这里简单先说一下3个锁算法,大家可以边看边理解
Record Lock:单个行记录上的锁 Gap Locks :锁定一个范围,但不包含记录本身Next-Key Locks ( Gap Lock + Record Lock):锁定一个范围,并且锁定记录本身mysql 5.7.31REPEATABLE-READ,因为间隙锁和下一键锁在RC和RU的事务隔离级别下不存在,我们使用RR才能进行展示。InnoDB所有的锁都是基于索引实现的,锁定的内容也是索引或者索引区间。
行锁的英文即Record Locks,就是对索引加锁,只影响一行。
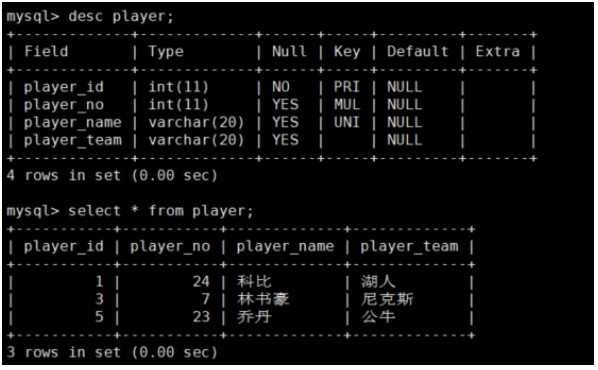
比如当我们执行:select * from player where player_id=1;
会对player_id索引加锁,锁定的范围为player_id∈[1,1]的数据行
要理解间隙锁,我认为第一步如果能够顺利的理解Gap的意思,那么后续的理解会十分顺利。我们先百度直译一下Gap的意思,直译出就是间隔,间隙的意思。
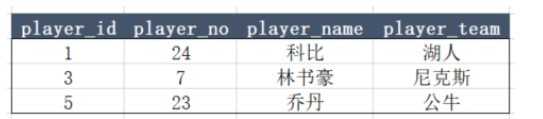
那么结合到数据库的一张表,我们又该如何理解呢?下图是一张正常的球员信息表。
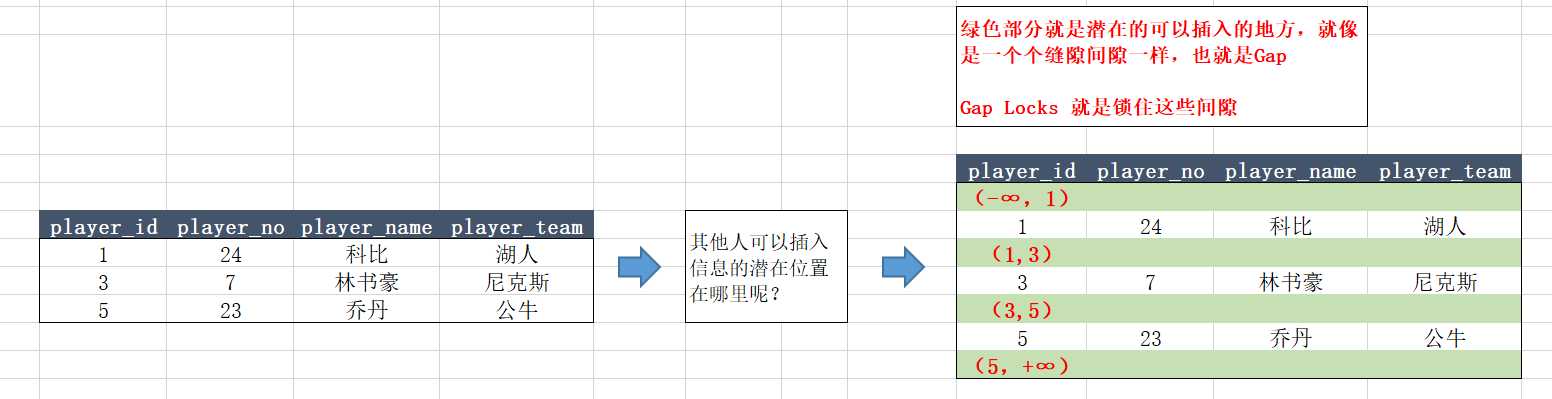
当我们希望插入一条数据的时候,肯定只能插入没有数据的地方,也就是插入到间隙里面去,如下图所示,相信到这里,大家大概对Gap Locks有一个自己的认识了。
间隙锁主要的目的是防止幻读。
幻读:在一个事务中,执行两次相同的SQL,得到了不同的结果集(新增了部分记录或者缺失了部分记录)
---------------------------------幻读 - 例子-分割线-------------------------------
player_id<=3的球员信息,这些球员的信息可能要更改,查完告诉我。科比,林书豪,此时我离开工位去吃午饭,此时还没给老板汇报,任务没结束。id=2,11,姚明,火箭player_id<=3的球员有两位,忘记了其他信息,所以我需要再次查询。---------------------------------幻读 - 例子-分割线-------------------------------
看了上面的例子相信大家对间隙锁的作用,自己也有一定的想法了。如果我在查询player_id<=3的球员信息时,不允许其他事务插入player_id<=3的新球员的话,那么吃完饭后的查询结果,依然也就只有科比和林书豪。
这时候我们再来理解下面这一句sql,他会产生怎样的间隙锁呢?
select * from player where player_id <=3;对于上方的语句,锁住的索引值也就是:(-∞,1),(1,3),(3,5),也就是说,player_id在上述三个间隙内的新球员信息暂时就不能新增了。
至于为什么要锁(3,5),因为在RR的隔离级别下,需要对比到第一个比3大的值(player_id),也就是5,才会终止。
但真实情况下,实际锁的范围是(-∞,1],(1,3],(3,5],为什么是这样,也就是接下来我们要说的下一键锁(Next-Key Locks)
当我们理解行锁和间隙锁之后,此时理解下一键锁就很简单了:
Next-Key Locks = Record Locks + Gap Locks,下一键锁就是行锁和间隙锁的组合!
这也是为什么在上方间隙锁的解释中,(-∞,1),(1,3),(3,5) 变成了(-∞,1],(1,3],(3,5]
select * from player where player_id <=3; -- 这条SQL不仅仅锁住了间隙,也需要锁住id=1,3,5的行这个时候我们再来巩固一次下一键锁的范围,就以本文中的player表为例,我们一共有哪些下一键锁的范围?
(-∞,1]
(1,3]
(3,5]
(5,+∞)执行下方sql
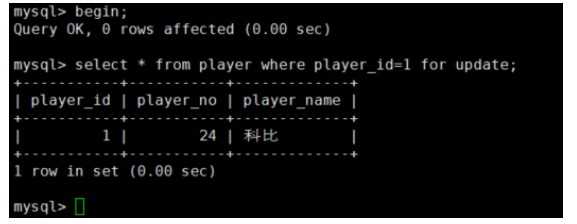
锁算法查看(通过show innodb status\G 可以查看)
绿框所框起来的:locks rec but not gap就表示此时的X锁模式是行锁

执行下方sql
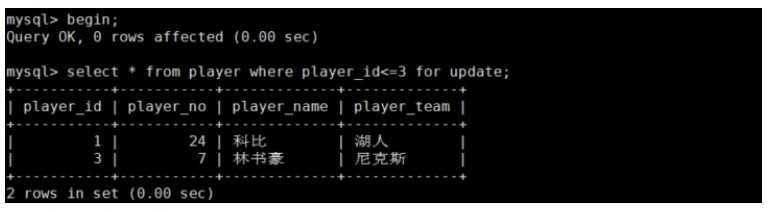
锁查看,此时可以发现有3个行锁已经出现了,锁住l了id=1,3,5的记录
此时我们测试插入一条新数据player_id=2能否成功,开启一个新的会话窗口
可以看到光标停在左下角,因为他在等待player表锁的释放,无法插入,Next-Key Lock生效
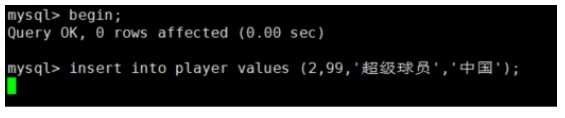
我们现在再来看一下表上的锁信息(截图不全,只截取了新生成的信息)

针对不同的索引,是否是等值查询不同的情况,不同的事务隔离级别,锁定的内容可能不同,下面汇总展示:
所有的查询都是针对同一张表
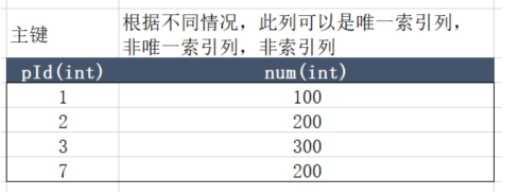
锁定情况展示:

原文:https://www.cnblogs.com/dbsqler/p/c2b509d6a4505ec6d316784247a9b226.html