在介绍完正则表达式的元字符、重复、分组的概念后,基本上我们对正则表达式的基本使用就OK了,本文我们讲一下正则表达式的高阶使用方式。
本节我们讲一下几种正则表达式的高级使用方式:
1. 正则表达式的后向引用 。
2. 零宽断言的概念及使用场景。
3. 负向零宽断言的概念及使用场景。
4. 冗长的平衡组合递归匹配。
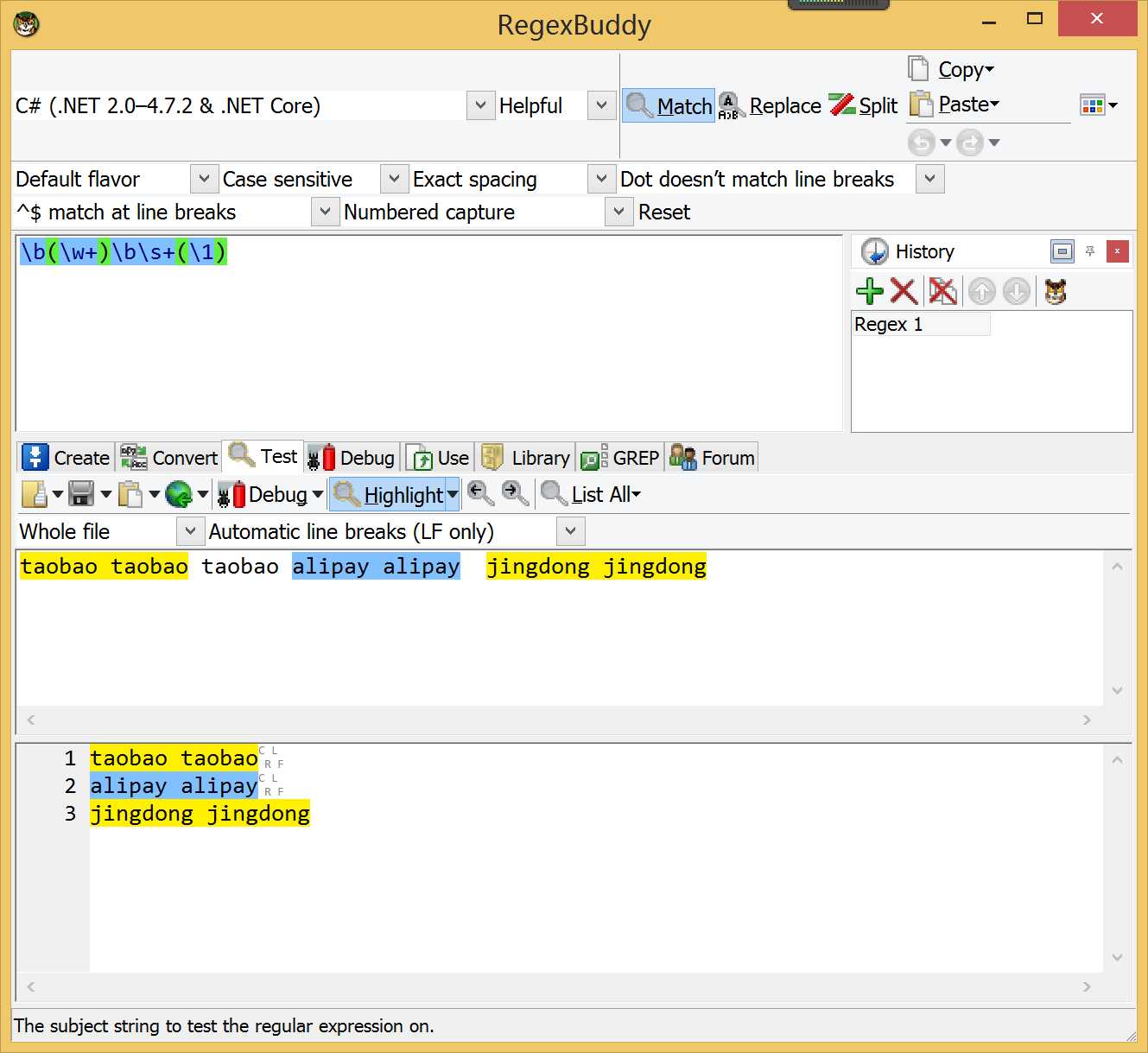
这里我们先举个例子,当我们需要匹配类似“taobao taobao”,“jingdong jingdong”这样的内容时,我们的正则表达式怎么写呢?
答: 可以使用 \b(\w+)\b\s+(\1) 来进行匹配。
下面解释一下具体的含义:这里 \b(\w+)\b 表示匹配的内容为字符串,(\1) 表示后向引用第1分组的内容进行匹配,所以,最终我们就能匹配到上面我们提到的场景的内容。
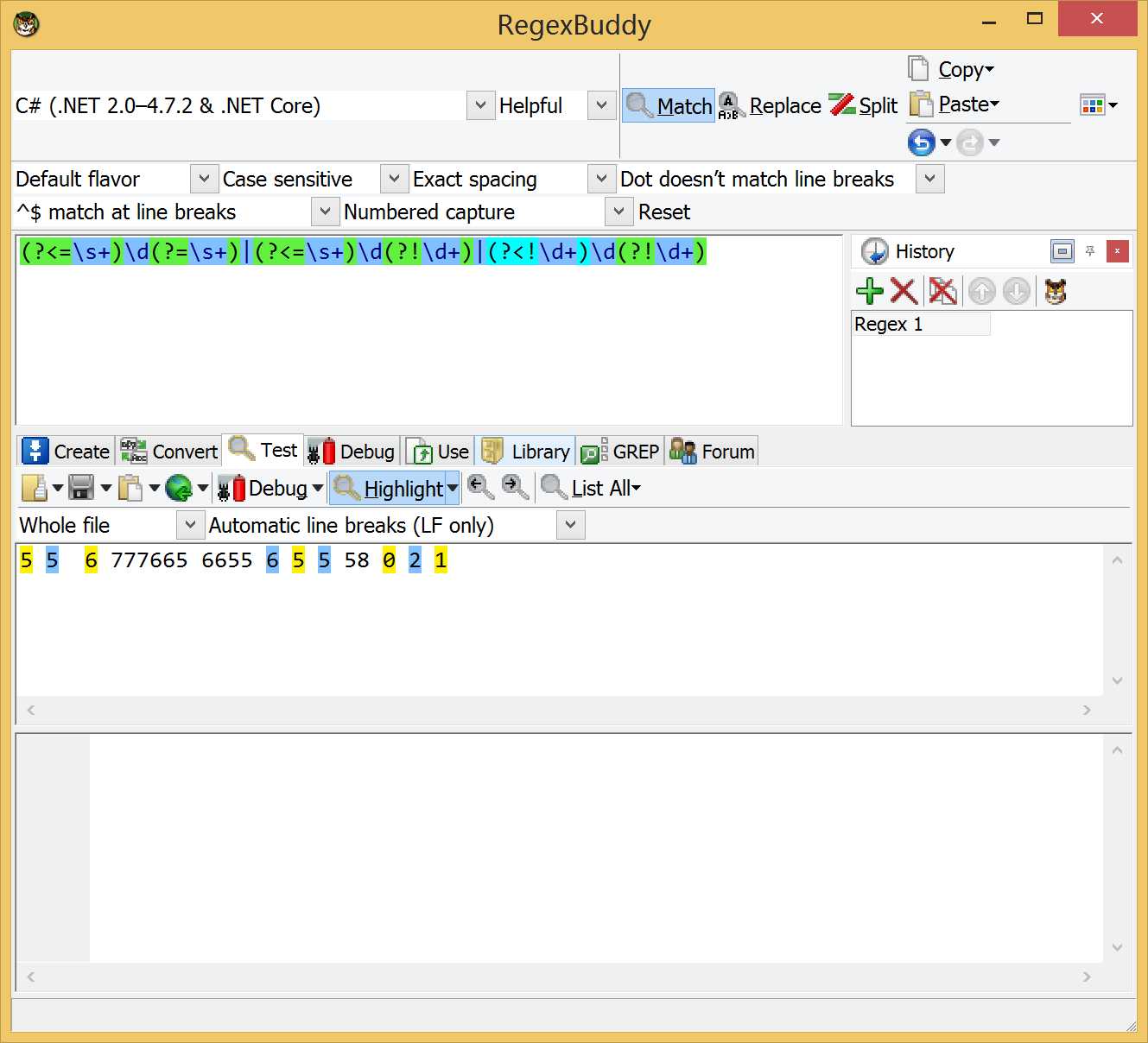
为什么会有零宽断言呢?是为了解决什么问题呢? 这个零宽断言的存在是为了解决我们一些特点的匹配要求,且不需要占位数。
零宽断言有正向、负向、先行、后行,一共有4种组合形式:
下面可以结合一个例子对零宽断言进行理解:
这里我们先提出一个匹配特定内容的问题:如何把 xx <aa <bbb> <bbb> aa> yy 这样的字符里,最长的配对的尖括号内的内容捕获出来?
这里我们可以使用平衡组递归进行匹配,思路如下:
1. 我们可以使用 (?‘group‘) 把捕获的内容命名为group,并压入堆栈(Stack)
2. 通过 (?‘-group‘)从堆栈上弹出最后压入堆栈的名为group的捕获内容,如果堆栈本来为空,则本分组的匹配失败。
3. 通过(?(group)yes|no)来判断,如果堆栈上存在以名为group的捕获内容的话,继续匹配yes部分的表达式,否则继续匹配no部分。
需要注意的是:目前仅仅 .Net 支持平衡组递归匹配,其他语言例如Java、JavaScript 目前都不支持。这里我也就不过多的展开讨论和说明了。
原文:https://www.cnblogs.com/renhui/p/13715500.html