参考:Deep Learning with Python P196
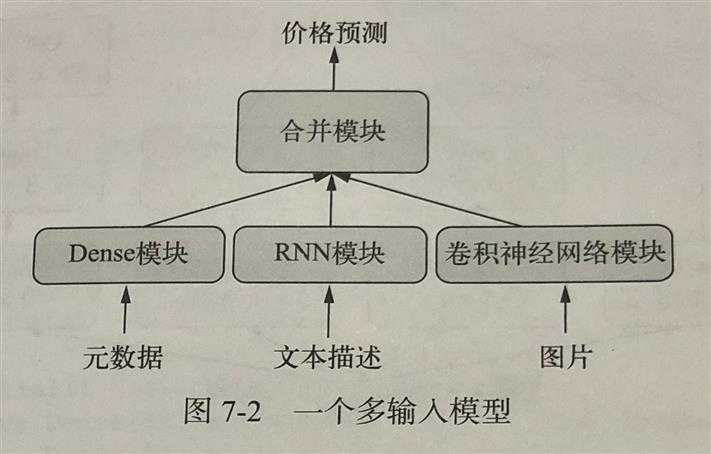
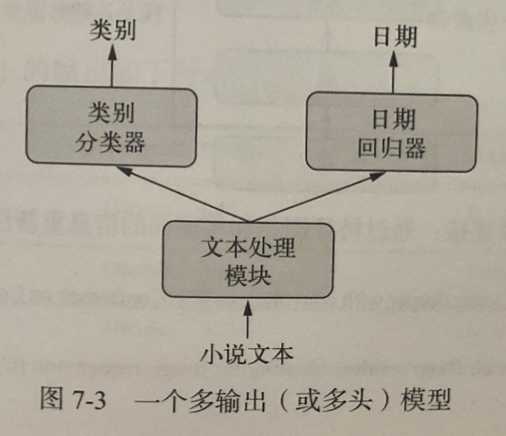
都是按照输入输出的模式,以下两种模式是一致的。
from keras.models import Sequential, Model from keras import layers, Input seq_model = Sequential() seq_model.add(layers.Dense(32, activation=‘relu‘, input_shape=(64,))) seq_model.add(layers.Dense(32, activation=‘relu‘)) seq_model.add(layers.Dense(10, activation=‘softmax‘)) input_tensor = Input(shape=(64,)) h1 = layers.Dense(32, activation=‘relu‘)(input_tensor) h2 = layers.Dense(32, activation=‘relu‘)(h1) output_tensor = layers.Dense(10, activation=‘softmax‘)(h2) model = Model(input_tensor, output_tensor) model.summary()
output
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) (None, 64) 0 _________________________________________________________________ dense_1 (Dense) (None, 32) 2080 _________________________________________________________________ dense_2 (Dense) (None, 32) 1056 _________________________________________________________________ dense_3 (Dense) (None, 10) 330 ================================================================= Total params: 3,466 Trainable params: 3,466 Non-trainable params: 0 _________________________________________________________________
对这种 Model 实例进行编译、训练或评估时,其 API 与 Sequential 模型相同。
典型的问答模型有两个输入:一个自然语言描述的问题和一个文本片段(比如新闻文章),后者提供用于回答问题的信息。然后模型要生成一个回答,在最简单的情况下,这个回答只包含一个词,可以通过对摸个预定义的词表做softmax得到。
输入:问题 + 文本片段
输出:回答(一个词)
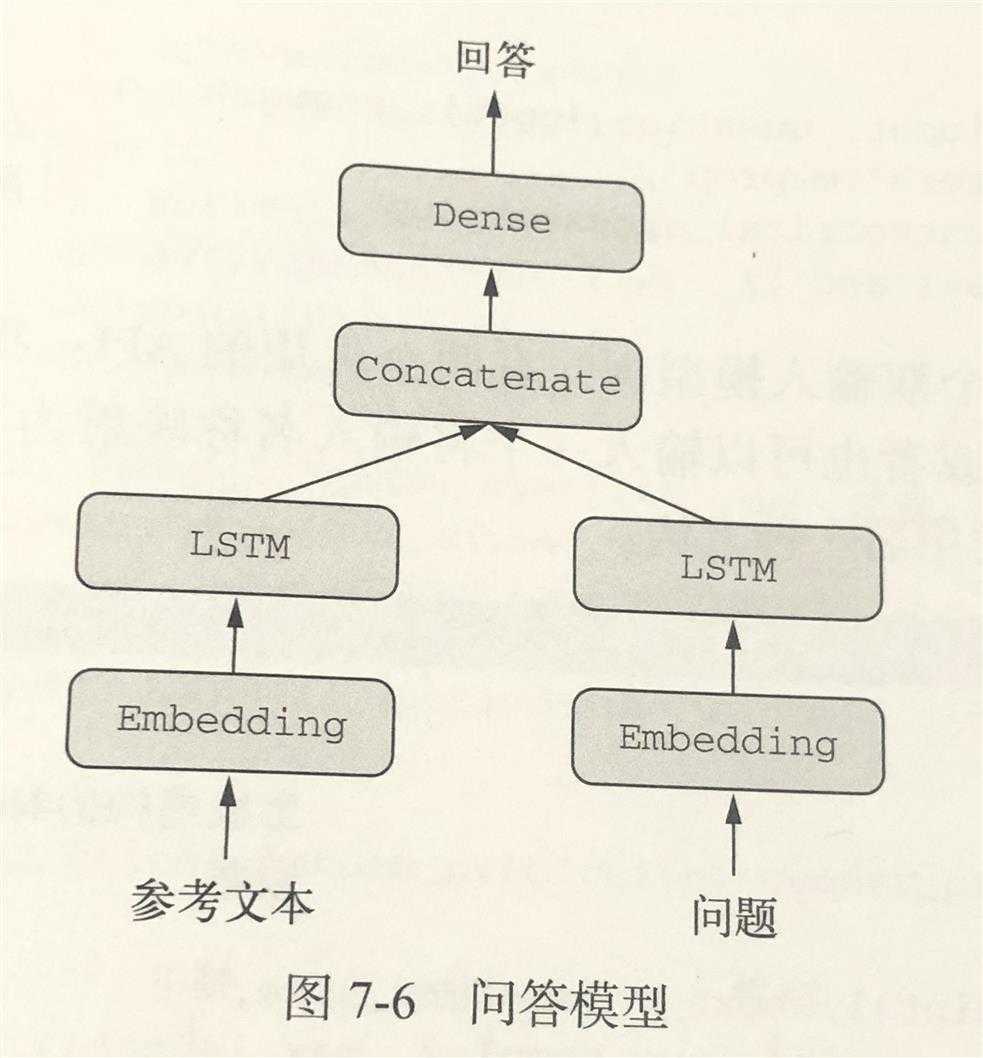
from keras.models import Model
from keras import layers
from keras import Input
text_vocabulary_size = 10000
question_vocabulary_size = 10000
answer_vocabulary_size = 500
text_input = Input(shape=(None,),
dtype=‘int32‘,
name=‘text‘)
embeded_text = layers.Embedding(text_vocabulary_size,64)(text_input)
encoded_text = layers.LSTM(32)(embeded_text)
question_input = Input(shape=(None,),
dtype = ‘int32‘,
name = ‘question‘)
embeded_question = layers.Embedding(question_vocabulary_size,32)(question_input)
encoded_question = layers.LSTM(16)(embeded_question)
concatenated = layers.concatenate([encoded_text,encoded_question],axis=-1)
answer = layers.Dense(answer_vocabulary_size,activation=‘softmax‘)(concatenated)
model = Model([text_input,question_input],answer)
model.compile(optimizer=‘rmsprop‘,
loss = ‘categorical_crossentropy‘,
metrics = [‘acc‘])
model.summary()
output:
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
text (InputLayer) (None, None) 0
__________________________________________________________________________________________________
question (InputLayer) (None, None) 0
__________________________________________________________________________________________________
embedding_5 (Embedding) (None, None, 64) 640000 text[0][0]
__________________________________________________________________________________________________
embedding_6 (Embedding) (None, None, 32) 320000 question[0][0]
__________________________________________________________________________________________________
lstm_5 (LSTM) (None, 32) 12416 embedding_5[0][0]
__________________________________________________________________________________________________
lstm_6 (LSTM) (None, 16) 3136 embedding_6[0][0]
__________________________________________________________________________________________________
concatenate_3 (Concatenate) (None, 48) 0 lstm_5[0][0]
lstm_6[0][0]
__________________________________________________________________________________________________
dense_6 (Dense) (None, 500) 24500 concatenate_3[0][0]
==================================================================================================
Total params: 1,000,052
Trainable params: 1,000,052
Non-trainable params: 0
__________________________________________________________________________________________________
训练这种模型需要能够对网络的各个头指定不同的损失函数,例如:年龄预测是标量回归任务,而性别预测是二分类任务,二者需要不同的损失过程。 但是,梯度下降要求将一个标量最小化,所以为了能够训练模型,我们必须将这些损失合并为单个标量。合并不同损失最简单的方法就是对所有损失求和。
#多输出模型的编译选项:多重损失
#方法一
model.compile(optimizer=‘rmsprop‘,
loss = [‘mse‘,‘categorical_crossentropy‘,‘binary_crossentropy‘])
#方法二
# model.compile(optimizer=‘rmsprop‘,
# loss={‘age‘:‘mse‘,
# ‘income‘:‘categorical_crossentropy‘,
# ‘gender‘:‘binary_crossentropy‘})
#多输出模型的编译选项:损失加权
#方法一
model.compile(optimizer=‘rmsprop‘,
loss = [‘mse‘,‘categorical_crossentropy‘,<br>‘binary_crossentropy‘],
loss_weights=[0.25,1.,10.])
#方法二
# model.compile(optimizer=‘rmsprop‘,
# loss={‘age‘:‘mse‘,
# ‘income‘:‘categorical_crossentropy‘,
# ‘gender‘:‘binary_crossentropy‘},
# loss_weights={‘age‘:0.25,
# ‘income‘:1.,
# ‘gender‘:10.})
不同的损失值具有不同的取值范围,为了平衡不同损失的贡献,应该对loss_weights进行设置
#将数据输入到多输出模型中
#方法一
model.fit(posts,[age_targets,income_targets,gender_targets],
epochs=10,batch_size=64)
#方法二
# model.fit(posts,{‘age‘:age_targets,
# ‘income‘:income_targets,
# ‘gender‘:gender_targets},
# epochs=10,batch_size=64)
原文:https://www.cnblogs.com/alex-bn-lee/p/13762696.html