目标达成:
1.楷体中文常用3500字
2.Times New Roman 英文+数字
之前训练的困难点是准备的图片不符合要求,对于其训练的过程和特点不甚理解,在准备字体图片上止步不前。偶然的kexue上网,ytb上的jTessBoxEditor.jar使用,可以通过tiff/box Generator这个选项生成符合预期的tiff文件,顺带着还会生成box文件,大大降低了难度。
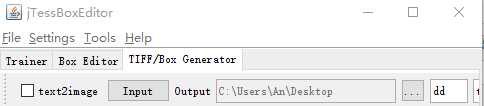
选项中可以调整汉字的大小(tiff图片中文字大小)、字体,generate成功会生成三个文件,font+box+tif。
接下来的操作都差不多,命令行,或者这个java工具的Trainer选项应该都能完成目标,暂时没有用过Trainer选项实现。
存在的疑惑在于,--psm参数在训练时的影响到底有多大,tran文件最后到底是什么格式生成,后期还需继续研究。
接下来的目标:
阅读源码,理解每一步训练操作形成数据交互的过程。
理论上应该一个字符对应一条记录或者多条记录,后期的重点在于解析这每一条记录的形成过程。
原文:https://www.cnblogs.com/mracezhang/p/13803964.html