前面我们探索了Dask是如何使用DAG在多台机器上协调和管理复杂任务的,但我们当时只是为了说明Dask和DAG之间的关联,而举了一些使用了Delayed API的简单示例罢了。而这次,我们将更深入地了解DataFrame的API。
Dask DataFrame是构建在Delayed对象上的更高级别的对象,它是围绕着pandas DataFrame对象对Delayed对象进行了包装。DataFrame API不需要你自己编写复杂的函数,因为它本身就包含了一整套转换方法,比如:笛卡尔积、join、聚合、分组等等,可以说是非常普遍的操作了,我们在后续系列会深入讨论这些操作。
首先我们一般会将数据分为两种:结构化数据和非结构化数据,其中结构化数据是由行和列组成,从简单的电子表格到复杂的关系数据库系统,结构化数据是存储信息的一种直观方式。
作为数据科学家,我们非常喜欢结构化数据,因为很容易将相关信息放在一个可视空间中。至于结构化数据我想完全没必要在概念上多费口舌,直接把它想象成数据库的一张表即可。
因此,由于结构话数据的组织和存储方式,很容易想到由许多不同的方法来操作数据。比如与人员信息的相关的结构化数据,我们可以很容易地找到最早的出身日期,过滤出与特定模式不匹配的人,根据姓名和姓氏将人员分组,或者根据年龄进行排序等等。
ids = [1, 2, 3]
names = ["夏色祭", "神乐mea", "碧居结衣"]
ages = [18, 38, 12]
我们创建了三个列表,使用pandas的我们肯定知道如何将其变成一个DataFrame,当然即使不使用DataFrame这种数据结构我们也依旧可以通过Python的方式实现相应的筛选、变换、聚合等操作,但是对于结构化数据,没有一种结构能和DataFrame一样直观,当然更准确的说应该是一个二维表。
但是对于DataFrame来说,它除了具备二维表的特征之外,还有一些额外的术语:索引和轴。我们先来看看,上面的那几个列表如果组成DataFrame的话是什么样子。
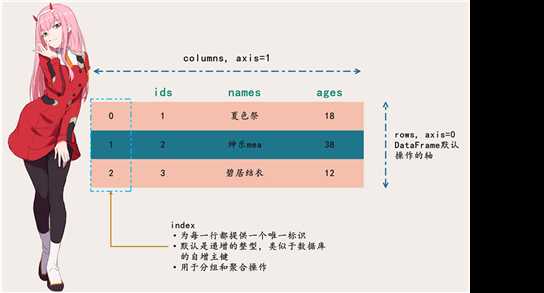
一定要注意DataFrame的轴和索引,非常重要,DataFrame的行被引用为0轴,列被引用为1轴。在对DataFrame进行聚合、分隔、拼接的时候需要注意,DataFrame默认是沿着0轴操作的,除非你显式地指定为1轴,pandas中如此,Dask中亦是如此。
关于0轴和1轴估计有人会一直犯迷糊,本来这里我们没必要说,但还是提一下吧。
一句话:沿着某个轴操作,可以看成是在该轴所在的方向上进行维度上的伸缩。
光说不练假把式,我们来使用numpy操作一下,因为0轴和1轴的概念是在numpy中先出现的。
import numpy as np
arr1 = np.array([[1, 2], [1, 2], [1, 2]])
arr2 = np.array([[3, 4], [3, 4], [3, 4]])
print(arr1)
"""
[[1 2]
[1 2]
[1 2]]
"""
print(arr2)
"""
[[3 4]
[3 4]
[3 4]]
"""
如果我们想要得到如下结果,那么我们是应该沿着0轴合并、还是沿着1轴合并呢?
[[1 2 3 4]
[1 2 3 4]
[1 2 3 4]]
答案很简单,沿着哪个轴操作,那么维度的变化就会体现在哪个轴上。这里显然是1轴的维度发生变化了,那么说明我们要沿着1轴进行合并。
print(np.concatenate((arr1, arr2), axis=1))
"""
[[1 2 3 4]
[1 2 3 4]
[1 2 3 4]]
"""
# 显然0轴还是之前的维度
如果我们对聚合之后的结果进行了sum(默认会降低一个维度),得到的一维数组的第一个元素是3,那么我们是沿着哪个轴进行的sum呢?很简单,显然是0轴,因为如果是1轴,那么sum之后第一个元素应该是1+2+3+4=10才对,所以是沿着0轴sum的,最终结果是[3, 6, 9, 12],我们看到1轴在维度上依旧没有改变。
当然我们这里的维度发生了变化,所以很好观察,但如果维度没有变化呢?同样的道理,指定哪个轴,就沿着哪个轴进行操作。
DataFrame还有一个特点就是具有索引,这个索引和数据库中的索引是类似的,但是DataFrame的索引可以不是字段的一部分。对于索引,我们最好要保证唯一性(不唯一也可以,但最好唯一),我们可以将某一个或多个字段设置为索引,也可以使用默认的自增索引。索引非常重要,我们后面会继续说,并且还会介绍常见的索引函数,总之先来看看索引是如何用来形成分区的。
正如前面提到的,pandas在分析结构化数据方面非常的流行和强大,但是它最大的限制就在于设计时没有考虑到可伸缩性。pandas特别适合处理小型结构化数据,并且经过高度优化,可以对存储在内存中的数据执行快速高效的操作。然而正如我们在一开始举的厨师的例子一样,随着数据量的大幅度增加,单机肯定会读取不下的,通过集群的方式来处理是最好的选择。这就是Dask DataFrame API发挥作用的地方:通过为pandas提供一个包装器,可以智能的将巨大的DataFrame分隔成更小的片段,并将它们分散到多个worker中,因此可以更快、更可靠地完成对巨大数据集的操作。
Dask DataFrame会被分割成多个部门,每个部分称之为一个分区,每个分区都是一个相对较小的DataFrame,可以分配给任意的worker,并在需要复制时维护其完整血统。关于操作我们之前已经见到了,就是对每个分区单独操作(多个机器的话则可以并行),然后再将结果合并,其实从直观上也能推出Dask肯定是这么做的。
因为分区对性能可以产生如此大的影响,所以你或许会认为管理分区是一件非常苦难且乏味的事情。但是不要担心:Dask会尝试通过一些明智的默认值和启发式方法,帮助你在不需要手动调优的情况下获得尽可能多的性能。例如:当使用read_csv读取数据时,每个分区的默认大小是64MB(这也是默认块大小,当然早期的Hadoop也是这样的)。对于现在机器来说,即便是个人使用的笔记本一般也是16G内存,64MB似乎有点小啊,但这里的64MB不是针对内存而言,而是因为它可以在网络间快速的传输。如果数据量过大,那么在还没等数据传输完毕,某台机器可能就处理完任务了,那么之后就只能傻等着。所以每一个块默认是64MB,虽然小,但是源源不断,细水长流。另外,分区的数量我们也可以自己指定,在创建DataFrame时通过npartitions参数指定即可。
from faker import Faker
f = Faker(locale="zh_CN")
df = pd.DataFrame({"name": [f.name() for _ in range(10)],
"province": [f.province() for _ in range(10)],
"job": [f.job() for _ in range(10)]})
df
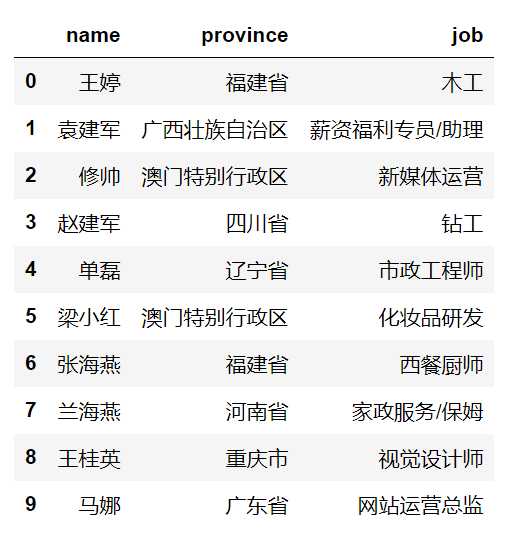
这是一个pandas的DataFrame,想要操作的话都是对整体进行操作的,然后我们来将其转成Dask中DataFrame。
dask_df = dd.from_pandas(df, npartitions=2)
dask_df
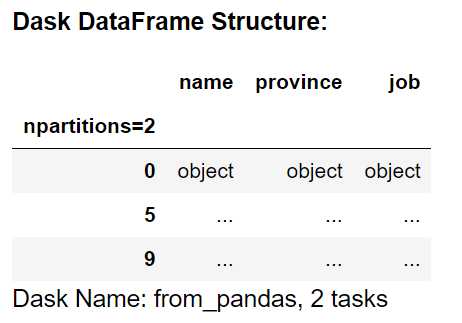
我们通过dd.from_pandas将pandas的DataFrame转成了Dask的DataFrame,这里我们显式的指定了两个分区,但是通常Dask会将其放入到单个分区中,因为它非常小。
此外我们还可以通过其它API,来检查Dask DataFrame的分区信息。
dask_df.divisions # (0, 5, 9)
dask_df.npartitions # 2
这里的divisions和npartitions是很有用的属性,因为它可以检测DataFrame是如何分区的。第一个属性:divisions(0,5,9),显示了分区的边界(注意:分区是在索引上创建的)。可能你奇怪了,明明是两个分区,为什么边界里面会有三个值。其实聪明如你一定想到了,通过(0, 5, 9)可以得到[0, 5]和[5, 9],所以这表示第一个分区处理索引为0到索引为5(不包括)的行,第二个分区处理索引为5到索引为9(包括)的行。
很好理解,当然注意了:只有最后一个分区会包含两个边界,其它分区只包含上边界、但是不包含下边界。
第二个属性:npartitions,这个没啥可说的,就是返回分区数量。
dask_df.map_partitions(len).compute()
"""
0 5
1 5
dtype: int64
"""
通过map_partitions可以对每一个分区都作用相同的函数,类比pandas中的map。pandas中的map是对整体数据集,map_partitions是对每一个分区,同样的道理。当然这个和spark也是类似的,spark中的RDD也是有分区的,对RDD使用map会作用在RDD的每一个分区上。所以我们上面相当于是计算每个分区中的行数,由于有两个分区,所以返回的Series对象长度为2,而且结果都是5,表示Daks将DataFrame分成相等的两部分。
但有时我们需要动态改变分区的数量,如果我们有一步过滤数据的操作的话,那么执行之后就会导致每个分区的数据量不一样,从而对后续操作产生负面影响。因为如果某个分区包含大量的数据,那么并行性的优势将会大大降低。
# 筛选出名字长度大于2的
dask_df_filter = dask_df[dask_df["name"].str.len() > 2]
dask_df_filter.map_partitions(len).compute()
"""
0 2
1 4
dtype: int64
"""
此时一个分区有两个数据,另一个分区有4个,此时就会不均衡。当然这个数据量比较少,所以看起来没啥影响,但如果数据量非常大的话,在过滤的时候就会出现分区数据不均衡的情况。
# 调用repartition可以对分区进行重塑
dask_df_reduce = dask_df_filter.repartition(npartitions=1)
dask_df_reduce.map_partitions(len).compute()
"""
0 6
dtype: int64
"""
只需要指定分区的数量,Dask就知道自己该怎么做,并保证各个分区间数据量的平衡。如果指定的分区小于现有的分区数,那么Dask将通过连接将现有分区合并起来;如果指定的分区数量大于现有的分区数,那么Dask将把现有分区分割为更小的分区。我们可以在任意时刻调用repartition来重塑分区,但是它和其它的Dask操作一样是属于惰性计算。在我们进行compute、head之前,不会实际移动任何数据。
# 这个时候我们再将分区指定为2的话
dask_df_filter.repartition(npartitions=2).map_partitions(len).compute()
"""
0 2
1 4
dtype: int64
"""
如果再恢复到原来的分区数,我们看到每个分区内数据的行数会和原来保持一致。
事实上,如果你了解spark的话你会很熟悉这个概念,因为shuffle也是spark中出现的。shuffle是一个耗时的操作,至于为什么我们来介绍一下。在分布式计算中,shuffle是将所有分区广播给所有worker的过程,当我们执行排序、分组、索引等操作,shuffle是必须的,因为DataFrame的每一行都要和其它行进行比较,来确定正确的相对位置。所以这是一个在时间上代价比较昂贵的操作,因为它需要在网络上传输大量数据。
比如我们要按照某个字段进行聚合,显然此时就不可以每个分区单独进行了。假设我们要给salary这个字段的值加100,那么每个分区之间可以单独操作,彼此之间是不受影响的;但如果要是按照salary进行聚合来计算count,那么不好意思,此时就不是每个分区单独处理所能解决的了的,比如我们有五个分区,每个分区都有salary为8000的值,这个时候统计的话就需要将值在分区之间进行发送,所以它是一个比较昂贵的操作。而且从名字上也能看出来,shuffle有洗牌的意思,如果把每一条数据想象成一张扑克牌,那么shuffle操作是不是需要将多个分区的数据混合在一起呢。而一旦多个分区的数据需要进行交互,那么就意味着数据的传输,即网络IO,所以它是比较耗时的。
再比如排序,显然排序也是一个shuffle的操作,因为要涉及所有数据之间的对比。由于我们需要对数据进行各种操作,因此想完全避免shuffle是不太现实的,但是我们可以做一些事情来执行shuffle操作的数据量达到最小,比如确保数据在存储的时候就是有序的,即可消除使用Dask对数据进行排序的需要。如果可能的话,我们可以在源系统(比如关系型数据库)中进行排序,这样会比在分布式系统中排序更快、更有效。其次,使用排序列作为DataFrame的索引将提高连接的效率。所以数据排序之后的查找速度会非常快,因为可以通过DataFrame上定义的分区轻松确定某一行的分区位置。最后,如果必须触发shuffle的操作,那么在资源允许的情况下可以对结果持久化,这样如果需要重新计算的话可以避免数据之间的再次移动。
现在相信你已经对DataFrame API的用途有了一个很好的了解,那么最后再介绍一下Dask DataFrame的一些限制吧。
首先也是最重要的,Dask DataFrame不会暴露pandas DataFrame的所有API,即使Dask DataFrame是由多个小型的pandas DataFrame组成的,因为pandas的一些功能虽然很好但却并不适合分布式环境。例如:改变数据格式的函数,insert和pop就不支持,因为Dask数据格式是不可变的。这和spark中的RDD也是一样的,每个RDD也是不可变的,如果想变,那么只能生成一个新的RDD。但是pandas的DataFrame则不一样,我们举个栗子:
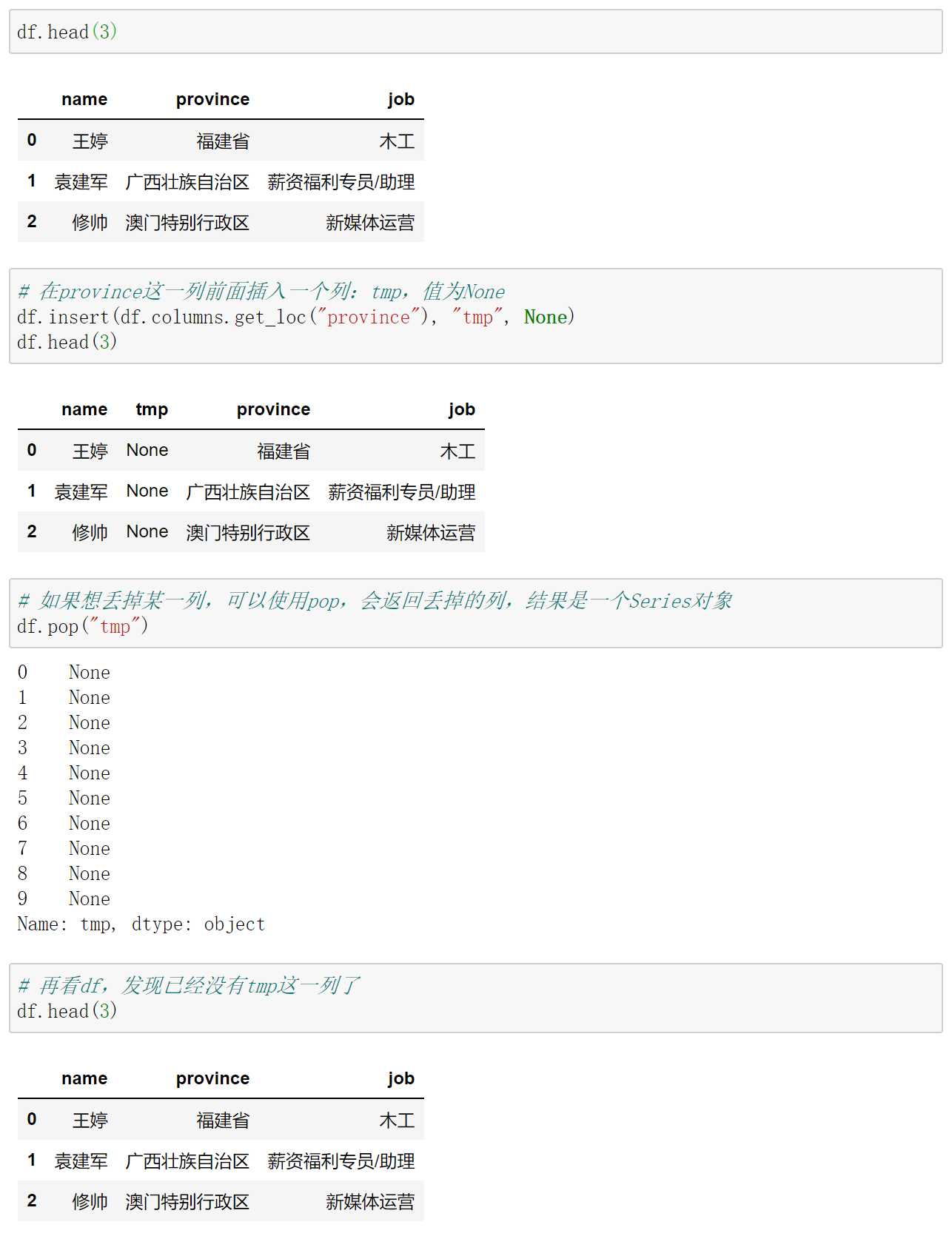
pandas是支持本地修改的,当然还有很多其它的操作也支持使用inplace参数来实现原地修改,但是对于Dask DataFrame也是不允许的,而且大型数据集也根本不适合这种灵巧的变换。一些更复杂的窗口操作也不被支持,比如:expanding和ewm方法,还有像stack和unstack这种方法也不支持,因为它们往往会导致大量的shuffle。通常这些昂贵的操作并不需要在完整的原始数据集上运行,你应该使用Dask来完成所有常规的数据准备、过滤和转换,然后将最终的数据集交给pandas。然后你可以对转化后的数据执行这些对于分布式来说非常昂贵的操作了(但对于pandas而言则没有什么昂贵的),Dask DataFrame和pandas DataFrame之间的交互非常容易,因此在使用Dask DataFrame分析数据时这个操作将会非常有用。
第二个受限制的地方是关系型操作,比如:join、merge、group by,以及rolling。尽管这些操作Dask DataFrame也是支持的,它们可能会涉及大量的shuffle,而成为程序的性能瓶颈。因此可以让Dask专注于其它操作,将数据量减小能够交给pandas,然后让pandas来执行这些操作;或者使用Dask执行这些操作的时候,只将它们作用在索引上。比如有两个DataFrame,一个与人员有关,一个与交易有关,按照person ID进行merge,那么我们可以将person ID作为索引并排好序,这样merge的时候速度会明显加快。
第三个受限制的地方就是索引方面会有一些挑战,如果你希望使用DataFrame中的列作为索引,来代替默认的数值索引的话,那么这个列最好是被排过序的,否则的话整个DataFrame会因为它进行大量的shuffle操作。因此最好的办法就是我们在构建数据的时候,就保证它是有序的,这样在计算时能够节省大量的时间。
在Dask处理reset_index这个方法时,你可能会注意到和pandas之间有一个明显的区别,pandas是在整个DataFrame中计算新的顺序索引,而Dask DataFrame中reset_index则类似于map_partitions。这意味着每个分区都有自己的从0开始的顺序索引,我们可以看一下Dask DataFrame在使用reset_index之后的样子。
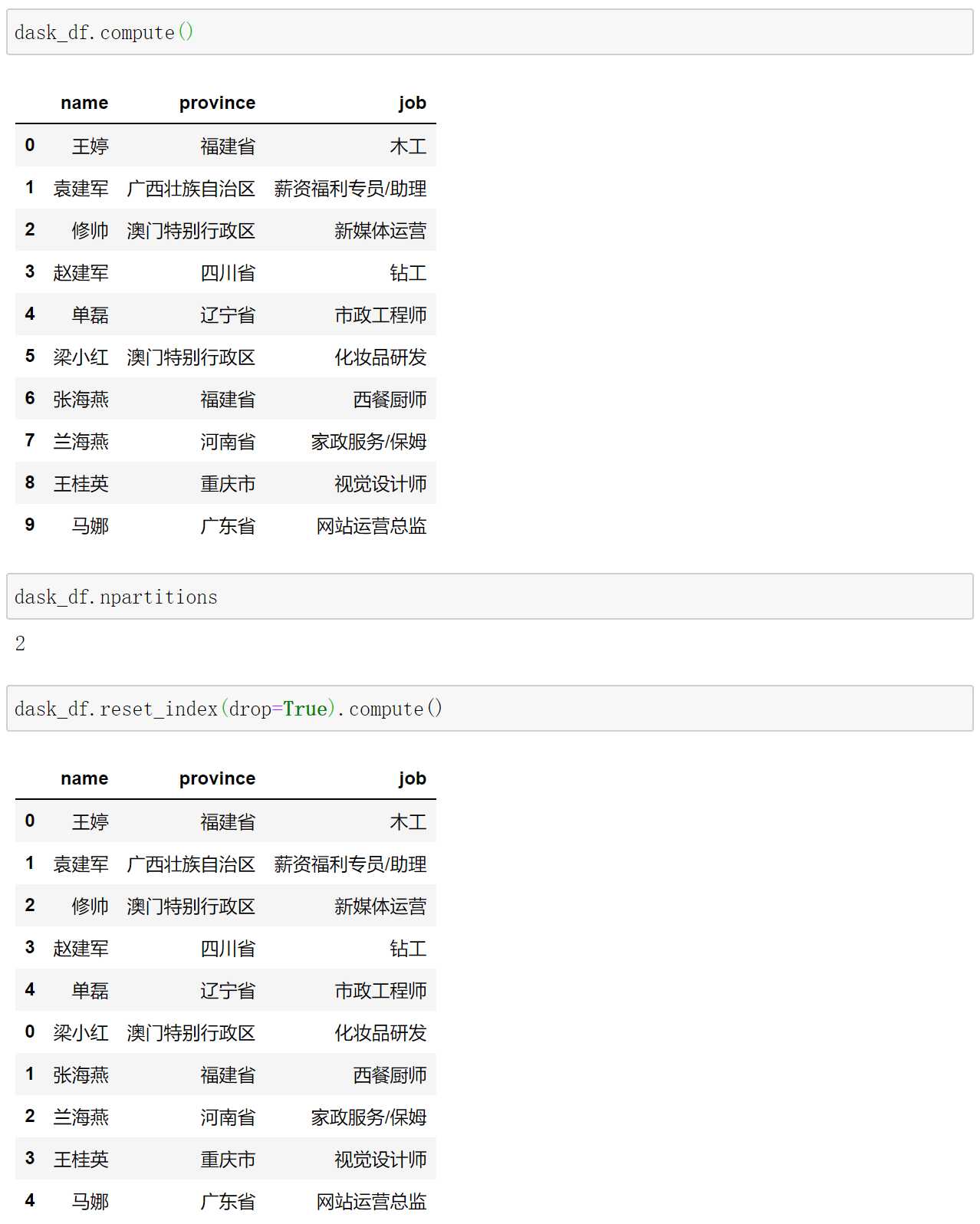
在reset_index之后,索引会变成从0开始的自增索引。但是对于Dask DataFrame而言,它是每一个分区都作用上reset_index,所以两个分区的索引都是0 1 2 3 4,因为它们都有5行记录。那么可不可以对整体所有分区进行reset_index呢?就像pandas那样作用在所有数据集上,答案很不幸,没有一种简单的办法能做到这一点。因此使用reset_index的时候一定要小心,使用reset_index就意味着你不打算使用索引来对DataFrame进行join、group、sort等操作。
最后,由于Dask DataFrame是由多个pandas DataFrame组成的,因此在pandas中效率低下的操作在Dask中效率也会同样低下。例如:通过apply和iterrows方法进行迭代在pandas中效率非常低,因此在使用Dask DataFrame时遵循pandas DataFrame的优化原则的话将会给你带来最佳的性能体验。如果你已经熟悉了pandas,那么使用Dask将会是一件很轻松的事情,而且不仅可以让你更好地理解pandas,还能让你熟悉Dask和分布式原理。
《使用Python和Dask实现分布式并行计算》3. Introducing Dask DataFrame(介绍Dask DataFrame)
原文:https://www.cnblogs.com/traditional/p/13766079.html