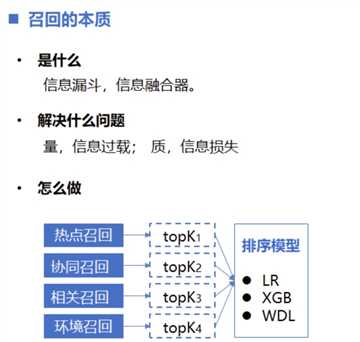
召回系统,本质上是个信息漏斗,负责快速从海量信息中筛选出有价值的信息,缩小排序算法的搜素范围(解决了信息过载的问题);
也负责将多路召回的数据,进行融合(相当于一个信息融合器,解决了单路召回特征单一,信息量小,多样性差的问题),得到一个精简的候选集。
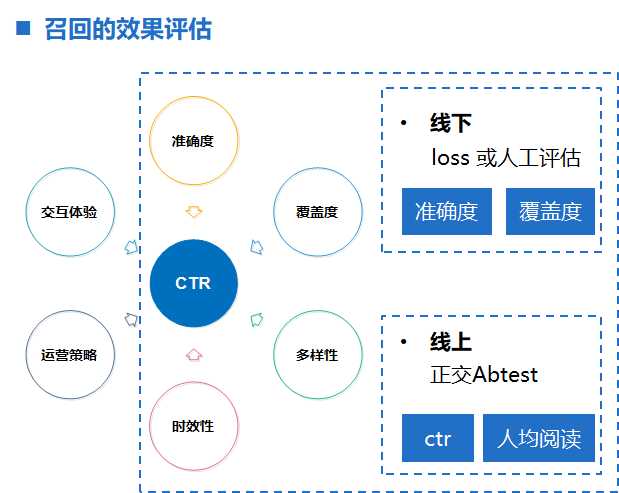
召回算法的衡量虽然有一些通用的衡量指标,比如准确度,覆盖度 F1等,但是在实际应用中,一般会和自己的应用场景和业务指标挂钩,
通过一些更贴合实际的指标去衡量:
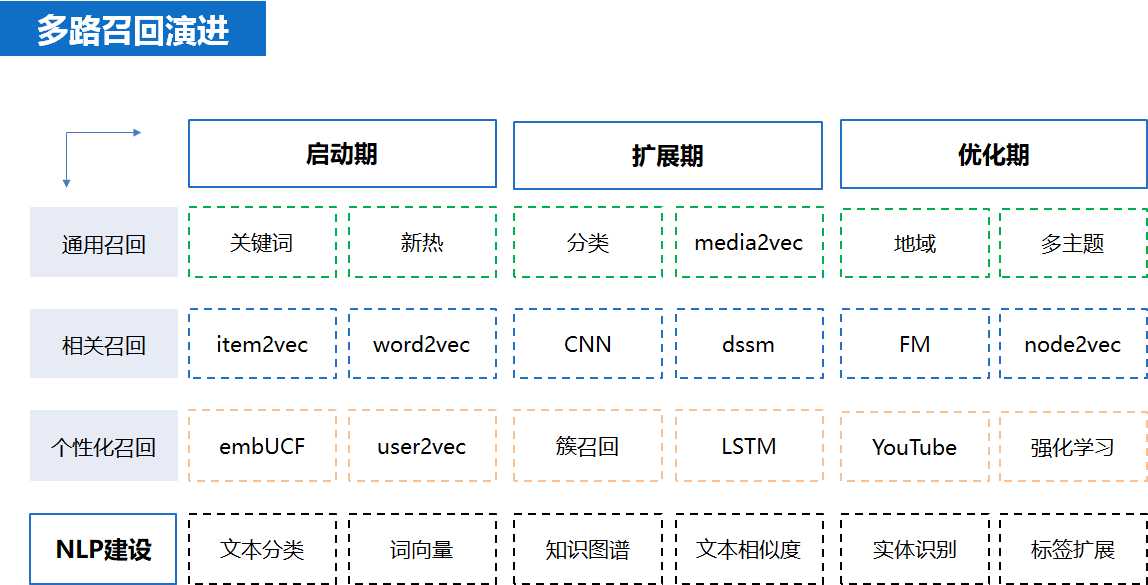
由于是新闻推荐,而且是从零到一实现整个推荐系统,因此我们的推荐和NLP 一开始就密切的联系在了一起,
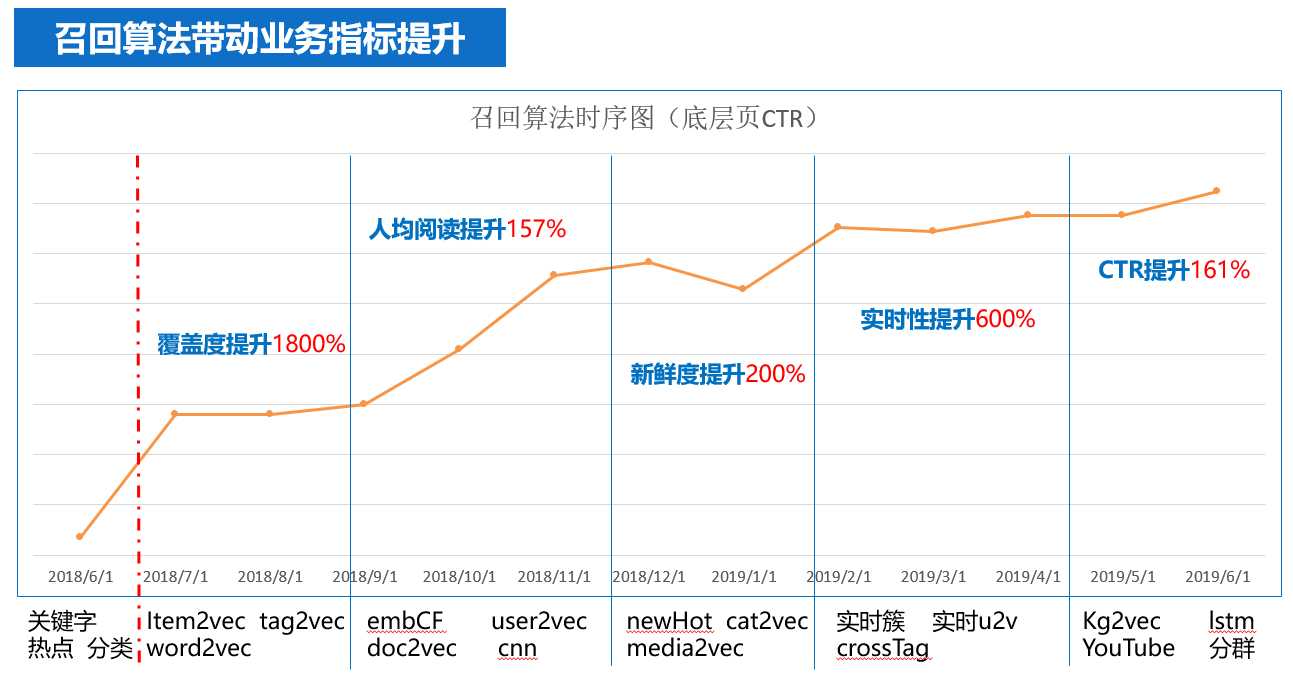
并且一直伴随着我们的持续优化过程。从开始到现在,按照时间顺序,依次实现了如下算法:
一路有效的召回算法从想法的产生,到最后上线并起作用大致要历经一下各态
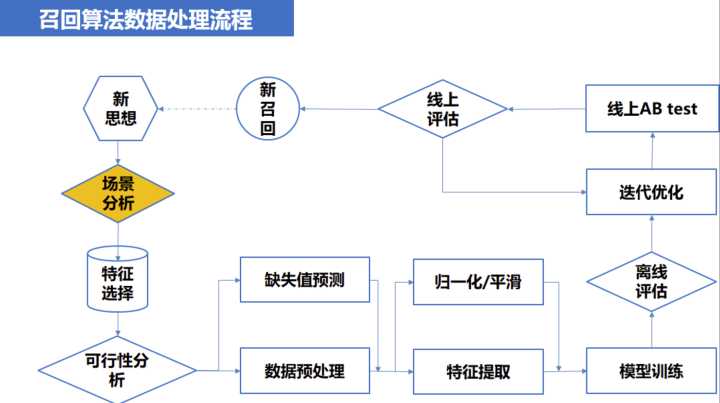
大致一个月一路召回模型 :
由于我们是图文类型的新闻推荐,NLP和召回算法相伴而生,在做召回的过程中也完成了一些基本的NLP基础建设,具体如下:


原文:https://www.cnblogs.com/Allen-rg/p/13819922.html