1. 卡诺模型简介
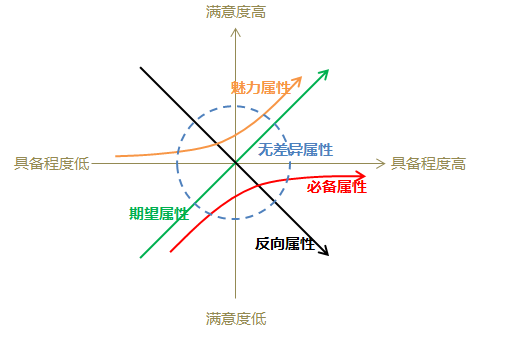
卡诺模型(KANO模型)是对用户需求分类和优先排序的有用工具,以分析用户需求对用户满意的影响为基础,体现了产品性能和用户满意之间的非线性关系。在卡诺模型中,将产品和服务的质量特性分为四种类型:⑴必备属性;⑵期望属性;⑶魅力属性;⑷无差异属性。
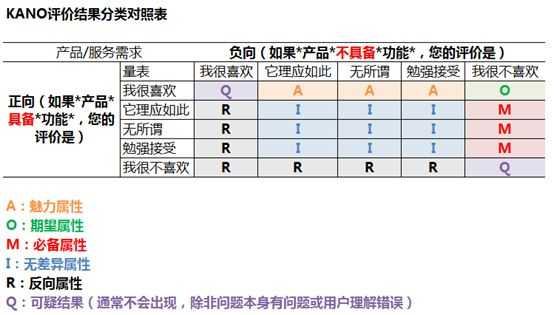
KANO问卷对每个质量特性都由正向和负向两个问题构成,分别测量用户在面对存在或不存在某项质量特性时的反应。
除了对于Kano属性归属的探讨,还可以通过对于功能属性归类的百分比,计算出Better-Worse系数,表示某功能可以增加满意或者消除很不喜欢的影响程度。
Better,可以被解读为增加后的满意系数。better的数值通常为正,代表如果提供某种功能属性的话,用户满意度会提升;正值越大/越接近1,表示对用户满意上的影响越大,用户满意度提升的影响效果越强,上升的也就更快。
Worse,则可以被叫做消除后的不满意系数。其数值通常为负,代表如果不提供某种功能属性的话,用户的满意度会降低;值越负向/越接近-1,表示对用户不满意上的影响最大,满意度降低的影响效果越强,下降的越快。
因此,根据better-worse系数,对系数绝对分值较高的功能/服务需求应当优先实施。
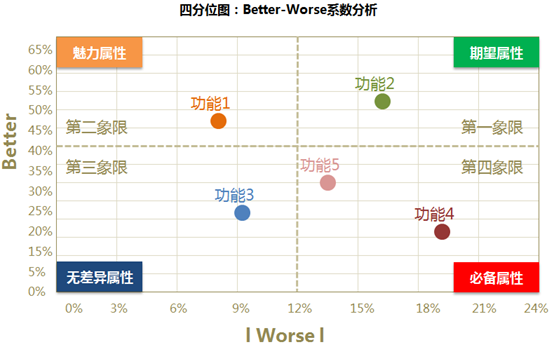
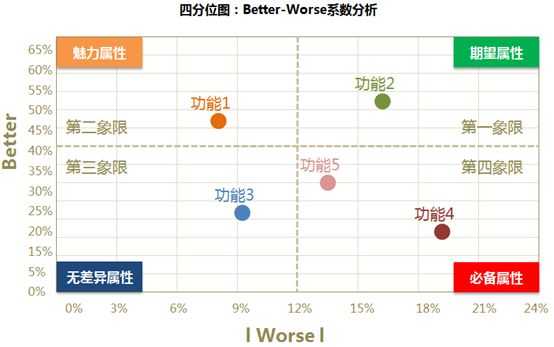
根据better-worse系数值,将散点图划分为四个象限。
同类型功能之间,建议优先考虑better系数较高,worse系数较低的。
在产品开发时,功能优先级的排序一般是:必备属性>期望属性>魅力属性>无差异属性。
但实际需要考虑产品的市场策略,如期望属性和魅力属性是可以击中用户的爽点或痒点的,在争取市场份额上期望属性和魅力属性更为重要,且可以考虑作为产品卖点进行包装营销。
2. 卡诺模型实操
2.1问卷编写:
由于KANO模型问卷均需要了解以下两个方面:用户对于产品/服务具备某功能时的评价(态度)和产品/服务不具备某功能时的评价(态度),需要分别正向和反向地询问用户。需要注意:
① KANO问卷中与每个功能点相关的题目都有正反两个问题,正反问题之间的区别需注意强调,防止用户看错题意;
② 在实际题目设置上,当功能点个数比较多(大于5个时)或功能点的差异不大时,有相似之处时,建议对用户进行分组,每个用户最多回答5个功能点,且尽量是区分度大的功能点。
③ 在题型上,建议优先选择单选题,避免使用阵列题,因为阵列题下,用户更容易乱答或者回答得没有区分度,导致最终各个功能点没有区分度,如都属于期望功能。
④ 功能的解释:简单描述该功能点,确保用户理解;
⑤ 选项说明:由于用户对“我很喜欢”“理应如此”“无所谓”“勉强接受”“我很不喜欢”的理解不尽相同,因此需要在问卷填写前给出统一解释说明,让用户有一个相对一致的标准,方便填答。
⑥ 增加效标以用于验证KANO结果或分人群分析:用户使用功能的频率(后台数据、问卷询问)、用户最喜欢哪个功能(如果各个功能点区分度小时,如都属于期望属性,可从喜爱度上再进行二次划分)、用户会因为哪个功能而选择使用该产品。
2.2数据分析
数据清洗→KANO二维属性归属分析→Better-Worse系数计算。可以直接在Excel或SPSS中进行分析。
此外,还可以结合产品的一些数据支持进行结合分析,如用户画像,UV,转化率等。
2.3数据解读
KANO模型是对功能/服务的优先级进行探索,具体情况还需要和业务方进行讨论,将Kano模型结果和业务实际情况结合讨论确定可行的产品功能开发/优化的优先级顺序,以将调研结果落地实施。
原文:https://www.cnblogs.com/linybo/p/13897548.html