知识图谱听起来很高大上,而且也应用广泛。而图数据库,你可以到网上搜搜,基本就是像 neo4j, janusgraph, HugeGraph...
如果想让做个类似的图谱的东西,你会怎么办呢?一来就上真的图谱真的好吗?也许前期就三两个关系链,也许只是业务试水,你就去搞个真的图数据库过来?是不是太浪费了。
是的,实际上前期我们最好自己实现一些简单的关系链维护即可。
那么,为了能够适应稍微的关系变化,也许我们还是需要效仿下图数据库的概念。那么,现在的第一个问题就是:如何使用文字表述一个图关系链?
图数据库三大要素: 实体, 关系, 客体 。
实际上要解决这个问题倒也不难,只要自己定一种表示方法,自己能看懂就行,不去管其他人。比如用 ‘1,2,3‘ 代表先1后2再3... 但实际上,想要表示稍微复杂点的结构,也许并不是特别容易呢。而且,如果想要考虑后续可能的切真正的图数据库,为何不参考下别人的标准呢?
比如现在通用些的,cypher, gremlin... 大家可以网上搜索下资料,参考下来,好像cypher更形象化些,尤其是各种箭头的使用比较方便。
比如要表示A与的B的关系可以是: (:A)-[:关系]->(:B)
而对于多个复杂关系,则可以用多个类似的关系关联起来就可以了。
嗯,看起来不错。表示的方式定好了,那么我们如何具体处理关系呢?
如下图所示,我们有如下关系,应该如何定义字符表达方法,以达到配置的目的?
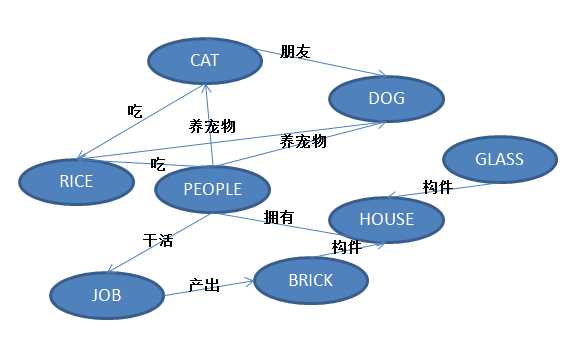
按照第1节中我们定义的规范,我们可以用如下字符串表示。
(:PEOPLE)-[:养宠物]->(:CAT)-[:吃]->(:RICE) ,(:PEOPLE)-[:吃]->(:RICE) ,(:PEOPLE)-[:养宠物]->(:DOG) ,(:PEOPLE)-[:拥有]->(:HOUSE) ,(:PEOPLE)-[:干活]->(:JOB) ,(:CAT)-[:朋友]->(:DOG) ,(:DOG)-[:吃]->(:RICE) ,(:JOB)-[:产出]->(:BRICK) ,(:HOUSE)<-[:构件]-(:BRICK) ,(:HOUSE)<-[:构件]-(:GLASS)
应该说还是比较直观的,基本上我们只要按照图所示的关系,描述出出入边和关系就可以了。而且还有相应的cypher官方规范支持,也不用写文档,大家就可以很方便的接受了。
如上,我们已经用字符串表示出了关系了。但单是字符串,是并不能被应用理解的。我们需要解析为具体的数据结构,然后才可以根据关系推导出具体的血缘依赖。这是本文的重点。
实际也不复杂,我们仅仅使用到了cypher中非常少的几个元素表示法,所以也仅需解析出该几个字符,然后在内存中构建出相应的关系即可。
具体代码实现如下:
所谓框架就是整体流程管控代码,它会让你明白整个系统是如何work的。
import com.my.mvc.app.common.helper.graph.GraphNodeEntityTree; import com.my.mvc.app.common.helper.graph.NodeDiscoveryDirection; import com.my.mvc.app.common.helper.graph.VertexEdgeSchemaDescriptor; import com.my.mvc.app.common.helper.graph.VertexOrEdgeType; import com.my.mvc.app.common.util.CommonUtil; import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; /** * 功能描述: 简单图语法解析器(类 cypher 语法) * * 请参考网上 cypher 资料 * */ public class SimpleGraphSchemaSyntaxParser { /** * 解析配置图谱关系配置为树结构 * * @param cypherGraphSchema 类cypher语法的 关系表示语句 * @return 解析好的树结构 */ public static GraphNodeEntityTree parseGraphSchemaAsTree(String cypherGraphSchema) { List<VertexEdgeSchemaDescriptor> flatNodeList = tokenize(cypherGraphSchema); return buildGraphAstTree(flatNodeList); } /** * 构建图关系抽象语法树 * * @param flatNodeList 平展的图节点列表 * @return 构建好的实例 */ private static GraphNodeEntityTree buildGraphAstTree( List<VertexEdgeSchemaDescriptor> flatNodeList) { Map<String, GraphNodeEntityTree> uniqVertexContainer = new HashMap<>(); GraphNodeEntityTree root = new GraphNodeEntityTree(flatNodeList.get(0)); uniqVertexContainer.put(flatNodeList.get(0).getVertexLabelType(), root); GraphNodeEntityTree parent; GraphNodeEntityTree afterNode; for ( int i = 1; i < flatNodeList.size(); i++ ) { VertexEdgeSchemaDescriptor vertexOrEdge1 = flatNodeList.get(i); if(vertexOrEdge1.getNodeType() == VertexOrEdgeType.EDGE) { // 存在重复节点,需重建关系 VertexEdgeSchemaDescriptor vertexPrev = flatNodeList.get(i - 1); if(vertexPrev.getNodeType() != VertexOrEdgeType.VERTEX) { continue; } if(++i >= flatNodeList.size()) { throw new RuntimeException("缺少客体关系配置, near 边[" + vertexOrEdge1.getRawWord() + "]"); } VertexEdgeSchemaDescriptor relation = vertexOrEdge1; VertexEdgeSchemaDescriptor vertexAfter = flatNodeList.get(i); parent = uniqVertexContainer.get(vertexPrev.getVertexLabelType()); afterNode = uniqVertexContainer.get(vertexAfter.getVertexLabelType()); if(parent == null) { parent = root; uniqVertexContainer.putIfAbsent(vertexAfter.getVertexLabelType(), parent); } if(afterNode == null) { afterNode = new GraphNodeEntityTree(vertexAfter); uniqVertexContainer.put(vertexAfter.getVertexLabelType(), afterNode); } if(relation.getDirection() == NodeDiscoveryDirection.OUT) { parent.addOutVertex(afterNode, relation); } else { parent.addInVertex(afterNode, relation); } } } root.setUniqVertexTypes(uniqVertexContainer); return root; } /** * 拆分图关系schema为 可理解的边和点 * * @param cypherGraphSchema 建关系语句,如 (:BASE_LABEL)-[:被组合引用]->(:COMPOSE_LABEL) * @return 拆解后的token列表 */ private static List<VertexEdgeSchemaDescriptor> tokenize(String cypherGraphSchema) { String[] relationArr = cypherGraphSchema.split(","); List<VertexEdgeSchemaDescriptor> flatNodeList = new ArrayList<>(); for (String relation1 : relationArr) { char[] src = relation1.trim().toCharArray(); for (int i = 0; i < src.length; i++) { char ch = src[i]; // 顶点 if(ch == ‘(‘) { StringBuilder specNameBuilder = new StringBuilder(); while (i + 1 < src.length) { char nextCh = src[i + 1]; if(nextCh == ‘:‘) { String vertexLabel = CommonUtil.readSplitWord( src, i, ‘:‘, ‘)‘, false); flatNodeList.add(VertexEdgeSchemaDescriptor.newVertex( specNameBuilder.toString() + ":" + vertexLabel, vertexLabel)); i += vertexLabel.length() + 2; break; } specNameBuilder.append(nextCh); ++i; } continue; } // 边关系, (:SRC)-[:RELATION]->(:DST) if(ch == ‘-‘ && i + 1 < src.length && src[i + 1] == ‘[‘) { ++i; StringBuilder specNameBuilder = new StringBuilder(); while (i + 1 < src.length) { char nextCh = src[i + 1]; if(nextCh == ‘:‘) { String edgeLabel = CommonUtil.readSplitWord( src, i, ‘:‘, ‘]‘, false); int nextVertexStart = i + edgeLabel.length() + 2; if(nextVertexStart + 2 >= src.length) { throw new RuntimeException("血缘图谱配置错误: 缺少客体" + ", near ‘" + new String(src, nextVertexStart, src.length - nextVertexStart)); } if(src[++nextVertexStart] != ‘-‘ || src[++nextVertexStart] != ‘>‘) { throw new RuntimeException("血缘图谱配置错误: 主体后面需紧跟关系 ->" + ", near ‘" + new String(src, nextVertexStart, src.length - nextVertexStart)); } flatNodeList.add(VertexEdgeSchemaDescriptor.newEdge( specNameBuilder.toString() + ":" + edgeLabel, edgeLabel, NodeDiscoveryDirection.OUT)); i = nextVertexStart; break; } specNameBuilder.append(nextCh); ++i; } continue; } // 边关系, (:SRC)<-[:RELATION]-(:DST) if(ch == ‘<‘) { if(i + 2 > src.length) { throw new RuntimeException("血缘配置错误: 长度不匹配, near ‘" + new String(src, i, src.length - i)); } if(src[++i] != ‘-‘ || src[++i] != ‘[‘) { throw new RuntimeException("血缘配置错误: 边关系配置错误, near ‘" + new String(src, i, src.length - i)); } StringBuilder specNameBuilder = new StringBuilder(); while (i + 1 < src.length) { char nextCh = src[i + 1]; if(nextCh == ‘:‘) { String edgeLabel = CommonUtil.readSplitWord( src, i, ‘:‘, ‘]‘, false); int nextVertexStart = i + edgeLabel.length() + 2; if(nextVertexStart + 2 >= src.length) { throw new RuntimeException("血缘图谱配置错误: 缺少客体" + ", near ‘" + new String(src, nextVertexStart, src.length - nextVertexStart)); } if(src[++nextVertexStart] != ‘-‘ || src[nextVertexStart + 1] != ‘(‘) { throw new RuntimeException("血缘图谱配置错误: 主体后面需紧跟关系 -> " + ", near ‘" + new String(src, nextVertexStart, src.length - nextVertexStart)); } flatNodeList.add(VertexEdgeSchemaDescriptor.newEdge( specNameBuilder.toString() + ":" + edgeLabel, edgeLabel, NodeDiscoveryDirection.IN)); i = nextVertexStart; break; } specNameBuilder.append(nextCh); ++i; } } } } return flatNodeList; } }
怎么样,不复杂吧。就是两个步骤:1. 解析每个单个元素信息; 2. 根据单元素信息,构建出上下级关系;
使用 IN 代表入方向关系,用 OUT 代表出方向关系,每两个顶点之间都有一条边相连。大体就是这样了。但是明显,还有许多细节需要我们去考虑,比如边关系放在哪里?如何添加相关节点?这些东西是需要特定的数据结构支持的。看我细细道来:
所谓单节点,即是站在任意关系点上来看整体图的结构,如果整个图是连通的,那么理论上,通过这个节点所以探索到任意其他节点。所以,其实它非常重要。
package com.my.mvc.app.common.helper.graph; import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; /** * 功能描述: 简单图结构树描述类 * */ public class GraphNodeEntityTree { /** * 当前顶点描述 */ private VertexEdgeSchemaDescriptor vertex; /** * 关系边容器 */ private Map<NodeDiscoveryDirection, List<RelationWithVertexDescriptor>> relations = new HashMap<>(); /** * 入射方向节点 */ private List<GraphNodeEntityTree> in = new ArrayList<>(); /** * 出射方向节点 */ private List<GraphNodeEntityTree> out = new ArrayList<>(); /** * 所有顶点实例容器 */ private Map<String, GraphNodeEntityTree> uniqVertexTypes; public GraphNodeEntityTree(VertexEdgeSchemaDescriptor vertex) { this.vertex = vertex; uniqVertexTypes = new HashMap<>(); } public void setUniqVertexTypes(Map<String, GraphNodeEntityTree> uniqVertexTypes) { this.uniqVertexTypes = uniqVertexTypes; } public void addRelation(VertexEdgeSchemaDescriptor srcEntity, VertexEdgeSchemaDescriptor relation, VertexEdgeSchemaDescriptor dstEntity) { List<RelationWithVertexDescriptor> list = relations.computeIfAbsent( relation.getDirection(), k -> new ArrayList<>()); list.add(new RelationWithVertexDescriptor(srcEntity, relation, dstEntity)); } public GraphNodeEntityTree addInVertex(GraphNodeEntityTree embeddedEntity, VertexEdgeSchemaDescriptor relation) { embeddedEntity.addOutVertexInner(this, relation.reverseDirection()); addInVertexInner(embeddedEntity, relation); return embeddedEntity; } private GraphNodeEntityTree addInVertexInner(GraphNodeEntityTree embeddedEntity, VertexEdgeSchemaDescriptor relation) { in.add(embeddedEntity); addRelation(vertex, relation, embeddedEntity.getVertex()); return embeddedEntity; } public GraphNodeEntityTree addOutVertex(GraphNodeEntityTree embeddedEntity, VertexEdgeSchemaDescriptor relation) { embeddedEntity.addInVertexInner(this, relation.reverseDirection()); addOutVertexInner(embeddedEntity, relation); return embeddedEntity; } private GraphNodeEntityTree addOutVertexInner(GraphNodeEntityTree embeddedEntity, VertexEdgeSchemaDescriptor relation) { out.add(embeddedEntity); addRelation(this.getVertex(), relation, embeddedEntity.getVertex()); return embeddedEntity; } public VertexEdgeSchemaDescriptor getVertex() { return vertex; } /** * 获取关系名称 * * @param nodeIndex 节点序号 * @param direction 方向 * @return 关系名称描述 */ public String getRelationName(int nodeIndex, NodeDiscoveryDirection direction) { List<RelationWithVertexDescriptor> list = relations.get(direction); if(list == null || list.isEmpty()) { return null; } return list.get(nodeIndex).getRelationName(); } public List<GraphNodeEntityTree> getIn() { return in; } public List<GraphNodeEntityTree> getOut() { return out; } /** * 快速获取图节点根(根据顶点label) * * @param vertexLabel 顶点标识 * @return 节点所在实例, 找不到对应节点则返回 null */ public GraphNodeEntityTree getNodeEntityTreeByVertexLabel( String vertexLabel) { return uniqVertexTypes.get(vertexLabel); } }
可以说后续的操作入口都是在这里的,所以重点关注。
最开始有一个token化的过程,那么token化之后,如何定义也比较重要,我们统一使用一个描述类来定义:
package com.my.mvc.app.common.helper.graph; /** * 功能描述: 图顶点和边描述类 * */ public class VertexEdgeSchemaDescriptor { private String rawWord; private VertexOrEdgeType nodeType; private String vertexLabelType; private String relationName; private NodeDiscoveryDirection direction; private VertexEdgeSchemaDescriptor(String rawWord, VertexOrEdgeType nodeType, String vertexLabelType, String relationName, NodeDiscoveryDirection direction) { this.rawWord = rawWord; this.nodeType = nodeType; this.vertexLabelType = vertexLabelType; this.relationName = relationName; this.direction = direction; } /** * 新建顶点实例 * * @param rawWord 原始字符描述 * @param vertexLabelType 解析后的顶点类型(枚举完成所有点类型) * @return 顶点实例 */ public static VertexEdgeSchemaDescriptor newVertex(String rawWord, String vertexLabelType) { return new VertexEdgeSchemaDescriptor(rawWord, VertexOrEdgeType.VERTEX, vertexLabelType, null, null); } /** * 新建边实例 * * @param rawWord 原始字符描述 * @param relationName 关系名称(当id使用) * @param direction 关系方向( -> 出方向OUT, <- 入方向IN ) * @return 边实例 */ public static VertexEdgeSchemaDescriptor newEdge(String rawWord, String relationName, NodeDiscoveryDirection direction) { return new VertexEdgeSchemaDescriptor(rawWord, VertexOrEdgeType.EDGE, null, relationName, direction); } public String getRawWord() { return rawWord; } public VertexOrEdgeType getNodeType() { return nodeType; } public String getVertexLabelType() { return vertexLabelType; } public String getRelationName() { return relationName; } public NodeDiscoveryDirection getDirection() { return direction; } public VertexEdgeSchemaDescriptor reverseDirection() { return new VertexEdgeSchemaDescriptor(rawWord, nodeType, vertexLabelType, "-" + relationName, direction.reverse()); } @Override public String toString() { // 点描述 if(nodeType == VertexOrEdgeType.VERTEX) { return nodeType + "{" + "rawWord=‘" + rawWord + ‘\‘‘ + ", vertexLabelType=" + vertexLabelType + ‘}‘; } // 边描述 return nodeType + "{" + "rawWord=‘" + rawWord + ‘\‘‘ + ", relationName=‘" + relationName + ‘\‘‘ + ", direction=" + direction + ‘}‘; } }
主要就是原始字符串,定义边、定义点。类似与单词的聚合吧。
我们需要清楚地知道各个点与各个点间的关系,所以需要一个关系描述类,来展示这东西。(实际上核心并未使用该关系)
package com.my.mvc.app.common.helper.graph; /** * 功能描述: 关系实例, 实体 -> 关系 -> 客体 * */ public class RelationWithVertexDescriptor { /** * 源点、起点 */ private final VertexEdgeSchemaDescriptor srcVertex; /** * 目标点 */ private final VertexEdgeSchemaDescriptor dstVertex; /** * 关系(名称) */ private final VertexEdgeSchemaDescriptor relation; public RelationWithVertexDescriptor(VertexEdgeSchemaDescriptor srcVertex, VertexEdgeSchemaDescriptor relation, VertexEdgeSchemaDescriptor dstVertex) { this.srcVertex = srcVertex; this.dstVertex = dstVertex; this.relation = relation; } public VertexEdgeSchemaDescriptor getSrcVertex() { return srcVertex; } public VertexEdgeSchemaDescriptor getDstVertex() { return dstVertex; } /** * 获取当前关系名称 */ public String getRelationName() { return relation.getRelationName(); } @Override public String toString() { if(relation.getDirection() == NodeDiscoveryDirection.OUT) { return srcVertex.getRawWord() + "(" + srcVertex.getVertexLabelType() + ")" + " -> " + relation.getRelationName() + " -> " + dstVertex.getRawWord() + "(" + dstVertex.getVertexLabelType() + ")" ; } return srcVertex.getRawWord() + "(" + srcVertex.getVertexLabelType() + ")" + " <- " + relation.getRelationName() + " <- " + dstVertex.getRawWord() + "(" + dstVertex.getVertexLabelType() + ")" ; } }
虽实际用处不大,但是当你在debug的时候,这个描述类可以很方便地让你观察到解析是否正确。
1. 方向定义
package com.my.mvc.app.common.helper.graph; /** * 功能描述: 探索方向定义 * * @since 2020/10/12 */ public enum NodeDiscoveryDirection { /** * 入方向, 上游 */ IN, /** * 出方向, 下游 */ OUT, ; public NodeDiscoveryDirection reverse() { if(this == OUT) { return IN; } return OUT; } }
2. 边或点类型定义
package com.my.mvc.app.common.helper.graph; /** * 功能描述: 边或点类型定义 * */ public enum VertexOrEdgeType { VERTEX, EDGE, ; }
如此,整个解析模块就完成了。你可以完整的将如上字符解析为实体关系了。
经过测试才算真正可用。
package com.my.test.common.parser; import com.my.mvc.app.common.helper.SimpleGraphSchemaSyntaxParser; import com.my.mvc.app.common.helper.graph.GraphNodeEntityTree; import com.my.mvc.app.common.helper.graph.NodeDiscoveryDirection; import org.junit.Test; import java.util.List; public class SimpleGraphSchemaSyntaxParserTest { // 测试脚本 @Test public void testParseGraphSchema() throws InterruptedException { String graphSchema = "(:PEOPLE)-[:养宠物]->(:CAT)-[:吃]->(:RICE)\n" + ",(:PEOPLE)-[:吃]->(:RICE)\n" + ",(:PEOPLE)-[:养宠物]->(:DOG)\n" + ",(:PEOPLE)-[:拥有]->(:HOUSE)" + ",(:PEOPLE)-[:干活]->(:JOB)" + ",(:CAT)-[:朋友]->(:DOG)" + ",(:DOG)-[:吃]->(:RICE)" + ",(:JOB)-[:产出]->(:BRICK)" + ",(:HOUSE)<-[:构件]-(:BRICK)" + ",(:HOUSE)<-[:构件]-(:GLASS)" ; GraphNodeEntityTree tree = SimpleGraphSchemaSyntaxParser .parseGraphSchemaAsTree(graphSchema); String searchFromLabel = "PEOPLE"; NodeDiscoveryDirection direction = NodeDiscoveryDirection.OUT; int maxDepth = 10; System.out.println("->" + searchFromLabel + ", direction:" + direction + ", depth:" + maxDepth); GraphNodeEntityTree searchRootFrom = tree.getNodeEntityTreeByVertexLabel(searchFromLabel); int allNodes = traversalNodesWithDirection(searchRootFrom, direction, maxDepth, maxDepth); System.out.println("allNodes: " + allNodes); Thread.sleep(5); } /** * 按某方向遍历所有节点 * * @param root 搜索起点 * @param direction 方向, IN, OUT * @param maxDepth 搜索最大深度 * @param remainSearchDepth 剩余搜索深度 * @return 所有节点数 */ private static int traversalNodesWithDirection(GraphNodeEntityTree root, NodeDiscoveryDirection direction, int maxDepth, int remainSearchDepth) { if(remainSearchDepth <= 0) { return 0; } List<GraphNodeEntityTree> subBranches; if(direction == NodeDiscoveryDirection.OUT) { subBranches = root.getOut(); } else { subBranches = root.getIn(); } if(subBranches == null || subBranches.isEmpty()) { return 0; } String whitespaceUnit = " "; StringBuilder preWhitespaceBuilder = new StringBuilder(whitespaceUnit); for (int i = 1; i < maxDepth - remainSearchDepth + 1; i++) { preWhitespaceBuilder.append(whitespaceUnit); } int allNodes = 0; String preWhitespace = preWhitespaceBuilder.toString(); for (int i = 0; i < subBranches.size(); i++) { GraphNodeEntityTree br1 = subBranches.get(i); String relationName = root.getRelationName(i, direction); allNodes++; System.out.println(preWhitespace + "->" + relationName + "->" + br1.getVertex().getRawWord()); allNodes += traversalNodesWithDirection(br1, direction, maxDepth, remainSearchDepth - 1); } return allNodes; } }
结果样例如下:
->PEOPLE, direction:OUT, depth:10 ->养宠物->:CAT ->吃->:RICE ->朋友->:DOG ->吃->:RICE ->吃->:RICE ->养宠物->:DOG ->吃->:RICE ->拥有->:HOUSE ->干活->:JOB ->产出->:BRICK ->-构件->:HOUSE
原文:https://www.cnblogs.com/yougewe/p/13865184.html