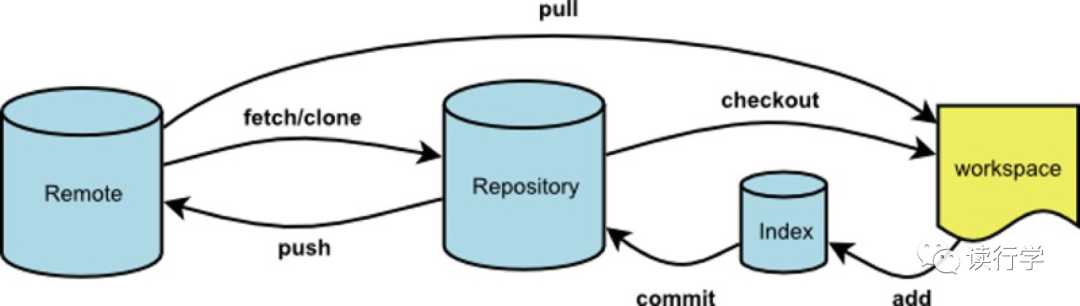
关于版本控制,其实我们应该都比较熟悉,甚至经常用到,比如我们写一个文档的过程中,经常会另存为一个独立文件作为备份,来管理我们在写文档的过程中产生的不同版本,这就是版本管理,只是这是用人工的方式来做版本控制。当不同版本的数量庞大的时候,人工进行版本管理就比较容易出差错了,这时就出现了用软件系统作为工具来进行版本控制,这就是版本控制系统。
版本控制的策略比较常见的有两种:一种是独立文件或说整体备份的方式,比如使用另存为将整个项目或者整个文档整体备份一个版本;另一种就是补丁包的方式,比如使用 diff 命令将当前版本与上一个版本对比得出两者之间的差异从而形成一个补丁包,这样上一个版本加上这个补丁包就是当前版本。显然前者会产生大量重复数据,消耗比较多的存储资源,但是每一个版本都是独立且完整的;后者几乎没有重复数据,存储效率更高,但是每一个版本的补丁包无法独立使用,因为它们都需要递归地依赖上一个版本才能合并出一个完整的版本。
版本控制系统大致分为两大类,一类是中心版本控制系统,比如 Concurrent Versions System(简称 CVS)和 Subversion(简称 SVN);另一类就是分布式版本控制系统,比如我们即将重点介绍的 Git,是目前世界上最先进的分布式版本控制系统(没有之一)。
通过git clone命令,将版本库克隆到本地完成本地版本库的初始化。git clone命令的用法如下:
git clone https://github.com/Qhxxx/git-test
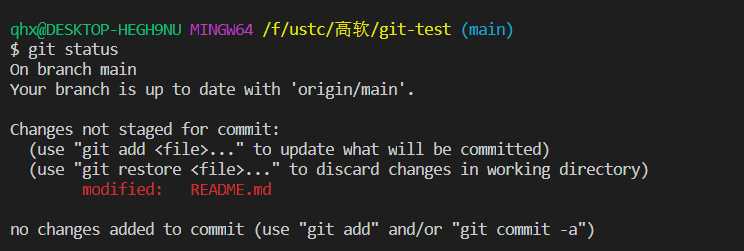
通过git status查看当前工作区(workspace)的状态。
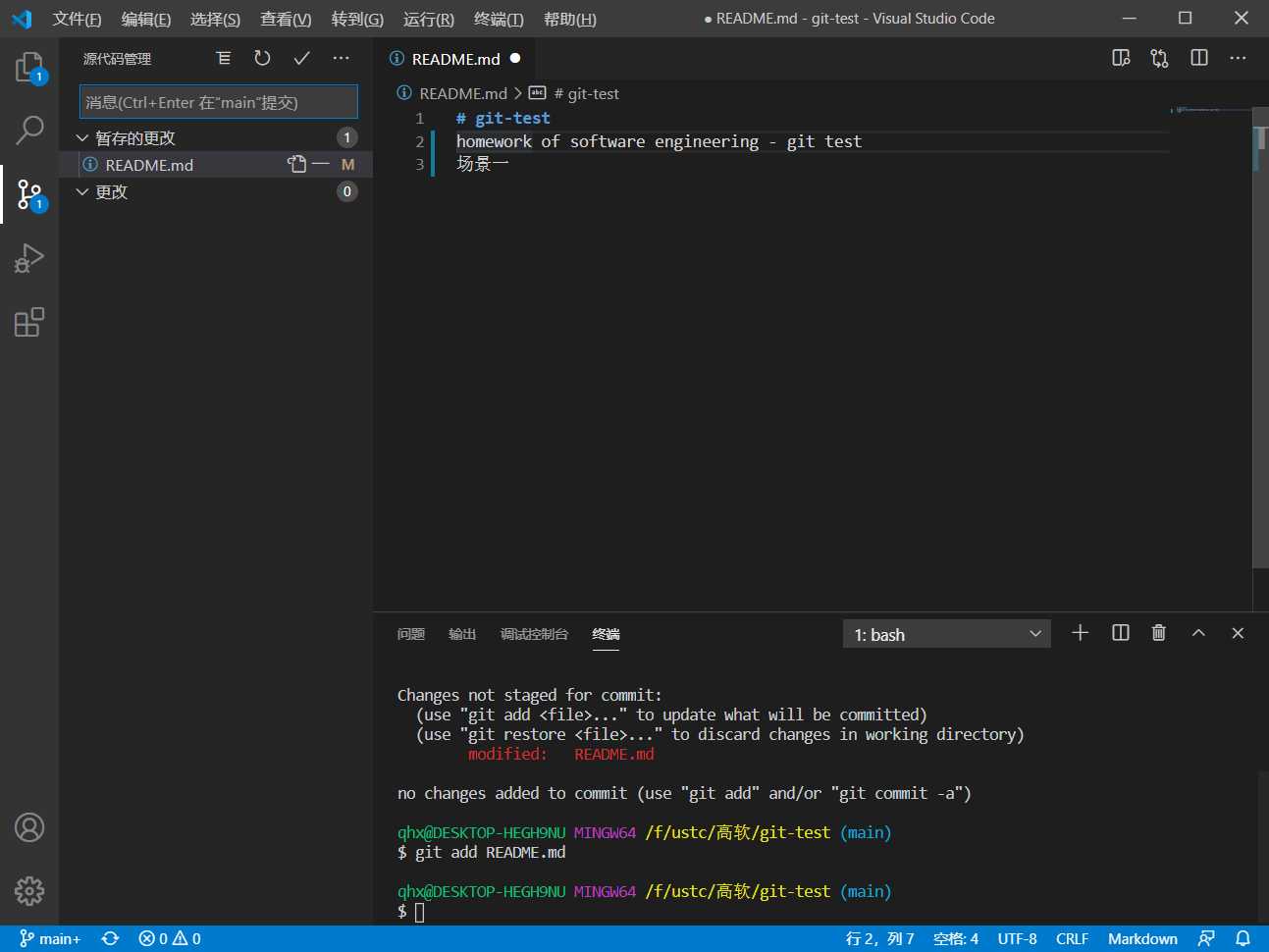
通过git add命令把文件添加到暂存区(Index)
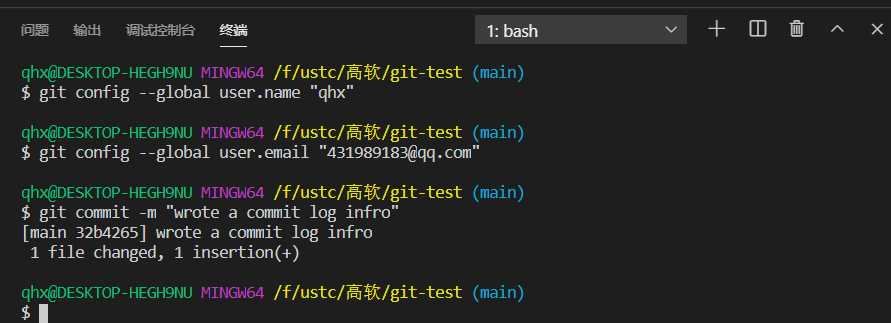
通过git commit -m "wrote a commit log infro”把暂存区里的文件提交到仓库,这里需要填写用户名和邮箱作为一个标识。
通过git log命令查看当前HEAD之前的提交记录,便于回到过去
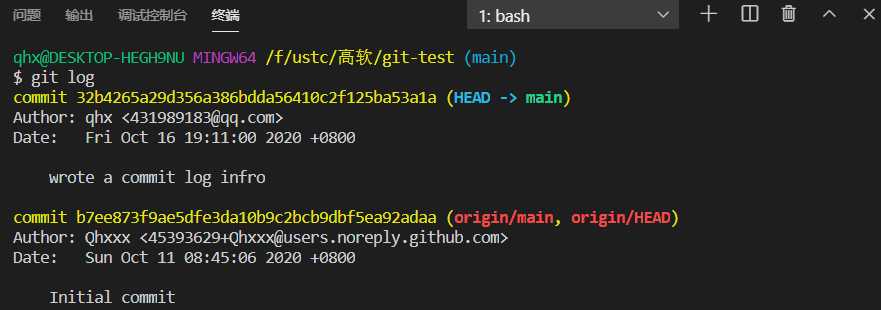
通过git reset --hard HEAD^^/HEAD~100/commit-id/commit-id的头几个字符进行回退
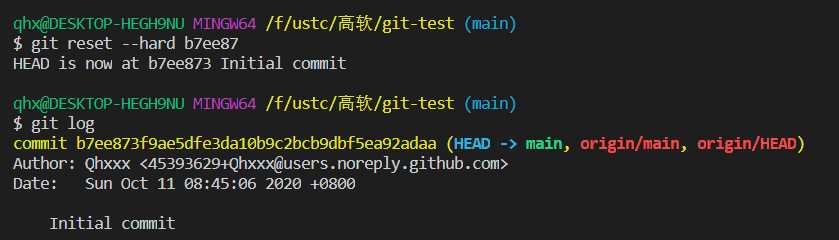
通过git reflog 可以查看当前HEAD之后的提交记录,便于回到未来。
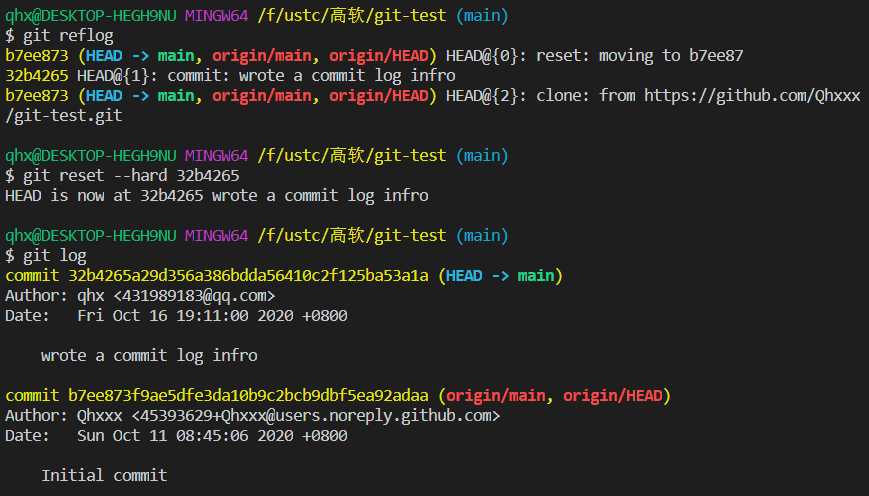
通过从github clone一个项目到本地仓库进行管理已在场景一中执行。
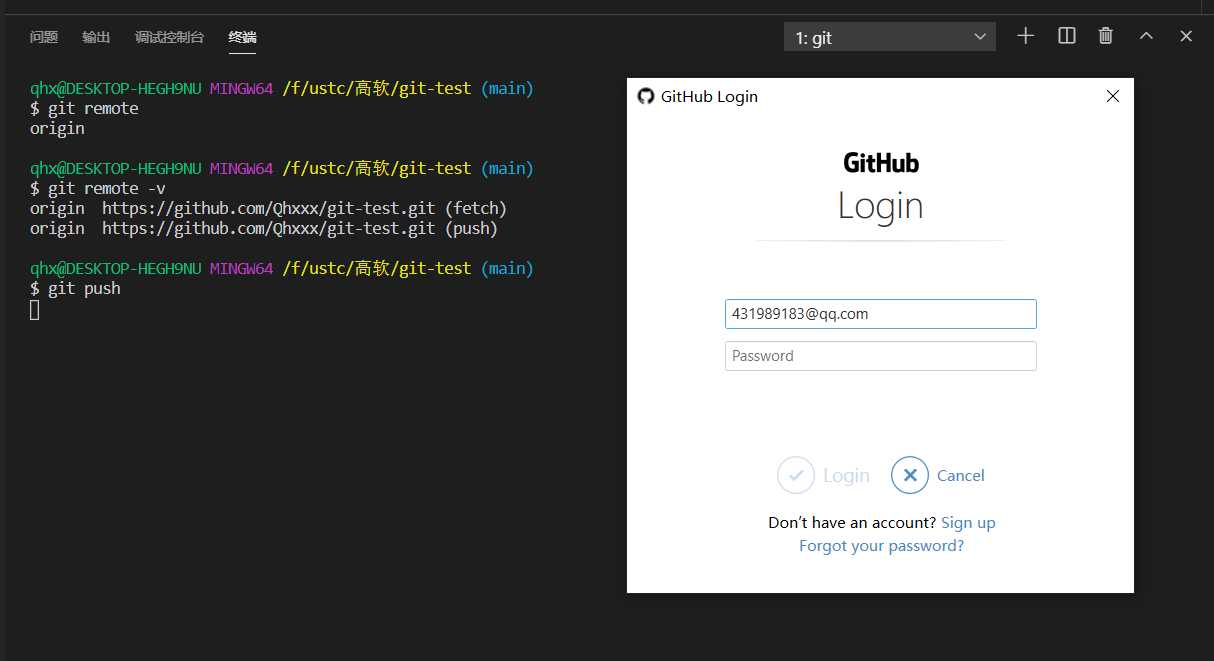
通过git remote -v查看远程程序存储库信息。
进行push操作,需要登陆GitHub,成功push。
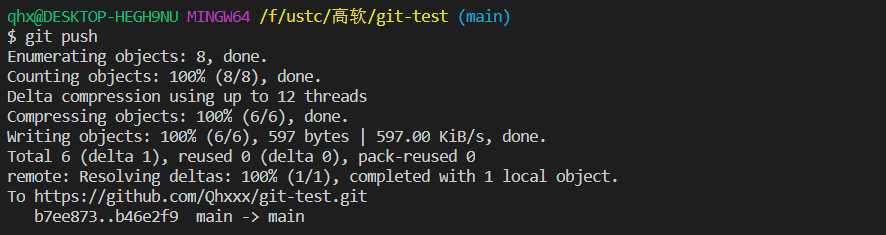
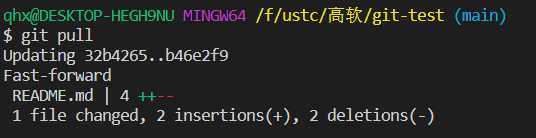
pull操作。
为自己的工作创建一个分支git checkout -b mybranch。

使用git branch 查看分支。

保留mybranch分支合并分支需要关闭“快进式合并”,先切换回main分支,将远程origin/main同步最新到本地存储库,再合并mybranch到master分支,推送到远程origin/main之后即完成了一项开发工作。此处原理可以参考本文开头孟宁老师的文章。
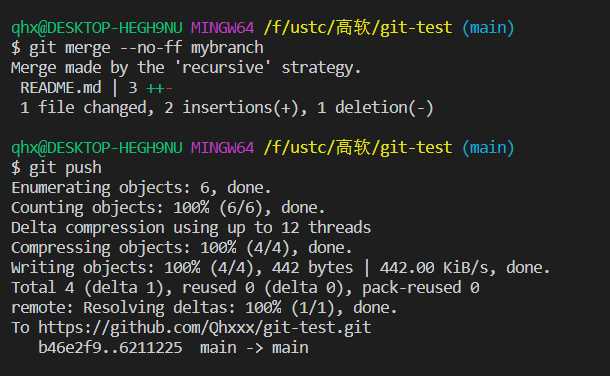
为了让 log 记录将来更容易回顾参考,用 git rebase 重新整理一下提交记录。
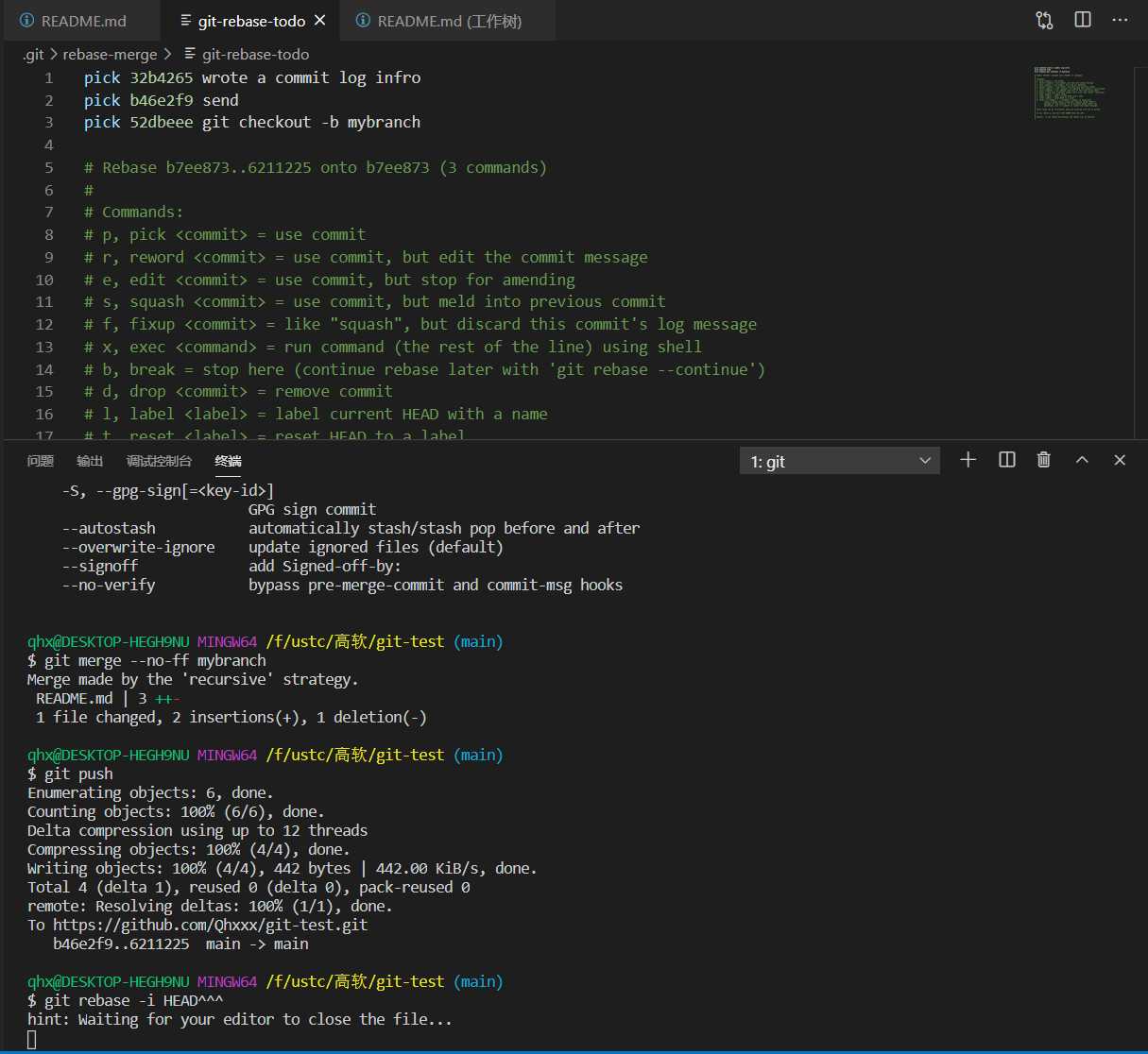
删除pick b46e2f9 send,并处理冲突。
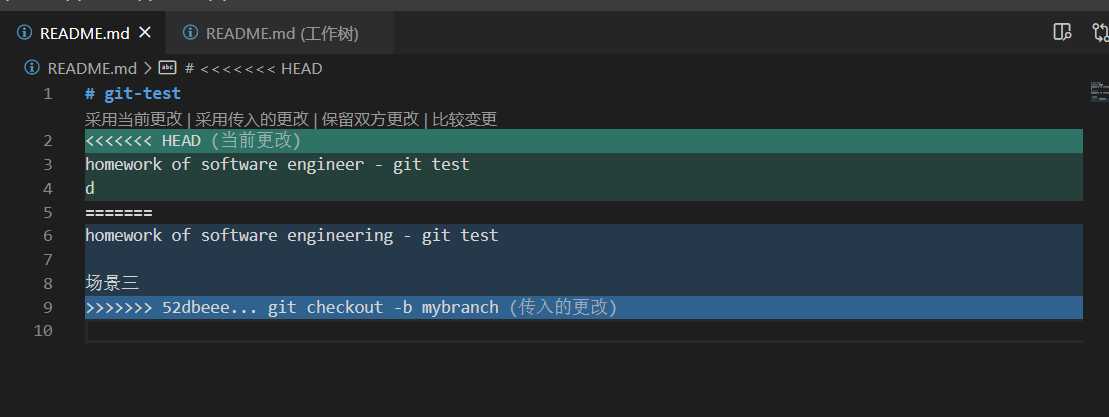
解决冲突后需要将修改后的文件存入暂存区(git add),最后执行如下命令完成git rebase,可以看到两个commit已经被删除。
最后,和场景三的第4步一样,先切换回master分支,将远程origin/main同步最新到本地存储库,再合并mybranch到master分支,推送到远程origin/main之后即完成了一项开发工作。
前面我们讨论的场景三和场景四都是在紧密合作的开发团队中使用的,这样的开发团队具有良好的信任关系,具有共同遵守的、规范的项目开发流程。但是开源社区开发活动往往是松散的团队,团队成员的技术水平或开发流程往往参差不齐、千差万别。这时如果采用场景三和场景四中推荐的参考工作流程,项目仓库的网络图就会一团糟。
为了解决开源社区松散团队的协作问题,Github提供了Fork+ Pull request的协作开发工作流程。
当你想更正别人仓库里的Bug或者向别人仓库里贡献代码时,要走Fork+ Pull request的协作开发工作流程:
至此,场景一到场景四的实战演练,由浅入深,让我对VS Code中使用git版本控制有了一定的了解与掌握。深深的感觉到版本控制能给项目开发带来许多便捷,也希望能在以后的使用过程中进行更深入的学习。
原文:https://www.cnblogs.com/ustcqhx/p/13829449.html