在做主题聚类时,主要经过以下几个步骤:
1、数据清洗:因为我是基于新浪微博来做主题的,所以需要先清洗掉数据中的各种表情符号(emoji等),以及多余的符号,清洗后再去重,会发现数据量少很多。
2、分词:这里我使用的是jieba分词,并使用了专用的词典(user_dict.txt),同时网上下载了stopwords.txt。
3、lda模型训练:这里经过了建立词典、转换文本为索引并计数、计算tf-idf值、训练lda模型等步骤,具体代码如下所述(转载自博客:https://www.jianshu.com/p/9918cd4d09c1,亲测有效):
# -*- coding:utf-8 -*- " Created on Mon Aug 19 14:56:19 2019 @author: Luxuriant " import numpy as np from gensim import corpora, models, similarities from pprint import pprint import time # import logging # logging.basicConfig(format=‘%(asctime)s : %(levelname)s : %(message)s‘, level=logging.INFO) def load_stopword(): ‘‘‘ 加载停用词表 :return: 返回停用词的列表 ‘‘‘ f_stop = open(‘stopwords.txt‘, encoding=‘utf-8‘) sw = [line.strip() for line in f_stop] f_stop.close() return sw if __name__ == ‘__main__‘: print(‘1.初始化停止词列表 ------‘) # 开始的时间 t_start = time.time() # 加载停用词表 stop_words = load_stopword() print(‘2.开始读入语料数据 ------ ‘) # 读入语料库 f = open(‘乡贤形象文本-cutfile.txt‘, encoding=‘utf-8‘) # 语料库分词并去停用词 texts = [[word for word in line.strip().lower().split() if word not in stop_words] for line in f] print(‘读入语料数据完成,用时%.3f秒‘ % (time.time() - t_start)) f.close() M = len(texts) print(‘文本数目:%d个‘ % M) print(‘3.正在建立词典 ------‘) # 建立字典 dictionary = corpora.Dictionary(texts) V = len(dictionary) print(‘4.正在计算文本向量 ------‘) # 转换文本数据为索引,并计数 corpus = [dictionary.doc2bow(text) for text in texts] print(‘5.正在计算文档TF-IDF ------‘) t_start = time.time() # 计算tf-idf值 corpus_tfidf = models.TfidfModel(corpus)[corpus] print(‘建立文档TF-IDF完成,用时%.3f秒‘ % (time.time() - t_start)) print(‘6.LDA模型拟合推断 ------‘) # 训练模型 num_topics = 30 t_start = time.time() lda = models.LdaModel(corpus_tfidf, num_topics=num_topics, id2word=dictionary, alpha=0.01, eta=0.01, minimum_probability=0.001, update_every=1, chunksize=100, passes=1) print(‘LDA模型完成,训练时间为\t%.3f秒‘ % (time.time() - t_start)) # 随机打印某10个文档的主题 num_show_topic = 10 # 每个文档显示前几个主题 print(‘7.结果:10个文档的主题分布:--‘) doc_topics = lda.get_document_topics(corpus_tfidf) # 所有文档的主题分布 idx = np.arange(M) np.random.shuffle(idx) idx = idx[:10] for i in idx: topic = np.array(doc_topics[i]) topic_distribute = np.array(topic[:, 1]) # print topic_distribute topic_idx = topic_distribute.argsort()[:-num_show_topic - 1:-1] print(‘第%d个文档的前%d个主题:‘ % (i, num_show_topic)), topic_idx print(topic_distribute[topic_idx]) num_show_term = 10 # 每个主题显示几个词 print(‘8.结果:每个主题的词分布:--‘) for topic_id in range(num_topics): print(‘主题#%d:\t‘ % topic_id) term_distribute_all = lda.get_topic_terms(topicid=topic_id) term_distribute = term_distribute_all[:num_show_term] term_distribute = np.array(term_distribute) term_id = term_distribute[:, 0].astype(np.int) print(‘词:\t‘, ) for t in term_id: print(dictionary.id2token[t], ) print(‘\n概率:\t‘, term_distribute[:, 1])
部分效果图如下:
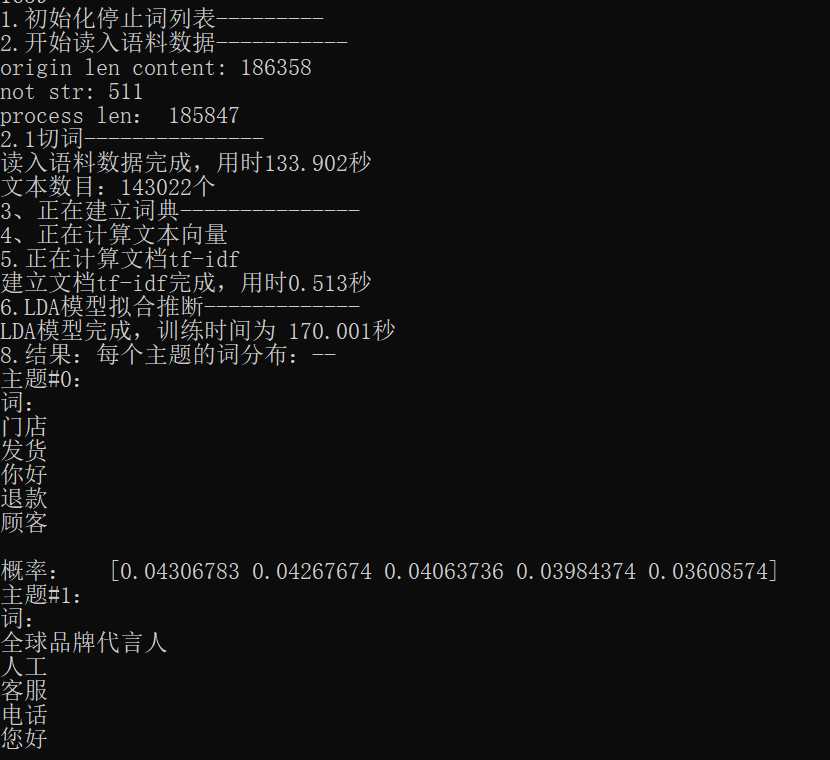
原文:https://www.cnblogs.com/mj-selina/p/13927699.html