要求:通过给定的文件,选取文件中的导演与演员信息,并且将导演与每个演员的合作次数做一个整理

1 import numpy as np 2 import pandas as pd 3 # 不发出警告 4 import warnings 5 warnings.filterwarnings(‘ignore‘) 6 导入系统os模块 7 import os
第一步:利用os模块,将默认文件夹改为目标文件夹
1 # 这里的文件夹全路径根据电脑里面存储文件所在的位置具体填写 2 os.chdir("D:\BaiduNetdiskDownload\数据分析网易\【非常重要】课程资料等多个文件\【非常重要】课程资料\CLASSDATA_ch05数据表达逻辑:结果输出及内容美化\CLASSDATA_ch05数据表达逻辑:结果输出及内容美化\CH03关系网络图表可视化\ch0304_data") 3 4 # 读取excel数据 5 df = pd.read_excel("豆瓣电影数据.xlsx", sheet_name=0, header=0) 6 7 # 查看数据信息 8 print("数据总共:%i条" % len(df)) 9 print("数据字段为:\n", df.columns.tolist()) 10 df.head(3)
查看文件数据的结果为:

第二步:进行数据清洗,提取需要的电影名字,导演,演员数据
1 # 提取导演,主演,电影名字数据 2 data = df[["name", "主演", "导演"]] 3 print(data.head(1)) 4 5 # 删除数据缺失值,并且替换原data数据 6 data.dropna(inplace=True) 7 8 # 获取演员信息,并且将它进行分割,生成一个新的df(expand字段的作用) 9 data_yy = data["主演"].str.split("/", expand=True) 10 data_yy.columns = ["yy" + str(i) for i in range(len(data_yy.columns))] 11 # 清洗后的演员数据 12 print(data_yy.head(1)) 13 14 data_dy = data["导演"].str.split("/", expand= True) 15 data_dy.columns = ["dy" + str(i) for i in range(len(data_dy.columns))] 16 # 清洗后的导演数据 17 print(data_dy.head(1)) 18 19 # 合并清洗完的导演,演员,电影名字数据 20 data_he = data_dy.join(data_yy).join(data["name"]) 21 22 #想查看为什么演员数据会有64列,这个代码是查看有64列的演员数据的电影信息 23 data_he[data_he["yy64"].notnull()] 24 data_he.head(1)
查看从原数据中提取的数据结果:
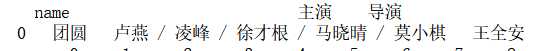
经过数据清洗,并重新生成的演员导演df数据:
65列演员信息:

12列导演信息
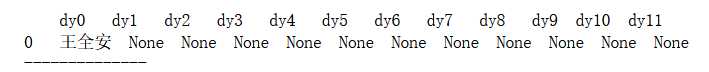
经过清洗过后重新生成的电影,导演,演员df数据:

第三步:将合并的df数据里面的按照导演,演员,名字进行分组成详细数据
1 # 定义一个空的,新的df数据 2 data_new = pd.DataFrame(columns=["name", "导演", "演员"]) 3 # 获取演员df和导演df的columns列表信息 4 col_yy = data_yy.columns 5 col_dy = data_dy.columns 6 7 # 遍历合并的df,将导演与演员一一对应,并且去除空数据 8 for yy in col_yy: 9 for dy in col_dy: 10 data_i = data_he[["name", dy, yy]].dropna() 11 data_i.columns = ["name", "导演", "演员"] 12 #将空的df数据与信生成的df数据进行连表操作 13 data_new = pd.concat([data_new, data_i]) 14 print(data_new.head())
新生成的导演,演员,电影数据关系表格:

第四步:将新生成的数据按照,导演,演员进行分组操作,并且结算合作次数
1 result = data_new.groupby(["导演", "演员"]).count() 2 #生成的数据由于有一对多的单元格展示,使用 reset_index()将所有索引级别转换为列, 3 result.reset_index(inplace=True) 4 result.columns=["导演", "演员", "合作次数"] 5 print(result.head())
查看新生成的df数据信息:

第五步:将新生成的数据保存到目标文件夹中
1 writer = pd.ExcelWriter(‘teamwork.xlsx‘) 2 result.to_excel(writer,‘sheet1‘) 3 writer.save() 4 5 print("finished")
至此,数据清洗完毕,大功告成
原文:https://www.cnblogs.com/dickliang/p/13904881.html
