爬虫综合案例
一、网络爬虫基础
1. 网络爬虫介绍
随着互联网的迅速发展,网络资源越来越丰富,信息需求者如何从网络中抽取信息变得至关重要。目前,有效的获取网络数据资源的重要方式,便是网络爬虫技术。简单的理解,比如您对百度贴吧的一个帖子内容特别感兴趣,而帖子的回复却有1000多页,这时采用逐条复制的方法便不可行。而采用网络爬虫便可以很轻松地采集到该帖子下的所有内容。
网络爬虫技术最广泛的应用是在搜索引擎中,如百度、Google、Bing 等,它完成了搜索过程中的最关键的步骤,即网页内容的抓取。下图为简单搜索引擎原理图。
总结:
网络爬虫(Web Crawler),又称为网络蜘蛛(Web Spider)或 Web 信息采集器,是一种按照一定规则,自动抓取或下载网络信息的计算机程序或自动化脚本。
本质:
网络爬虫实际上是通过模拟浏览器的方式获取服务器数据
狭义上理解:
利用标准的 HTTP 协议,根据网络超链接(如https://www.baidu.com/)和 Web 文档检索的方法(如深度优先)遍历万维网信息空间的软件程序。
功能上理解:
确定待爬的 URL 队列,获取每个 URL 对应的网页内容(如 HTML/JSON),解析网页内容,并存储对应的数据。
2. 爬虫的作用
我们初步认识了网络爬虫,但是为什么要学习网络爬虫呢?只有清晰地知道我们的学习目的,才能够更好地学习这一项知识。在此,总结了如下学习爬虫的原因:
- 可以实现搜索引擎
我们学会了爬虫编写之后,就可以利用爬虫自动地采集互联网中的信息,采集回来后进行相应的存储或处理,在需要检索某些信息的时候,只需在采集回来的信息中进行检索,即实现了私人的搜索引擎。
- 大数据时代,可以让我们获取更多的数据源。
在进行大数据分析或者进行数据挖掘的时候,需要有数据源进行分析。我们可以从某些提供数据统计的网站获得,也可以从某些文献或内部资料中获得,但是这些获得数据的方式,有时很难满足我们对数据的需求,而手动从互联网中去寻找这些数据,则耗费的精力过大。此时就可以利用爬虫技术,自动地从互联网中获取我们感兴趣的数据内容,并将这些数据内容爬取回来,作为我们的数据源,再进行更深层次的数据分析,并获得更多有价值的信息。如研究产品个性化推荐、文本挖掘、用户行为模式挖掘等。
- 可以更好地进行搜索引擎优化(SEO)。
对于很多SEO从业者来说,为了更好的完成工作,那么就必须要对搜索引擎的工作原理非常清楚,同时也需要掌握搜索引擎爬虫的工作原理。而学习爬虫,可以更深层次地理解搜索引擎爬虫的工作原理,这样在进行搜索引擎优化时,才能知己知彼,百战不殆。
- 有利于就业。
从就业来说,爬虫工程师方向是不错的选择之一,因为目前爬虫工程师的需求越来越大,而能够胜任这方面岗位的人员较少,所以属于一个比较紧缺的职业方向,并且随着大数据时代和人工智能的来临,爬虫技术的应用将越来越广泛,在未来会拥有很好的发展空间。
3. 爬虫的分类
网络爬虫按照系统架构和实现技术,大致可以分为以下几种类型:
通用网络爬虫(General Purpose Web Crawler)、聚焦网络爬虫(Focused Web Crawler)、增量式网络爬虫(Incremental Web Crawler)、深层网络爬虫(Deep Web Crawler)。
实际的网络爬虫系统通常是几种爬虫技术相结合实现的。
- 通用网络爬虫:
爬行对象从一些种子 URL 扩充到整个 Web,主要为门户站点搜索引擎和大型 Web 服务提供商采集数据。通用网络爬虫的爬取范围和数量巨大,对于爬行速度和存储空间要求较高,对于爬行页面的顺序要求较低,通常采用并行工作方式,有较强的应用价值。
- 聚焦网络爬虫
又称为主题网络爬虫:是指选择性地爬行那些与预先定义好的主题相关的页面。和通用爬虫相比,聚焦爬虫只需要爬行与主题相关的页面,极大地节省了硬件和网络资源,保存的页面也由于数量少而更新快,可以很好地满足一些特定人群对特定领域信息的需求。通常在设计聚焦网络爬虫时,需要加入链接和内容筛选模块。
一个常见的案例是基于关键字获取符合用户需求的数据,如下图所示:
- 增量网络爬虫
对已下载网页采取增量式更新和只爬行新产生的或者已经发生变化网页的爬虫,它能够在一定程度上保证所爬行的页面是尽可能新的页面,历史已经采集过的页面不重复采集。增量网络爬虫避免了重复采集数据,可以减小时间和空间上的耗费。通常在设计网络爬虫时,需要在数据库中,加入时间戳,基于时间戳上的先后,判断程序是否继续执行。
常见的案例有:论坛帖子评论数据的采集(如下图所示论坛的帖子,它包含400多页,每次启动爬虫时,只需爬取最近几天用户所发的帖子);天气数据的采集;新闻数据的采集;股票数据的采集等。
- Deep Web 爬虫
指大部分内容不能通过静态链接获取,只有用户提交一些表单信息才能获取的 Web 页面。例如,需要模拟登陆的网络爬虫便属于这类网络爬虫。
另外,还有一些需要用户提交关键词才能获取的内容,如京东淘宝提交关键字、价格区间获取产品的相关信息。
二、网络爬虫的基本原理
1. 爬虫的流程
网络爬虫基本流程可用下图描述:
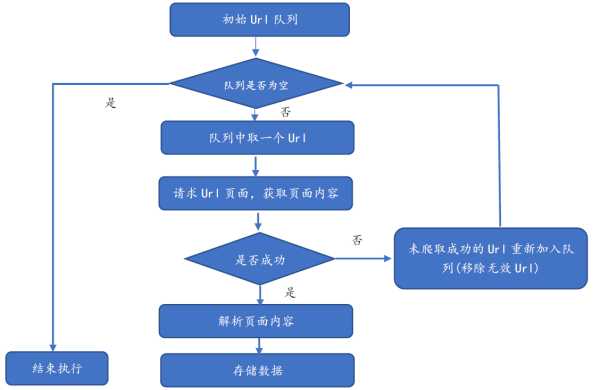
具体流程为:
- 需求者选取一部分种子 URL(或初始 URL),将其放入待爬取的队列中。如在 Java 网络爬虫中,可以放入 LinkedList 或 List 中。
- 判断 URL 队列是否为空,如果为空则结束程序的执行,否则执行第三步骤。
- 从待爬取的 URL 队列中取出待爬的一个 URL,获取 URL 对应的网页内容。在此步骤需要使用响应的状态码(如200,403等)判断是否获取数据,如响应成功则执行解析操作;如响应不成功,则将其重新放入待爬取队列(注意这里需要移除无效 URL)。
- 针对已经响应成功后获取到的数据,执行页面解析操作。此步骤根据用户需求获取网页内容里的部分数据,如汽车论坛帖子的标题、发表的时间等。
- 针对3步骤已解析的数据,将其进行存储。
爬虫的核心三大模块:
发送请求, 获取数据
解析数据
保存数据
4. 爬虫的爬行策略
一般的网络爬虫的爬行策略分为两种:深度优先搜索(Depth-First Search)策略、广度优先搜索(Breadth-First Search)策略。
l 深度优先搜索策略
从根节点的 URL 开始,根据优先级向下遍历该根节点对应的子节点。当访问到某一子节点 URL 时,以该子节点为入口,继续向下层遍历,直到没有新的子节点可以继续访问为止。接着使用回溯的方法,找到没有被访问到的节点,以类似的方式进行搜索。下图给出了理解深度优先搜索的一个简单案例:
l 广度优先搜索策略
也称为宽度优先,是另外一种非常有效的搜索技术,这种方法按照层进行遍历页面。下图可帮助理解广度优先搜索的遍历方式:
基于广度优先的爬虫是最简单的爬取网站页面的方法,也是目前使用较为广泛的方法。
三、Java 爬虫技术
Java 网络爬虫具有很好的扩展性可伸缩性,其是目前搜索引擎开发的重要组成部分。例如,著名的网络爬虫工具 Nutch 便是采用 Java 开发
1. 发送请求, 获取数据
l 使用原生jdk来发送请求
n 发送get请求
|
public class JDKGet {
public static void main(String[] args) throws Exception {
//1. 确定首页URL
String indexUrl = "http://www.itcast.cn?username=zhangsan"; // 主要 url必须要携带协议(最好通过浏览器先访问一下, 如果能够访问到, 直接全部复制过来)
//2. 发送请求获取数据
//2.1: 创建一个 URL 对象
URL url = new URL(indexUrl);
//2.2: 获取一个远程的连接对象
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
///urlConnection.setRequestMethod("GET"); 默认值就是GET
//2.3: 获取数据: 响应体
InputStream inputStream = urlConnection.getInputStream();
int len ;
byte[] b = new byte[1024];
while( (len = inputStream.read(b)) != -1){
System.out.println( new String(b,0,len));
}
//3. 释放资源
inputStream.close();
}
}
|
n 发送post请求
|
public class JDKPost {
public static void main(String[] args) throws Exception {
//1. 确定首页url
String indexUrl = "http://www.itcast.cn";
//2. 发送请求 获取数据
//2.1: 创建 URL对象, 将url放置在URL对象中
URL url = new URL(indexUrl);
//2.2: 打开一个连接
HttpURLConnection httpURLConnection = (HttpURLConnection) url.openConnection();
//2.3: 设置请求方式为 POST
httpURLConnection.setRequestMethod("POST");
//2.4: 获取到输出流, 进行数据的发送操作
httpURLConnection.setDoOutput(true); // 在获取输出流之前, 打开输出流, 默认情况原始JDK 关闭掉输出流
OutputStream outputStream = httpURLConnection.getOutputStream();
outputStream.write("username=zhangsan&password=123".getBytes()); // 注意这个请求是我瞎传的, 本身这个路径不需要传递任何参数, 此时只是模拟告知如何传递参数
//2.5:获取输入流对象, 进行数据的接收操作
InputStream inputStream = httpURLConnection.getInputStream();
int len ;
byte[] b = new byte[1024];
while( (len = inputStream.read(b)) != -1 ){
System.out.println(new String(b,0,len));
}
//3. 释放资源
inputStream.close();
outputStream.close();
}
}
|
小结:
当需要发送请求体的时候, 需要使用输出流来进行写出, 同时需要注意, 原生jdk,默认将输出流是关闭的
需要获取响应体的时候, 需要使用输入流来获取
l 使用httpClient发送请求
httpClient是专门用来发送http请求的工具包,其底层其实就是对原生JDK的高阶包装, 内部对IO流进行高效封装, 以达到更加高效的特性, 在实际使用中, 一般使用httpClient, 在jdk1.9版本以上已经自带httpClient,如果在jdk1.9以下使用, 需要进行导包操作
n 如果要使用httpClient, 首先需要先导包
<!-- 第一步: 导包 -->
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.4</version>
</dependency>
n 使用httpClient发送get请求
|
public class HttpClientGet {
public static void main(String[] args) throws Exception {
//1. 确定首页url
String indexUrl = "http://www.itcast.cn";
//2. 发送请求 获取数据
//2.1: 创建HttpClient对象: 理解为这个对象就是一个 浏览器
CloseableHttpClient httpClient = HttpClients.createDefault(); // 固定写法
//2.2: 创建 请求方式的对象: 请求对象
HttpGet httpGet = new HttpGet(indexUrl);
//2.3: 设置请求对象: 设置请求头
httpGet.setHeader("User-Agent","Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36");
//2.4: 发送请求, 获取响应对象
CloseableHttpResponse response = httpClient.execute(httpGet);
//2.5: 从响应对象中获取数据
int statusCode = response.getStatusLine().getStatusCode();
System.out.println("状态码:"+statusCode);
if(statusCode == 200){ // 请求成功了
// 获取响应头
Header[] headers = response.getHeaders("Content-Type");
for (Header header : headers) {
String value = header.getValue();
System.out.println(value);
}
// 获取 响应体
HttpEntity httpEntity = response.getEntity(); //获取HTTPEntity 对象 (响应体对象)
//InputStream inputstream = httpEntity.getContent(); // 如果获取 图片 视频 声音 , 必须使用字节输入流, 如果是文本, 此处不需要这样获取
String html = EntityUtils.toString(httpEntity,"UTF-8"); // 如果返回的是文本, 请使用这种方式直接获取
System.out.println(html);
}
//2.6: 释放资源
httpClient.close();
}
}
|
n 使用httpClient发送post请求
|
public class HttpClientPost {
public static void main(String[] args) throws Exception {
//1. 确定首页URL
String indexUrl = "http://www.itcast.cn";
//2. 发送请求, 获取数据
//2.1: 创建 httpClient对象
CloseableHttpClient httpClient = HttpClients.createDefault();
//2.2: 创建请求方式的对象: POST
HttpPost httpPost = new HttpPost(indexUrl);
//2.3: 设置请求对象的信息: 请求头 和 请求体
httpPost.setHeader("User-Agent","Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36");
List<BasicNameValuePair> list = new ArrayList<BasicNameValuePair>();
list.add( new BasicNameValuePair("username","zhangsan"));
list.add( new BasicNameValuePair("password","123456"));
list.add( new BasicNameValuePair("age","20"));
HttpEntity httpEntity = new UrlEncodedFormEntity(list);
httpPost.setEntity(httpEntity);
//2.4: 发送请求, 获取响应对象
CloseableHttpResponse response = httpClient.execute(httpPost);
//2.5: 获取数据操作
int statusCode = response.getStatusLine().getStatusCode();
System.out.println("状态码:" +statusCode );
if(statusCode == 200){
HttpEntity entity = response.getEntity();
String html = EntityUtils.toString(entity, "UTF-8");
System.out.println(html);
}
// 2.6 释放资源
httpClient.close();
}
}
|
小结:使用httpClient发送请求的步骤
1) 获取httpClient对象
2) 指定请求方式: get / post
3) 封装请求参数: 封装请求头和请求体
在进行请求体的封装的时候: 需要使用的UrlEncodedFormEntity来封装数据
4) 执行请求
5) 获取结果
5. 解析数据 JSoup
https://www.open-open.com/jsoup/
我们抓取到页面之后,还需要对页面进行解析。可以使用字符串处理工具解析页面,也可以使用正则表达式,但是这些方法都会带来很大的开发成本,所以我们需要使用一款专门解析html页面的技术。
jsoup 是一款基于 Java 语言的 HTML 请求及解析器,可直接请求某个 URL 地址、解析 HTML 文本内容。它提供了一套非常省力的 API,可通过 DOM、CSS 以及类似于 jQuery 的操作方法来取出和操作数据。
jsoup的主要功能如下:
- 从一个URL,文件或字符串中解析HTML;
- 使用DOM或CSS选择器来查找、取出数据;
- 可操作HTML元素、属性、文本;
注意:
虽然使用Jsoup可以替代HttpClient直接发起请求解析数据,但是往往不会这样用,因为实际的开发过程中,需要使用到多线程,连接池,代理等等方式,而jsoup对这些的支持并不是很好,所以我们一般把jsoup仅仅作为Html解析工具使用
jsoup 一个重要用途是解析 HTML 文件,在开始用之前,必须弄清 jsoup 中的 Node、Element、Document 的相关概念及区别,防止因概念混淆而导致乱用错用。
n 1) Node(节点):HTML 中所包含的内容都可以看成一个节点。节点有很多种类 型:属性节点(Attribute)、注释节点(Note)、文本节点(Text)、元素节点(Element)等。解析 HTML 内容的过程,其实就是对节点操作的过程。
n 2) Element(元素):元素是节点的子集,所以一个元素也是一个节点。
n 3) Document(文档):指整个 HTML 文档的源码内容。
如何来使用jsoup呢?
l 1) 先进行导包操作:
|
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.3</version>
</dependency>
|
l 1) 如何获取document对象
|
public class JsoupDoc {
public static void main(String[] args) throws Exception {
//1. 确定首页的url
String indexUrl = "http://www.itcast.cn";
//2. 发送请求, 获取数据
//3. 解析数据
//3.1: 获取document对象 (方式一) __ 只在测试中使用, 一般不直接来获取, 因为这种方式不适合设置请求头和请求体...
Document document1 = Jsoup.connect(indexUrl).get(); // 发送请求, 获取数据, 将获取到数据直接转换为一个document对象
System.out.println(document1);
//3.2: 使用jsoup 获取对应文档的document对象 (方式二)___ 将一个html的文本, 直接转换为document对象 (最常用的方式)
String html = "<!DOCTYPE html>\n" +
"<html lang=\"en\">\n" +
"<head>\n" +
" <meta charset=\"UTF-8\">\n" +
" <title>方式二:通过jsoup获取document对象</title>\n" +
"</head>\n" +
"<body>\n" +
" \n" +
"</body>\n" +
"</html>" ;
Document document2 = Jsoup.parse(html);
String title = document2.title();
System.out.println(title);
//3.3: 使用jsoup 获取对应文档的document对象 (方式三) ___ 读取一个外部的html文件的方式, 将这个文件内容转换为document对象
// Document document3 = Jsoup.parse(new File(""), "UTF-8");
//3.4: 使用jsoup 获取对应文档的document对象 (方式四)___ 基本html片段的方式, 来获取document对象 __ 一般不使用, 因为可以被第二种替代
// Document document4 = Jsoup.parseBodyFragment("<a href =‘http://www.baidu.com‘>跳转百度</a><span>我是span</span>");
Document document4 = Jsoup.parse("<a href =‘http://www.baidu.com‘>跳转百度</a><span>我是span</span>");
System.out.println(document4);
}
}
|
l 2)案例一: 获取传智博客官网的课程类别
|
public class ItcastSpider {
public static void main(String[] args) throws Exception {
//1. 确定首页URL
String indexUrl = "http://www.itcast.cn/";
//2. 发送请求, 获取数据
//3. 解析数据
/*Document document = Jsoup.connect(indexUrl).get();
// 通过选择器的方式来解析数据: 参数就是 css的选择器 内容
Elements lis = document.select(".ulon>li");
for (Element li : lis) {
Elements as = li.select("a");
String value1 = as.text(); // 获取标签中内容体 __ 只获取内容体, 去除掉标签
// String value2 = as.html(); // 获取标签中内容体_ 将标签中所有的内容都获取(包含标签)
System.out.println(value1);
}*/
Document document = Jsoup.connect(indexUrl).get();
Elements as = document.select(".ulon>li>a");
for (Element a : as) {
System.out.println(a.text());
}
}
}
|
l 3) 案例二: 使用jsoup爬取163的某一篇新闻数据
|
public class News163Spider {
public static void main(String[] args) throws Exception {
//1. 确定首页url
String indexUrl = "https://news.163.com/20/0720/09/FHVHQ2N80001899O.html";
//2. 发送请求, 获取数据
//3. 解析数据操作
Document document = Jsoup.connect(indexUrl).get();
//System.out.println(document);
//3.1: 获取新闻的标题
Elements h1s = document.select("#epContentLeft>h1");
String title = h1s.text();
System.out.println(title);
//3.2: 获取新闻时间
Elements timeAndSourceEls = document.select(".post_time_source");
String timeAndSource = timeAndSourceEls.text();
String time = timeAndSource.split(" ")[0];
System.out.println(time);
//3.3: 获取来源
String source = document.select("#ne_article_source").text();
System.out.println(source);
//3.4: 获取正文内容
Elements ps = document.select("#endText>p");
for (Element p : ps) {
System.out.println(p.text());
}
//3.5: 获取新闻的作者
String sourceAndAuthor = document.select(".left").text();
String author = sourceAndAuthor.split(" ")[1];
System.out.println(author);
}
}
|
6. 保存数据:
将解析后的数据, 保存到数据库或者文件中, 目前采用的MySQL, 后期可以使用hadoop, hbase等
保存数据的技术采用:
JDBC+C3P0连接池实现即可
IO流
爬虫综合案例
原文:https://www.cnblogs.com/shan13936/p/13904317.html