache 软件基金会(Apache Software Foundation)的Jakarta 项目中的一个核心项目,由Apache、Sun 和其他一些公司及个人共同开发而成。由于有了Sun 的参与和支持,最新的Servlet 和JSP 规范总是能在Tomcat 中得到体现,Tomcat 5支持最新的Servlet 2.4 和JSP 2.0 规范。因为Tomcat 技术先进、性能稳定,而且免费,因而深受Java 爱好者的喜爱并得到了部分软件开发商的认可,成为目前比较流行的Web 应用服务器。
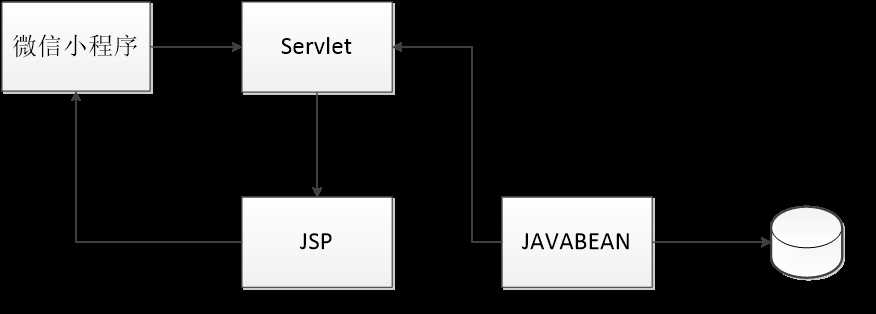
图 Web应用服务器架构
Servlet主要用来接收来自微信小程序客户端传来的HTTP请求,并返回一个响应。
在微信小程序传来包含用户模型的GET或者POST请求后,Servlet将用户模型存入依据用户模型而建立的数据JavaBean,而后将该数据JavaBean传入进行推荐功能的工具JavaBean中,运算得出包含十个手机信息模型数据JavaBean的数组,最后利用函数将该数组输出为Json数据,并返回JSP页面。
在输出十个手机信息模型数据JavaBean的数组时,可利用PrintWriter类的print()方法,先输出JSON格式框架,而后利用数据JavaBean的get()方法将每个模型的数据填充到框架中,利用for循环实现十组数据的遍历输出。
1)用户模型数据JavaBean
该数据JavaBean 主要包含通信、性能、屏幕、拍照、续航五个属性,用于存储用户需求模型。
2)查询列表数据JavaBean
该数据JavaBean 主要包含十个手机的phid数据库主键字段,用于存储计算返回的手机列表phid及排名信息,用于下一步查询各个手机的具体信息。
3)手机信息模型数据JavaBean
该数据JavaBean 主要包含单个手机的名称、简介、图片、价格、phid数据库主键字段这五个属性,用于存储单个手机的信息。
1)推荐列表获取工具JavaBean
该工具JavaBean将从Servlet获取到的用户需求模型提交到由K-近邻(KNN)算法构成的运算器中,而后获得推荐返回结果,将推荐返回结果传递给手机信息查询工具JavaBean,获得包含十个手机信息模型数据JavaBean的数组,返回给Servlet。
2)手机信息查询工具JavaBean
该工具JavaBean将从推荐列表获取工具JavaBean获取到的推荐返回结果依次连接数据库查询出相应的手机信息,依次存入手机信息模型数据JavaBean,组成数组,而后返回给推荐列表获取工具JavaBean。
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。
kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 kNN方法在类别决策时,只与极少量的相邻样本有关。由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。
算法优点:
1.简单,易于理解,易于实现,无需估计参数,无需训练;
2.适合对稀有事件进行分类;
3.特别适合于多分类问题(multi-modal,对象具有多个类别标签), kNN比SVM的表现要好。
算法缺点:
1.该算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。 该算法只计算“最近的”邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量并不能影响运行结果。
2.计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。
3.可理解性差,无法给出像决策树那样的规则。
一个对于KNN算法解释最清楚的图如下所示:
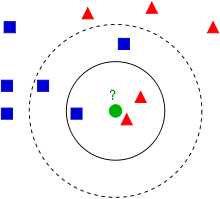
图 123
蓝方块和红三角均是已有分类数据,当前的任务是将绿色圆块进行分类判断,判断是属于蓝方块或者红三角。
当然这里的分类还跟K值是有关的:
如果K=3(实线圈),红三角占比2/3,则判断为红三角;
如果K=5(虚线圈),蓝方块占比3/5,则判断为蓝方块。
由此可以看出knn算法实际上根本就不用进行训练,而是直接进行计算的,训练时间为0,计算时间为训练集规模n。
knn算法的伪代码
1、计算已知类别数据集中的点与当前之间的距离
2、按照距离递增次序排序
3、选取与当前点距离最6,小的k个点
4、确定前k个点所在的类别的出现频率
5、返回前k个点出现频率最高的类别作为当前点的预测分类
KNN是简单有效的分类数据算法,在使用时必须有训练样本数据,还要计算距离,如果数据量非常大会非常消耗空间和时间。它的另一个缺陷是无法给出任何数据的基础结构信息,因此我们无法平均实例样本和典型实例样本具体特征。
由于时间仓促,现在“掌荐”小程序后台手机信息数据库仍然存在不健全的问题,随着数据库信息的逐步完善,未来“掌荐”推荐将变得更加精准,结果也将变得更加丰富。
在建立初期资金短缺的情况下,“掌荐”小程序后台服务器的性能还不是很强大,在未来,可通过硬件升级、网络升级等方式,逐步提高“掌荐”服务容量。
在小程序用户量增加到一定规模时,可在不影响结果客观性与产品核心价值的前提下,在结果页面做一些电商导流内容作为盈利内容。
与手机相同,笔记本电脑产品也有着天然可量化评价的属性,故“掌荐”也可升级个人电脑推荐业务,为电脑消费者提供精准的消费决策支持服务。
《掌荐 - 商品推荐系统》 - 2019微信小程序应用开发赛
原文:https://www.cnblogs.com/stevenwsx/p/13737036.html