当你做过代码冗余却没有注释没有日志的系统,你就越发明白日志的重要性!一个完善的日志体系应该是如下这样:
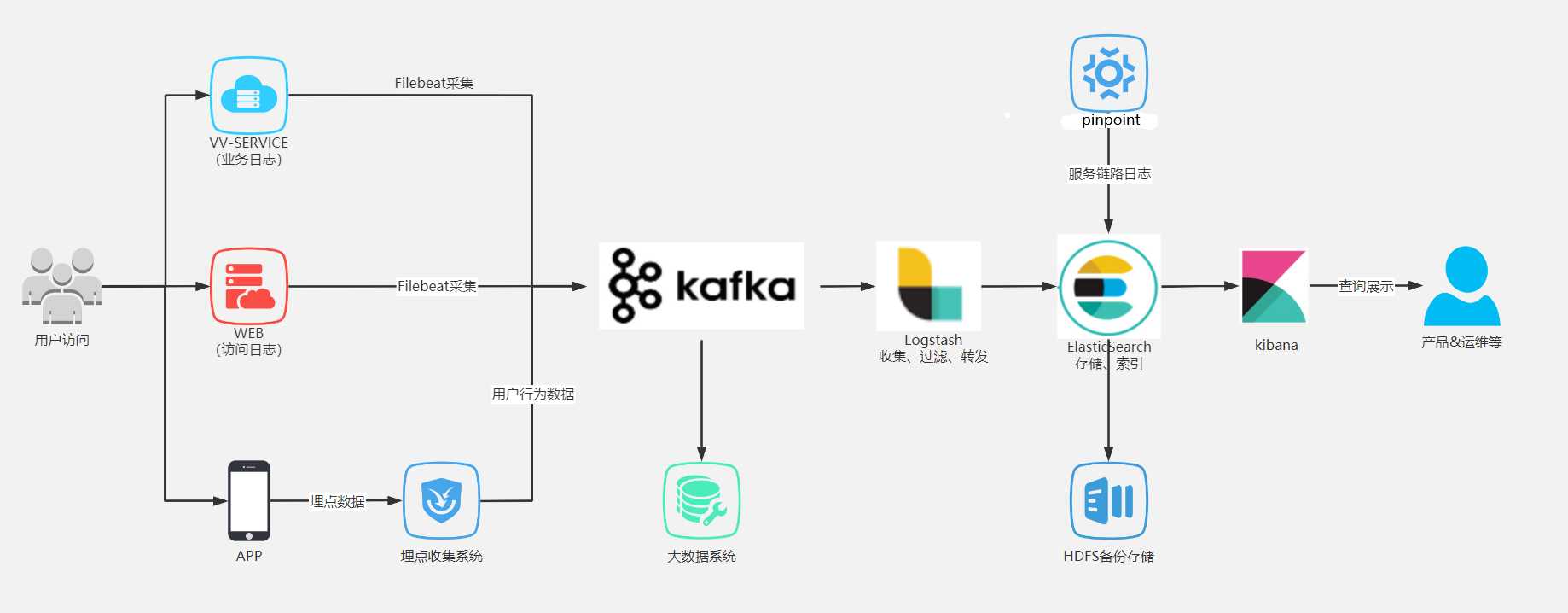
FileBeat是一个日志文件托运工具,在你的服务器上安装客户端后,filebeat会监控日志目录或特定的日志文件,追踪读取这些文件
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以消费者规模的网站中所有动作流量
Logstash是一根具备实时数据传输能力的管道,负责将数据信息从管道的输入端传输到管道的输出端;与此同时,这根管道还可以让你根据自己的需求在中间加上滤网,logstash提供很多功能强大的滤网
ElasticSearch提供了一个分布式多用户能力的全文搜索引擎,基于REESTful web接口
Kibana是elasticSearch的用户界面
在实际场景下,为了满足大数据实时检索的场景,利用filebeat去监控日志文件,将Kafka作为filebeat的输出端,Kafka实时接收filebeat后以logstash作为输出端输出,到logstash的数据也许还不是我们想要的格式或特定的业务数据,这时可以通过logstash的一些过滤插件对数据进行过滤最后达到想要的数据格式以elasticSearch作位输出端输出,数据到elasticSearch就可以进行丰富的分布式检索了。kibana可以将elasticSearch里的数据很好地展示给用户使用。
转载连接:https://mp.weixin.qq.com/s/bvmKAIMhljL3z8vqOeIsAQ
1 version: ‘3‘ 2 services: 3 elasticsearch: 4 image: elasticsearch:6.4.0 5 container_name: elasticsearch 6 environment: 7 ‐ "cluster.name=elasticsearch" #设置集群名称为elasticsearch 8 ‐ "discovery.type=single‐node" #以单一节点模式启动 9 ‐ "ES_JAVA_OPTS=‐Xms512m ‐Xmx512m" #设置使用jvm内存大小,稍微配置大点,不然有可能启动不成功 10 volumes: 11 ‐ /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins #插件文件挂载 12 ‐ /mydata/elasticsearch/data:/usr/share/elasticsearch/data #数据文件挂载 13 ports: 14 ‐ 9200:9200 15 ‐ 9300:9300 16 kibana: 17 image: kibana:6.4.0 18 container_name: kibana 19 links: #同一个compose文件管理的服务可以直接用服务名访问,如果要给服务取别名则可以用links实现,如下面的es就是elasticsearch 服务的别名 20 21 ‐ elasticsearch:es #可以用es这个域名访问elasticsearch服务 22 depends_on: 23 ‐ elasticsearch #kibana在elasticsearch启动之后再启动 24 environment: 25 ‐ "elasticsearch.hosts=http://es:9200" #设置访问elasticsearch的地址 26 ports: 27 ‐ 5601:5601 28 logstash: 29 image: logstash:6.4.0 30 container_name: logstash 31 volumes: 32 ‐ /mydata/logstash/logstash‐springboot.conf:/usr/share/logstash/pipeline/logstash.conf #挂载logstash的配置文件,dock er对单个文件的挂载需要先在宿主机建好对应文件才能挂载成功 33 depends_on: 34 ‐ elasticsearch #kibana在elasticsearch启动之后再启动 35 links: 36 ‐ elasticsearch:es #可以用es这个域名访问elasticsearch服务 37 ports: 38 ‐ 4560:4560
原文:https://www.cnblogs.com/powerZhangFly/p/13791723.html