pdf:Session-based Recommendation with Graph Neural Networks(SR-GNN)
参考博客:https://sxkdz.github.io/research/SR-GNN/
摘要
基于会话的推荐问题旨在预测基于匿名会话的用户操作。先前的方法将会话建模为序列,并估计项目表示以外的用户表示,以提出建议。尽管取得了可喜的结果,但它们不足以在会话中获得准确的用户向量,而忽略了项目的复杂转换。为了获得准确的项目嵌入并考虑到项目的复杂过渡,我们提出了一种新颖的方法,即基于会话的Graph Neural Networks,SR-GNN的推荐。在提出的方法中,会话序列被建模为图结构数据。基于会话图,GNN可以捕获项目的复杂转换,这是以前的常规顺序方法难以揭示的。然后,使用注意力网络将每个会话表示为该会话的全局偏好和当前兴趣的组成。在两个真实数据集上进行的大量实验表明,SR-GNN明显优于基于会话的最新推荐方法。
RNN不足:
- 不能够得到用户的精确表示
- 忽略了条目之间的转移关系
1 介绍
随着Internet上信息量的快速增长,推荐系统成为帮助用户减轻信息过载问题并在许多Web应用程序(例如搜索,电子商务和媒体流站点)中选择有趣信息的基础。现有的大多数推荐系统都假定不断记录用户个人资料和过去的活动。但是,在许多服务中,用户标识可能是未知的,并且只有正在进行的会话期间的用户行为历史可用。因此,在一个会话中对受限行为进行建模并相应地生成推荐非常重要。相反,在这种情况下,依靠足够的用户项交互作用的常规建议方法在产生准确结果方面存在问题。
由于具有很高的实用价值,因此可以观察到对此问题的研究日益增多,并且针对基于会话的推荐提出了许多建议。根据马尔可夫链,一些工作(Shani,Brafman和Heckerman 2002; Rendle,Freudenthaler和Schmidt-Thieme 2010)根据用户的前一个行为预测用户的下一个行为。假设有很强的独立性,过去组件的独立组合会限制预测精度。
近年来,大多数研究(Hidasi等。2016年; Tan,Xu和Liu 2016; Tuan和Phuong 2017; Li等。 2017a)将递归神经网络(RNN)应用于基于会话的推荐系统并获得有希望的结果。这项工作(Hidasi等人,2016a)首先提出了递归神经网络方法,然后通过数据扩充和考虑用户行为的时间变化来增强该模型(Tan,Xu和Liu,2016)。最近,NARM(Li等,2017a)设计了一个全局和本地RNN推荐器,以同时捕获用户的顺序行为和主要目的。与NARM,STAMP类似(Liu等。2018)还通过使用简单的MLP网络和细心的网络来捕获用户的总体兴趣和兴趣。
尽管上述方法取得了令人满意的结果并成为最新技术,但它们仍然有一些局限性。首先,在没有足够的用户行为的情况下,这些方法难以估计用户代表。通常,这些RNN方法的隐藏向量被视为用户表示,因此可以基于这些表示(例如NARM的全球推荐者)生成建议。然而,在基于会话的推荐系统中,会话大多是匿名的,并且会话众多,并且与会话点击相关的用户行为通常受到限制。因此,难以从每个会话中准确地估计每个用户的表示。其次,先前的工作表明,项目过渡的模式很重要,可以用作基于会话的推荐中的本地因素(Li等人2017a; Liu等人2018),但是这些方法始终为单向过渡建模在连续项目之间切换,而忽略上下文之间的过渡,即会话中的其他项目。因此,这些方法忽略了十个遥远项之间的复杂过渡。
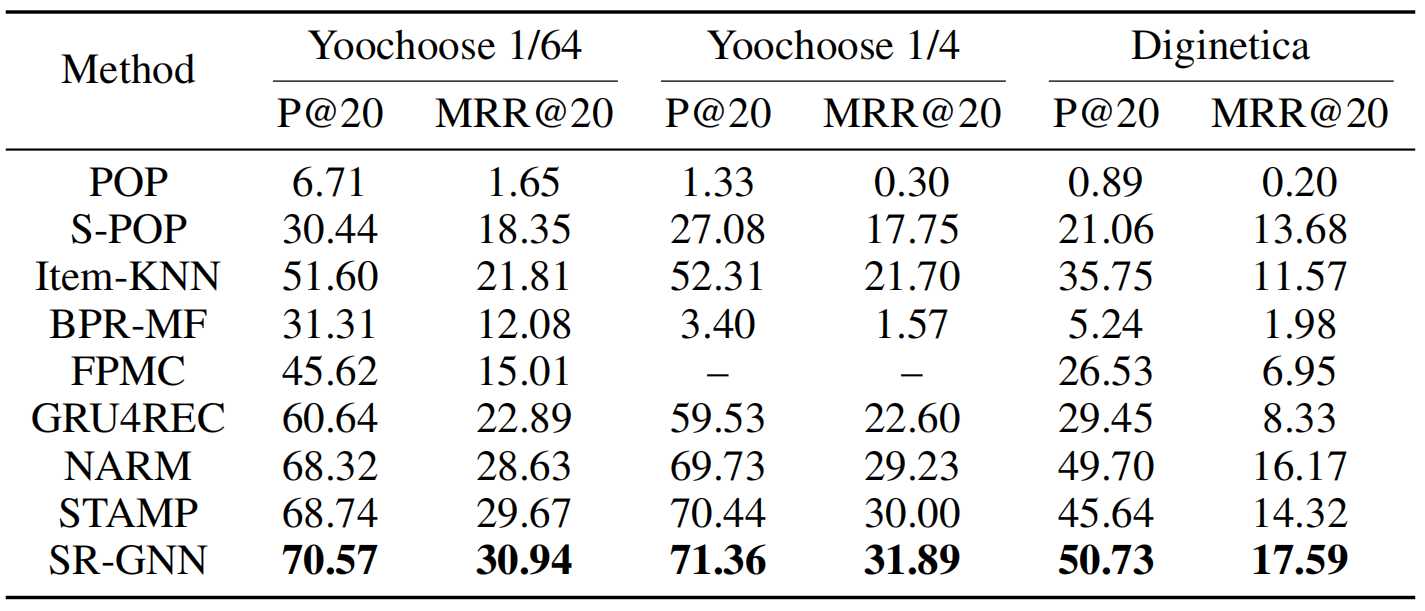
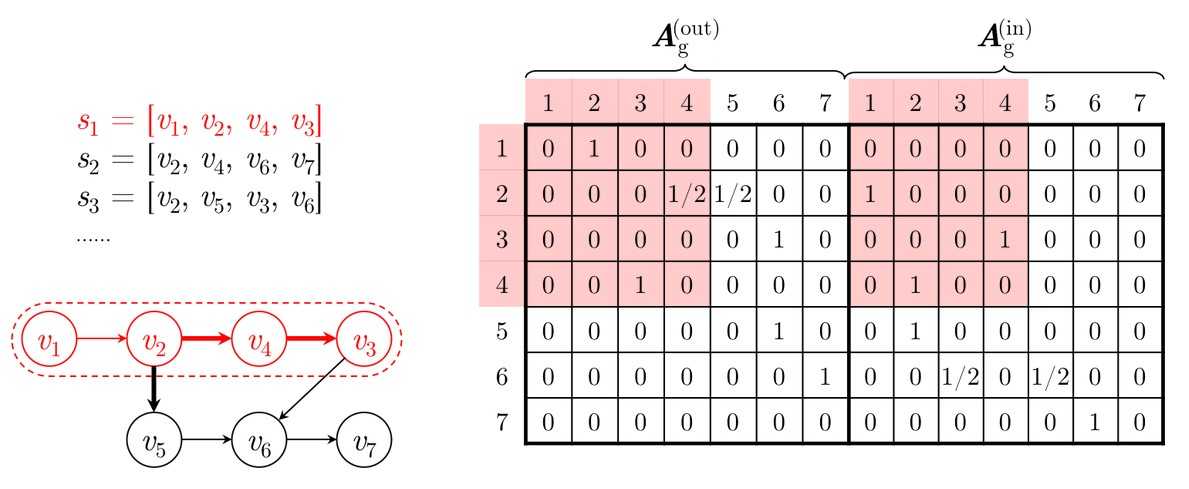
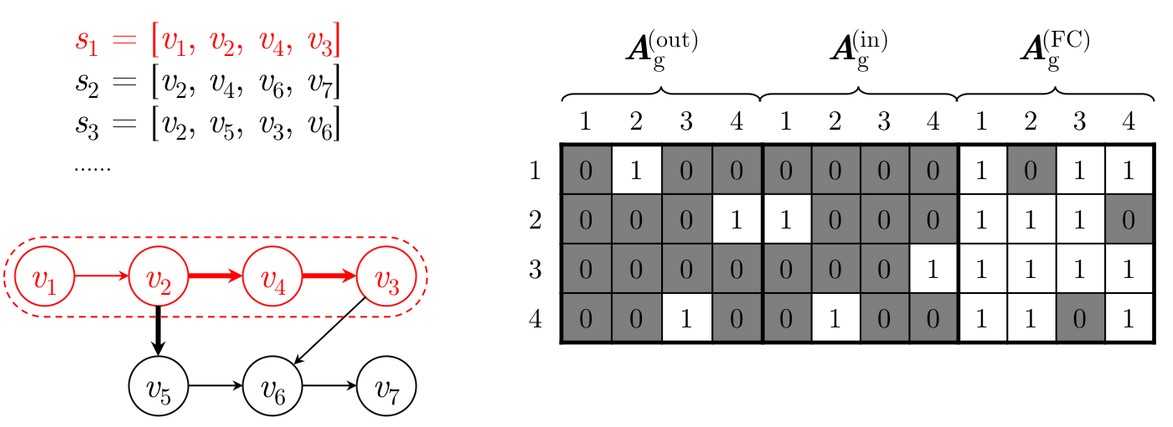
为克服上述限制,我们提出了一种新颖的方法,用于基于会话的图神经网络推荐,SR-GNN简洁,可以显示项目之间的丰富过渡,并生成项目的准确潜在向量。图神经网络(GNN)(Scarselli et al.2009; Li et al.2015)设计用于生成图的表示。最近,它被广泛用于为自然语言处理和计算机视觉应用蓬勃发展的图形结构相关性建模,例如脚本事件预测(Li,Ding和Liu 2018),情况识别(Li等人2017b)。 ,以及图片分类(Marino,Salakhutdinov和Gupta 2017)。对于基于会话的推荐,我们首先从历史会话序列中构造直接图。基于会话图,GNN能够捕获项目的过渡并相应地生成准确的项目嵌入向量,而传统的顺序方法(如基于MC和基于RNN的方法)很难揭示这些内容。基于准确的项目嵌入向量,所提出的SR-GNN构造了更可靠的会话表示,并且可以推断出下次点击的项目。
图1说明了所建议的SR GNN方法的工作流程。首先,将所有会话序列建模为有向会话图,其中每个会话序列都可以视为子图。然后,依次对每个会话图进行处理,并可以通过门控图神经网络获得每个图所涉及的所有节点的潜在向量。之后,我们将每个会话表示为该会话中全局优先级和用户当前兴趣的组合,其中这些全局和本地会话嵌入向量都由节点的潜在向量组成。最后,对于每个会话,我们预测每个项目的概率为下一次单击。在现实世界中具有代表性的数据集上进行的大量实验证明了该方法在最新技术方面的有效性。这项工作的主要贡献概括如下:
?我们将分离的会话序列建模为图结构化数据,并使用图神经网络捕获复杂的项转换。据我们所知,它为基于会话的推荐场景中的建模提出了一种新颖的观点。
?要生成基于会话的建议,我们不依赖于用户表示,而是使用会话嵌入,仅可基于每个单个会话中涉及的潜在项目矢量来获得会话嵌入。
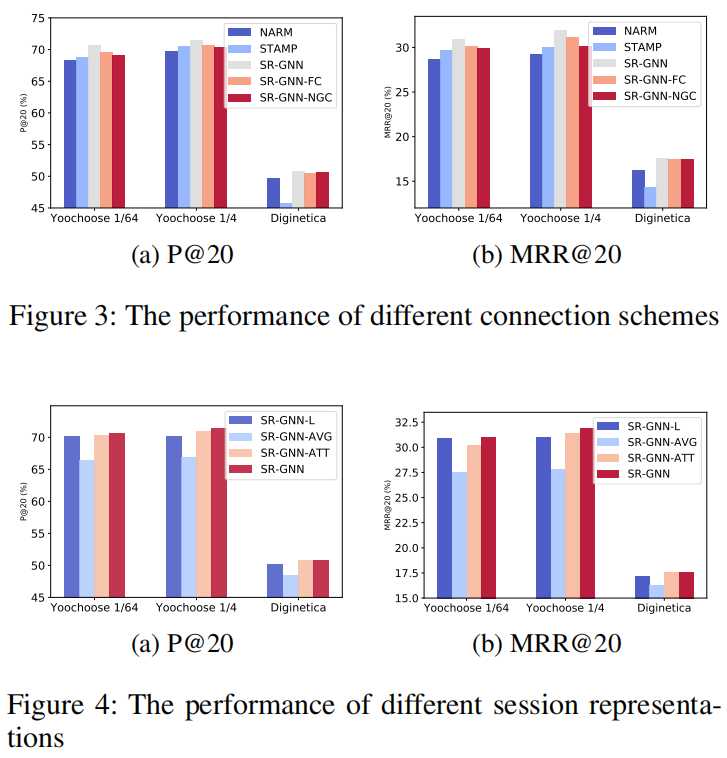
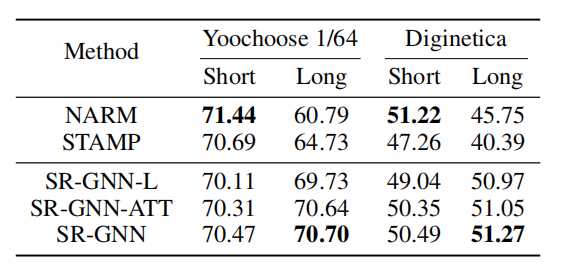
?在现实世界的数据集上进行的广泛实验表明,SR-GNN明显优于最新方法。
为了使我们的结果完全可重复,所有相关源代码已在https://github.com/CRIPAC-DIG/SR-GNN上公开。
本文的其余部分安排如下。我们在第2节中回顾了先前的相关文献。第3节介绍了使用图神经网络的基于会话的推荐方法。详细的实验结果和分析显示在第4节中。最后,在第5节中总结本文。
2 相关工作
在本节中,我们回顾基于会话的推荐系统的一些相关工作,包括常规方法,基于马尔可夫链的顺序方法以及基于RNN的方法。然后,我们介绍图上的神经网络。
常规推荐方法。矩阵因子化(Mnih和Salakhutdinov 2007; Koren,Bell和Volinsky 2009; Koren和Bell 2011)是推荐系统的通用方法。基本目标是将用户-项目评分矩阵简化为两个低等级矩阵,每个矩阵代表用户或项目的潜在因素。它不太适合基于会话的建议,因为用户偏好仅由某些肯定的点击提供。基于项目的邻域方法(Sar war等人,2001)是一种自然的解决方案,其中项目相似度是基于同一会话中的共现来计算的。这些方法难以考虑项目的顺序,并且仅基于最后的点击来生成预测。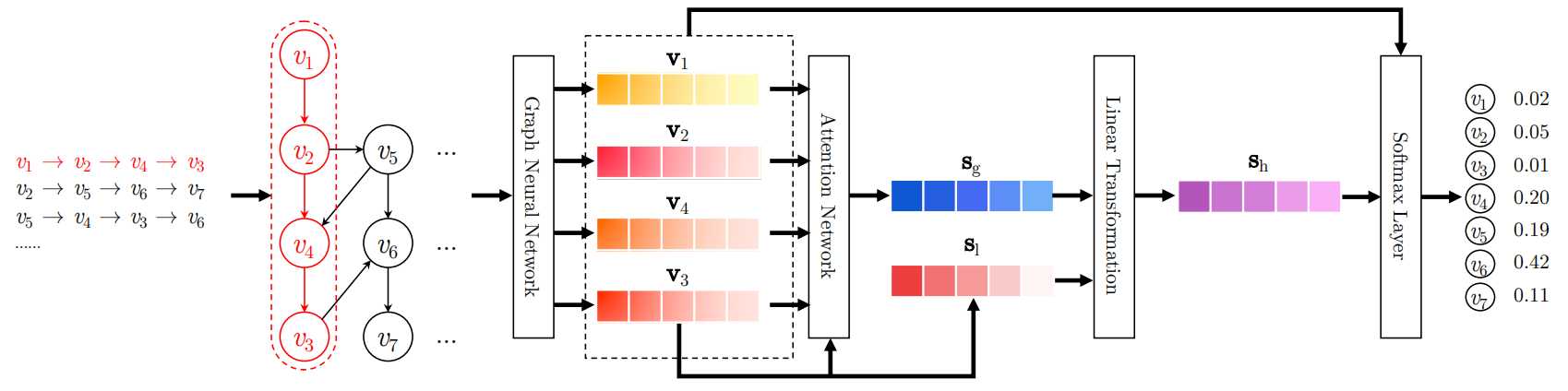
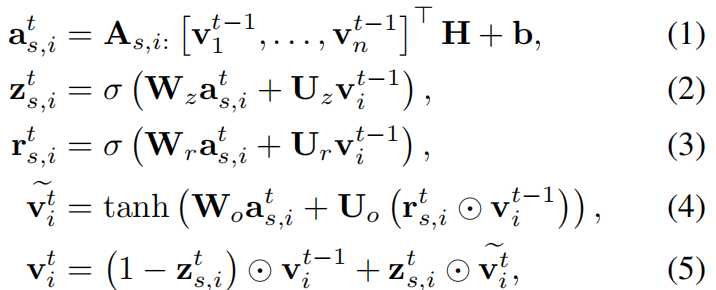
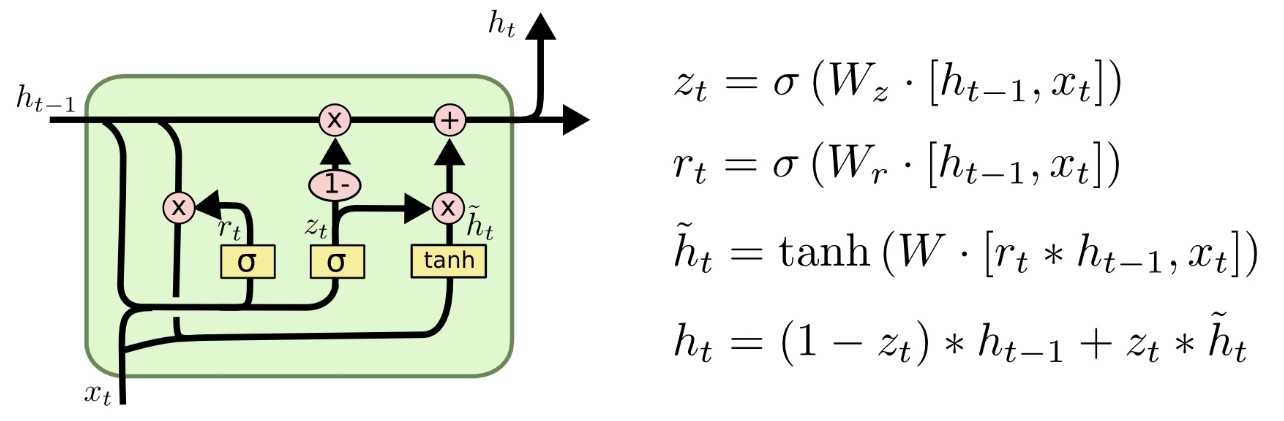
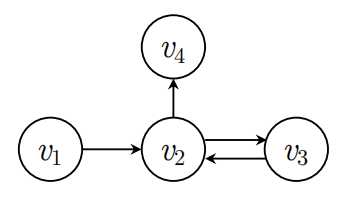
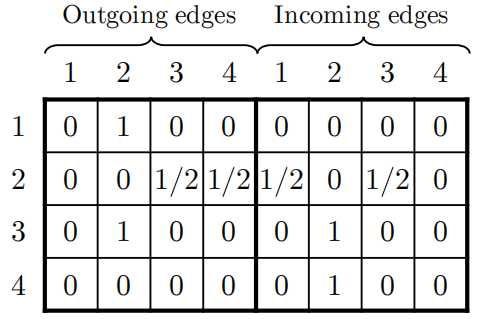
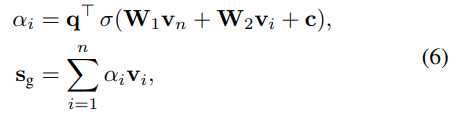
 ,sh∈Rd*1,v∈Rd*1,
,sh∈Rd*1,v∈Rd*1, 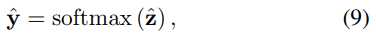 其中z?∈Rm表示所有候选项目的推荐分数,y?∈Rm表示节点s似乎是会话s中的下一次单击的概率。
其中z?∈Rm表示所有候选项目的推荐分数,y?∈Rm表示节点s似乎是会话s中的下一次单击的概率。