无相关工作内容
https://www.aclweb.org/anthology/P19-1440/
解决任务: 复杂问题语义解析(基于ComplexWebQ)。提出层次语义解析方法。
三个阶段:

对复杂问题的分解存在问题:
论文中提出的模型是直接生成完整的子问题。
层次语义解析 HSP 是一个 SeqtoSeq 结构,其潜在的思想即是分解和集成。
Input :复杂问题输入
Output : 逻辑形式
复杂问题输入:\(x = \{x_1,...,x_{|x|}\}\)
逻辑形式: \(y = \{y_1, ... , y_{|y|}\}\)
为了产生更好的逻辑形式,模型使用两种类型的中间表示:
DR: 分解表示,表示为 \(z = \{z_1, ... , z_{|z|} \}\)
SR: 语义表示,表示为 \(w = \{w_1, ..., w_{|w|}\}\)
每个训练样本表示为 \(<x, y, z, w>\) 四元组。

模型的基础结构:
解析单元,解析单元包括编码网络和解码网络,是基于 Transformer 的多头注意力机制的编解码器。
输入:输入序列 \(a = \{a_1, ... , a_{|a|}\}\) + 额外信息 \(e = \{e_1, ... , e_{|e|}\}, e_i \in R^n\)
输出: 解析目标序列 \(o = \{o_1, ... , o_{|o|}\}\)
编码:
将输入序列 \(a\) 编码到上下文表示 \(h = \{ h_1, ... , h_{|a|}\}, h_i \in R^m\), 然后使用 L 层 Transformer 编码器生成输出:
解码:
解码器得到 \(h\) 和输入的额外信息 \(e\) ,连接形成表示 \([h, e]\)。
在解码器时间步 t , 对 \([h, e]\)以及之前所有输出 \(o_{<t} = \{o_1,...,o_{t-1}\}\),解码器计算条件概率 \(P(o_t|o_{<t}, [h,e])\)
第一个解码嵌入函数 \(f_{dec}^{emb}\) 将之前输出\(o_{<t}\)映射到词向量,增加位置编码,得到词表示。
解码器也堆叠L个相同的层,单词表示和 \([h, e]\)一起被馈送到这些层。
将第 \(l\) 层,位置 \(j\) 的输出向量表示为\(k_j^l\) ,将第 \(l\) 层的第 \(j\) 个位置前的输出向量表示为 \(k_{<=j}^l = \{k_1^l, ..., k_j^l\}\) ,解码层的输出为\(k_j^l = Layer(k_{<=j}^{l-1}, [h, e])\)
给出最后一层的输出 \(k_j^L\), 对当前词 \(P_{vocab}^j(w)\)的概率计算如下式,其中,\(V = \{w_1,...,w_{|v|}\}\),\(W_o, b_o\)为参数:
解码过程由[BOS]触发,由[EOS] token结束。
复制机制
为了解决OOV单词(不在词汇表中的单词)产生的问题,在解码器中应用了复制机制。
之后计算复制概率 \(P_{copy}^t \in [0,1]\),如下式所示, \(W_q, W_g, b_g\)是可学习的参数:
使用\(P_{copy}^t\)计算复制概率的加权和,生成概率得到扩展词汇表\(V + X\) 的最终预测概率。其中,\(X\) 是源序列\(a\)的OOV词集:
解码过程由下述公式计算得出,其中,使用 \(f_{dec}^t\) 表示具有复制机制解码器的一个时间步。
损失函数: \(L(\theta) = \frac{1}{T} \sum_{t=1}^{T} - logP(o_t=o_t^*|a,e,o_{<t})\)
输入:\(x\)
输出的逻辑形式:\(y\)
训练目标: 上述损失函数的训练目标使条件概率\(P(y|x)\)和目标序列的真实概率\(P(y^*)\)的交叉熵最小。
HSP机制通过将目标转化为多个条件概率的乘积,将这个过程分为多阶段任务。对HSP模型,目标是\(P(y|x,z,w)P(w|x,z)P(z|x)\),z和w表示分解表示和语义表示。
问题分解:
HSP的第一阶段。将复杂问题->简单问题序列
输入:复杂问题\(x\)
输出:分解表示\(z\)
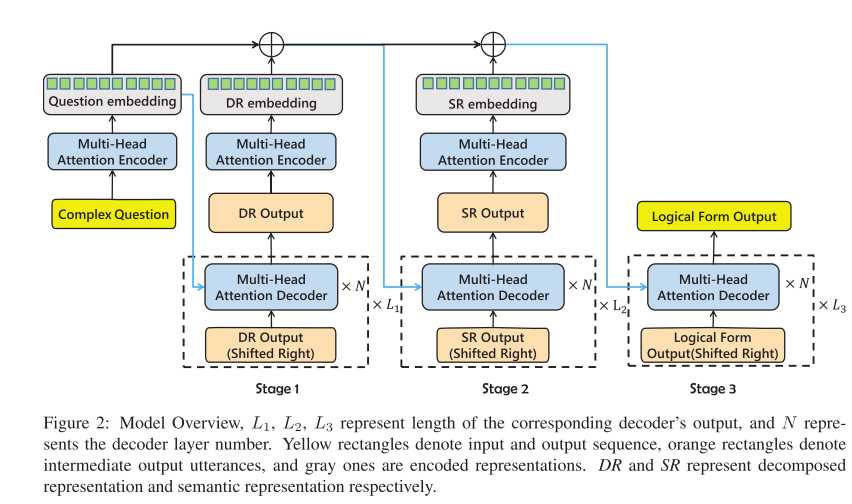
图2中的解码过程可以分为多个时间步,对每个时间步,之前的输出被右移并输入解码层,蓝色线的起点是解码器的融合表示,对问题分解来说,这个融合表示就是问题嵌入(question embedding)。
信息提取
HSP的第二阶段从复杂问题(复杂问题本身和第一阶段分解出的简单问题序列)中提取关键信息。
输入:分解表示(上一阶段的输出结果\(z\))和问题嵌入。
输出:语义表示 \(w\)
图2中的⊕表示融合过程,也就是concat,直接连接。
语义解析
HSP的最后一个阶段,它收到复杂问题的上下文感知嵌入,分解表示和语义表示序列,输出最后的逻辑形式。
损失函数:
其中,\(\lambda_1,\lambda_2\)为超参数。
在学习过程中,模型使用三阶段学习过程。
获得的每个序列都是使用贪心搜索方法,比如beam search。
建立了一个包括复杂问题,所有中间表示和逻辑形式的词汇表。词汇表由语料中出现多余4次的词组成,所有的OOV单词表示为UNK。
使用Glove词向量,如果是[UNK]、[BOS]、[EOS],则是随机值。在训练中,所有的词向量也会随之更新。
HPS在编码嵌入时,使用预训练好的StanfordCoreNLP POS模型。使用分类词性标注,并将词性映射到30维向量,POS向量由均匀分布U(-0.1, 0.1)随即生成,在之后的训练过程中随之更新。POS向量与词向量连接形成词表示。
编码和解码的所有hidden layer设置为300。所有编码层和解码层由相同的6层堆叠而成。优化器 Adam(\(\beta_1=0.9,\beta_2=0.98,\epsilon=10-9\)),使用动态学习率。
正则化:dropout=0.2和label smoothing=0.1
train-27734 dev-3480 test-3475
【KBQA 论文阅读】2019 - [ACL] - Complex Question Decomposition for Semantic Parsing
原文:https://www.cnblogs.com/xjfbeta/p/13813620.html