Faster RCNN算法利用了两阶结构, 先实现感兴趣区域的生成, 再进行精细的分类与回归, 虽出色地完成了物体检测任务, 但也限制了其速度, 在更追求速度的实际应用场景下, 应用起来仍存在差距。
在此背景下, YOLO v1算法利用回归的思想, 使用一阶网络直接完成了分类与位置定位两个任务, 速度极快。 随后出现的YOLO v2与v3检测精度与速度上有了进一步的提升, 加速了物体检测在工业界的应用, 开辟了物体检测算法的另一片天地。
1. 无锚框预测: YOLO v1
相比起Faster RCNN的两阶结构, 2015年诞生的YOLO v1创造性地使用一阶结构完成了物体检测任务, 直接预测物体的类别与位置, 没有RPN网络, 也没有类似于Anchor的预选框, 因此速度很快。 本节将详细介绍YOLO v1的网络结构与算法思想。
1.1 网络结构
与其他物体检测算法一样, YOLO v1首先利用卷积神经网络进行了特征提取, 具体结构如图6.1所示, 该结构与GoogLeNet模型有些类似。在该结构中, 输入图像的尺寸固定为448×448, 经过24个卷积层与两个全连接层后, 最后输出的特征图大小为7×7×30。
关于YOLO v1的网络结构, 有以下3个细节:
·在3×3的卷积后通常会接一个通道数更低的1×1卷积, 这种方式既降低了计算量, 同时也提升了模型的非线性能力。
·除了最后一层使用了线性激活函数外, 其余层的激活函数为Leaky ReLU。
·在训练中使用了Dropout与数据增强的方法来防止过拟合。

1.2 特征图的意义
YOLO v1的网络结构并无太多创新之处, 其精髓主要在最后7×7×30大小的特征图中。 如图6.2所示, YOLO v1将输入图像划分成7×7的区域, 每一个区域对应于最后特征图上的一个点, 该点的通道数为30, 代表了预测的30个特征。
YOLO v1在每一个区域内预测两个边框, 如图6.2中的预测框A与B, 这样整个图上一共预测7×7×2=98个框, 这些边框大小与位置各不相同, 基本可以覆盖整个图上可能出现的物体。

如果一个物体的中心点落在了某个区域内, 则该区域就负责检测该物体。 图6.2中真实物体框的中心点在当前区域内, 该区域就负责检测该物体, 具体是将该区域的两个框与真实物体框进行匹配, IoU更大的框负责回归该真实物体框, 在此A框更接近真实物体。
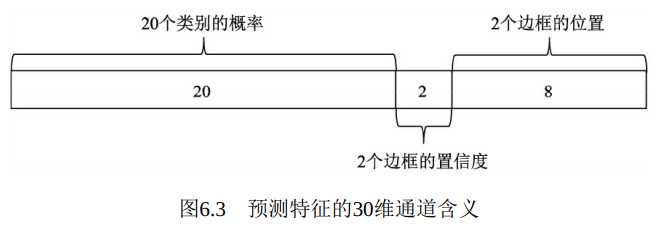
最终的预测特征由类别概率、 边框的置信度及边框的位置组成, 如图6.3所示。 这三者的含义如下:
·类别概率: 由于PASCAL VOC数据集一共有20个物体类别, 因此这里预测的是边框属于哪一个类别。
·置信度: 表示该区域内是否包含物体的概率, 类似于Faster RCNN中是前景还是背景。 由于有两个边框, 因此会存在两个置信度预测值。
·边框位置: 对每一个边框需要预测其中心坐标及宽、 高这4个量,两个边框共计8个预测值。
这里有以下3点值得注意的细节:
·YOLO v1并没有先验框, 而是直接在每个区域预测框的大小与位置, 是一个回归问题。 这样做能够成功检测的原因在于, 区域本身就包含了一定的位置信息, 另外被检测物体的尺度在一个可以回归的范围内。
·从图6.3中可以看出, 一个区域内的两个边框共用一个类别预测,在训练时会选取与物体IoU更大的一个边框, 在测试时会选取置信度更高的一个边框, 另一个会被舍弃, 因此整张图最多检测出49个物体。
·YOLO v1采用了物体类别与置信度分开的预测方法, 这点与Faster RCNN不同。 Faster RCNN将背景也当做了一个类别, 共计21种, 在类别预测中包含了置信度的预测。
原文:https://www.cnblogs.com/zhaopengpeng/p/13803295.html