论文题目:Detecting Oriented Text in Natural Images by Linking Segments
论文地址:https://arxiv.org/pdf/1703.06520.pdf
代码实现:https://github.com/bgshih/seglink
先来说说文本检测存在的难点:1.文本行边界框的宽高比范围太广;2.语言格式的不统一(如中文文本行没有间隔,英文文本行有间隔);3.文本行的方向任意.
针对上述存在的困难,本文提出了seglink,它是在SSD目标检测方法的基础上进行改进,其基本思想:既然一次性检测整个文本行比较困难,就先检测局部片段,然后通过规则将所有的片段进行连接,得到最终的文本行,这样做的好处是可以检测任意长度的文本行
整个实现过程包括两部分:首先检测segments,links,然后使用融合算法得到最终文本行.具体步骤如下:
具体的网络结构如下图:
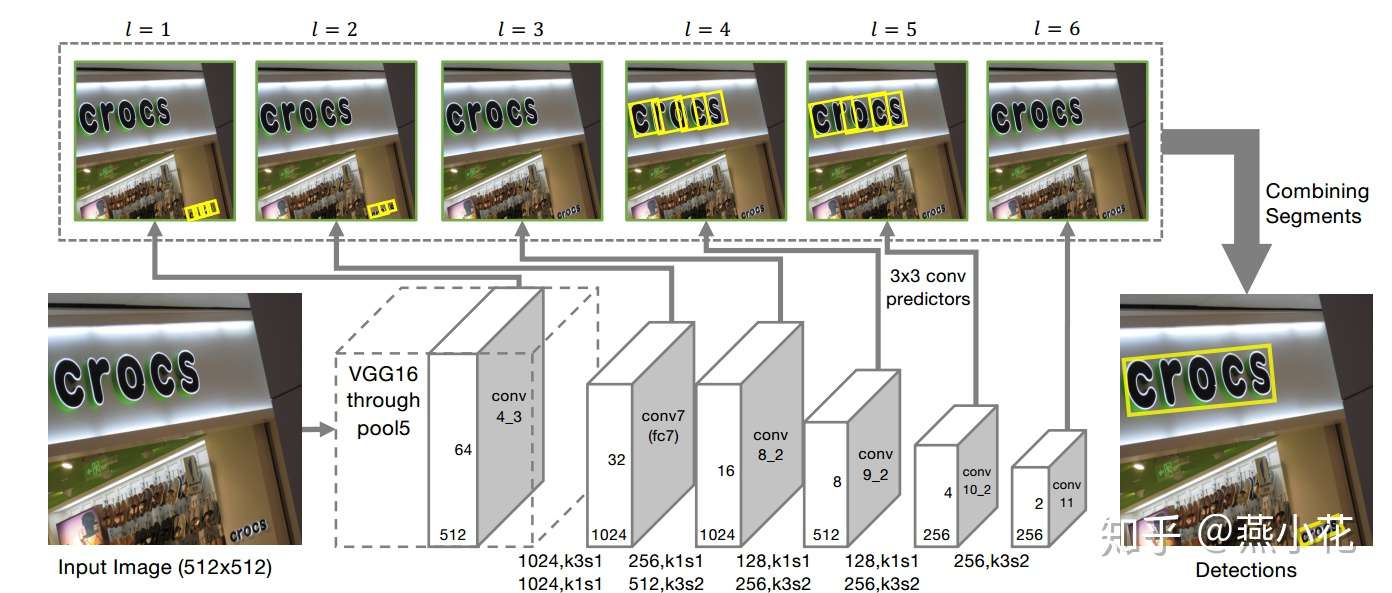
注意:上述结构图中conv8_2的输出应该是512个,因为这层是在conv7层上依次经过256个核大小为1,步长为1的卷积和512个核大小为3,步长为1的卷积核,估计是标错了.
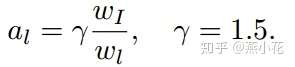
其中分别表示输入图像的宽度和当前feature map的宽度
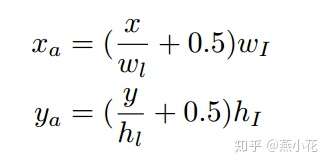
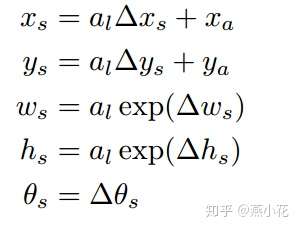
备注:这里感觉论文中计算 的公式有点问题,应该是
和
,,不然感觉原图和特征图对应不上(这里仅是个人猜测,望知道的大侠们指点指点)
总结来说,对于segments的预测包括:2个segment score和5个geometric offsets为
link主要是用于连接上述segment,对于link detection部分,主要分成层内link检测(within-layer)和跨层link检测(cross-layer)
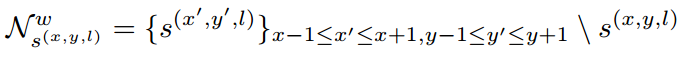
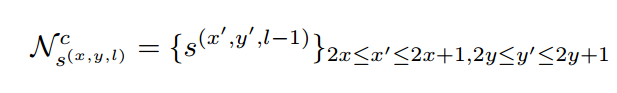
总结来说:对于conv4_3层,其link输出的维度为2*8=16;对于conv7, conv8_2, conv9_2, conv10_2, conv11其输出的link维度为2*8+2*4=24
下图是within-layer link和cross-layer link的邻域可视化图:
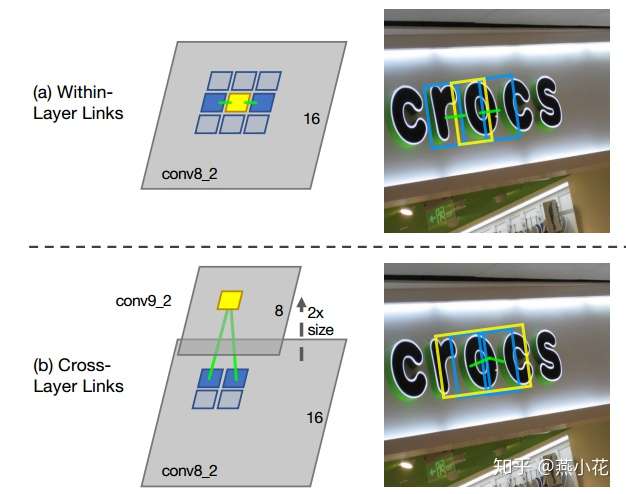
综合上述segment检测和link检测,对于每个feature map,其最后预测的维度如下:
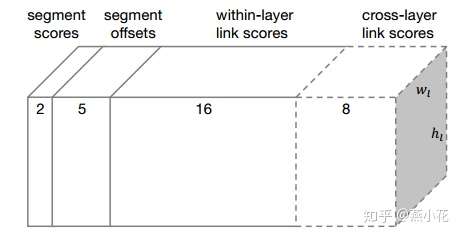
上图中2表示是或不是字的二类分类分数,5表示位置信息x, y, w, h, θ,16表示8个同层的neighbor的连接或者不连接2种情况,8表示前一层的4个neighbor的连接与不连接情况
对于conv4_3:其预测输出维度为: ,因为该层没有cross-layer link
对于conv7, conv8_2, conv9_2, conv10_2, conv11,其预测输出维度为:
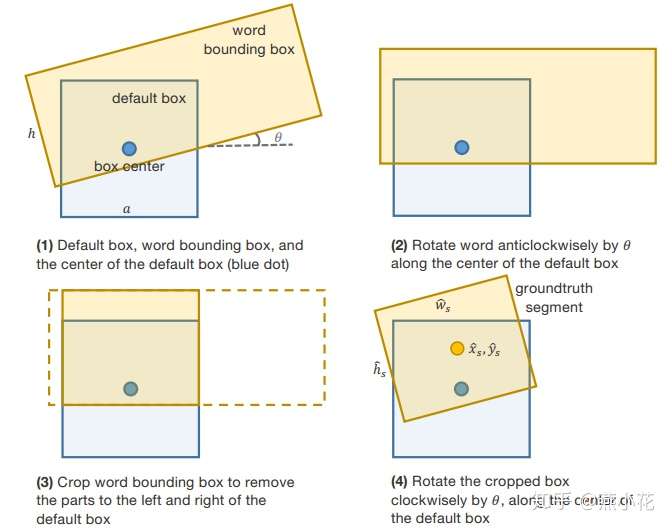
为了更好地理解segment和link,我采用不同的颜色来可视化,每个颜色框表示文中所说的segment,而相邻的颜色框则表示link.具体的segment和link的可视化图如下:


网络的损失函数包括三部分:segment classification损失(softmax),offsets regression损失(L1 regression),link classification损失(softmax),具体公式如下:
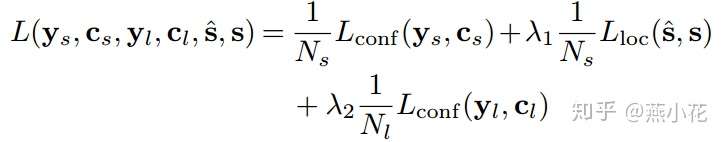
其中控制全中因子λ1 和 λ2设置为1
labels_text.append(b"text"),并在第92行前增加一行img_name=str.encode(img_name),不然会提示str not byte的错误信息#coding=utf-8
################################################
# convert my own dataset to tfrecords
# the label format:x1,yx,x2,y2,x3,y3,x4,y4
# 2018.05.31 add
################################################
import tensorflow as tf
import numpy as np
import os
import cv2
from dataset_utils import int64_feature, float_feature, bytes_feature, convert_to_example
# global variable define
IMAGE_EXTENSION=["jpg","png","bmp","JPG","JPEG","jpeg"]
def load_file(file_path, ext_name=IMAGE_EXTENSION):
"""
load all imgs from the given path
2018.05.31 add
"""
files_paths = []
for root, dirs, files in os.walk(file_path):
for tmp_file in files:
if tmp_file.split(".")[-1] in ext_name:
files_paths.append(os.path.join(root, tmp_file))
return files_paths
def read_img(path):
"""
read img from a given path
2018.05.31 add
"""
img=cv2.imread(path)
if img is None:
return None,None,None
return img,float(img.shape[0]),float(img.shape[1])
def convert_to_tfrecords(file_path,text_path,out_path):
"""
convert my own data to tfrecords
:param file_path: the file path of img
:param text_path: the txt ptah of label
:param out_path: the output path
2018.05.31 add
"""
output_dir = os.path.dirname(out_path)
if not os.path.exists(output_dir):
os.makedirs(output_dir)
img_paths=load_file(file_path)
print("the total img nums is:{}".format(len(img_paths)))
assert len(img_paths)>0,"pls input the right file_path"
with tf.python_io.TFRecordWriter(out_path) as tfrecord_writer:
for idx,path in enumerate(img_paths):
with tf