摘自百度
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。Entropy = 系统的凌乱程度,使用算法ID3, C4.5和C5.0生成树算法使用熵。这一度量是基于信息学理论中熵的概念。
决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。
分类树(决策树)是一种十分常用的分类方法。他是一种监督学习,所谓监督学习就是给定一堆样本,每个样本都有一组属性和一个类别,这些类别是事先确定的,那么通过学习得到一个分类器,这个分类器能够对新出现的对象给出正确的分类。这样的机器学习就被称之为监督学习。
案例:
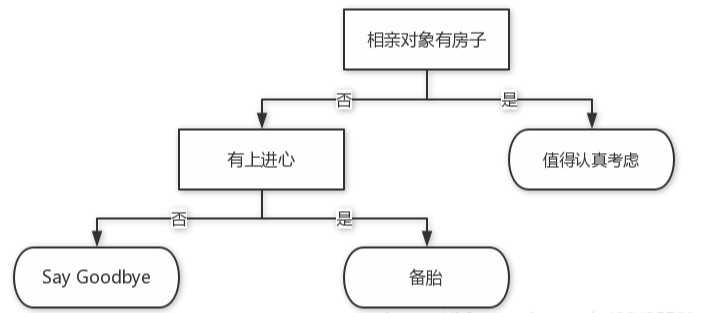
这是一个假想的相亲系统,首先检测对方是否有房。如果有房,则进一步考虑。
如果没有房,则观察相亲对象是否有上进心,
如果没有,Say goodbye,此时可以说,‘你很好,但我们不合适。’
如果有,则把这个相亲对象列入候选名单,或者说是备胎组
不过这只是理想的,生活中会更复杂,考虑因素也是五花八门。脾气好吗?会做饭吗?会做家务吗?家里几个孩子?父母是干什么的????
那么这里可以用决策树进行预测,大致分为以下几个步骤:
四个特征(内部结点):age(年龄)、prescript(症状)、astigmatic(是否散光)、tearRate(眼泪数量)
三个类别(叶结点):硬材质(hard)、软材质(soft)、 不适合佩戴隐形眼镜(no lenses)
from sklearn.preprocessing import LabelEncoder # 用于序列化
from sklearn.tree import DecisionTreeClassifier # 导入决策树分类器
from sklearn.model_selection import cross_val_score # 导入计算交叉检验值的函数cross_val_score
# 创建一颗基于基尼系数的决策树(国际上通用的、用以衡量一个国家或地区居民收入差距的常用指标)
# 国际惯例把0.2以下视为收入绝对平均,0.2-0.3视为收入比较平均;
#0.3-0.4视为收入相对合理;0.4-0.5视为收入差距较大,
#当基尼系数达到0.5以上时,则表示收入悬殊。
clf = DecisionTreeClassifier(criterion="gini", max_features=None)
#criterion: 用于选择属性的准则,可以传入“gini"代表基尼系数,或者“entropy代表信息增益
#max features:表示在决策树结点进行分裂时,从多少个特征中选择最优特征。可以设定固定数目、百分比或其他标准。
#它的默认值是使用所有特征个数,这里取的所有。
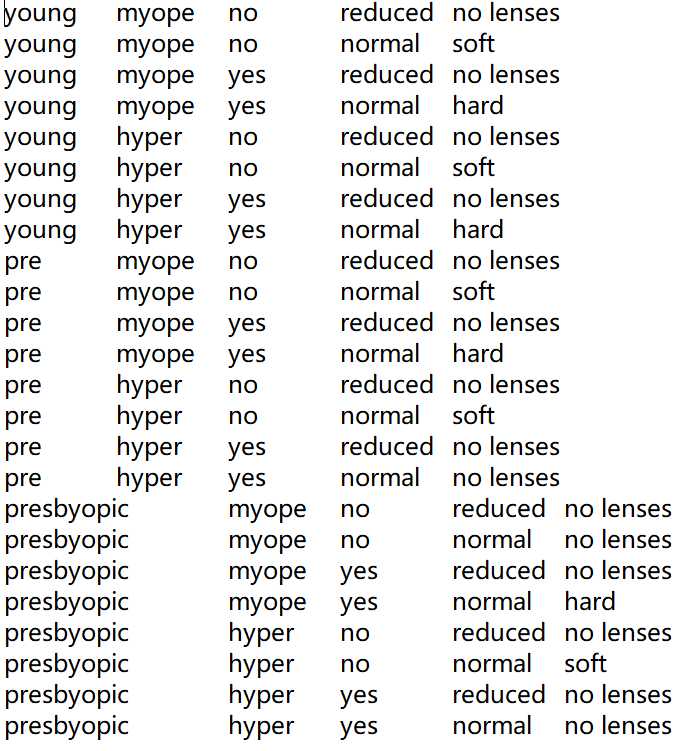
蓝奏云:lenses.txt
fr = open(‘lenses.txt‘, ‘r‘)
lenses = [inst.strip().split(‘\t‘) for inst in fr.readlines()] # 去掉空格,提取每组数据的类别,保存在列表里
lensesLabels = [‘age‘, ‘prescript‘, ‘astigmatic‘, ‘tearRate‘] # 特征标签
lenses_target = [row[-1] for row in lenses] # 目标标签
lenses_list = [] # 保存lenses数据的临时列表
lenses_dict = {} # 保存lenses数据的字典,用于生成pandas
for each_label in lensesLabels:
# 提取信息,生成字典
for each in lenses:
lenses_list.append(each[lensesLabels.index(each_label)])
lenses_dict[each_label] = lenses_list
lenses_list = []
lenses_data = pd.DataFrame(lenses_dict) # 生成pandas.DataFrame
lenses_data = pd.DataFrame(lenses_dict) # 生成pandas.DataFrame
le = LabelEncoder() # 创建LabelEncoder()对象,用于序列化
for col in lenses_data.columns:
# 为每一列序列化
lenses_data[col] = le.fit_transform(lenses_data[col])
lenses_target = le.fit_transform(lenses_target) # 将标签序列化
age astigmatic prescript tearRate
2 0 1 1
2 0 1 0
2 1 1 1
2 1 1 0
2 0 0 1
score = cross_val_score(clf, lenses_data, lenses_target, cv = 10) # 使用10折交叉验证
clf.fit(lenses_data, lenses_target) # fit()训练模型
# 待预测的测试集
test = [
[1, 1, 1, 0],
[2, 0, 1, 0],
[0, 1, 0, 1]]
pre_test_tree = clf.predict(test) # 决策树,函数预测
print(‘运用 决策树 预测分类结果:‘,pre_test_tree)


from sklearn.datasets import load_iris #导入鸢尾花训练集
from sklearn.tree import DecisionTreeClassifier #导入决策树分类器
from sklearn.model_selection import cross_val_score #导入计算交叉检验值的函数cross_val_score
#创建一颗基于基尼系数的决策树
clf = DecisionTreeClassifier()
#将鸢尾花数据赋值给变量iris
iris = load_iris()
ris.data鸢尾花数据做为特征
iris.target鸢尾花分类标签做为目标结果
设定cv为10,使用10折交叉验证,得到最终的交叉验证得分
data = iris.data #鸢尾花数据作为特征,
target = iris.target #鸢尾花数据作为目标结果[0,1,2],
cv = 10 #使用10折交叉验证
score = cross_val_score(clf, data, target, cv = 10)
fit() 函数训练模型,并使用predict() 函数预测
clf.fit(data, target) #fit()训练模型
test = [[5.1, 3.5, 1.4, 0.2],
[4., 2.2, 1.7, 0.4],
[5.9, 3., 5.1, 1.8]]
pre_test_tree = clf.predict(test) #决策树 函数预测
运用 决策树 预测分类结果: [0 0 2]
[山鸢尾 山鸢尾 维吉尼亚鸢尾]
PPT:决策树分析
原文:https://www.cnblogs.com/ZhengBlogs/p/decision_tree.html
