一个类负责一项职责
一个软件实体如类、模块和函数应该对扩展开放,对修改关闭
继承与派生的规则(子类可替换父类)
高层模块不应该依赖低层模块,二者都应该依赖其抽象;抽象不应该依赖细节;细节应该依赖抽象。即针对接口编程,不要针对实现编程
建立单一接口,不要建立庞大臃肿的接口,尽量细化接口,接口中的方法尽量少
尽量使用组合和聚合少使用继承的关系来达到复用的原则
高内聚,低耦合(high cohesion low coupling)
确保一个类只有一个实例, 并提供全局访问点
所有的操作都是对其进行更改
在内存中只有一个实例,也就只有一个访问点
#encoding=utf8
import threading
import time
#这里使用方法__new__来实现单例模式
class Singleton(object):#抽象单例
def __new__(cls, *args, **kw):
if not hasattr(cls, ‘_instance‘):
orig = super(Singleton, cls)
cls._instance = orig.__new__(cls, *args, **kw)
return cls._instance
#总线
class Bus(Singleton):
lock = threading.RLock()
def sendData(self,data):
self.lock.acquire()
time.sleep(3)
print "Sending Signal Data...",data
self.lock.release()
#线程对象,为更加说明单例的含义,这里将Bus对象实例化写在了run里
class VisitEntity(threading.Thread):
my_bus=""
name=""
def getName(self):
return self.name
def setName(self, name):
self.name=name
def run(self):
self.my_bus=Bus()
self.my_bus.sendData(self.name)
if __name__=="__main__":
for i in range(3):
print "Entity %d begin to run..."%i
my_entity=VisitEntity()
my_entity.setName("Entity_"+str(i))
my_entity.start()
单例模式的优点:
1、由于单例模式要求在全局内只有一个实例,因而可以节省比较多的内存空间;
2、全局只有一个接入点,可以更好地进行数据同步控制,避免多重占用;
3、单例可长驻内存,减少系统开销。
单例模式的应用举例:
1、生成全局惟一的序列号;
2、访问全局复用的惟一资源,如磁盘、总线等;
3、单个对象占用的资源过多,如数据库等;
4、系统全局统一管理,如Windows下的Task Manager;
5、网站计数器。
定义了一个创建对象的接口, 但由子类决定要实例化的类是哪一个
工厂方法让类把实例化推迟到子类
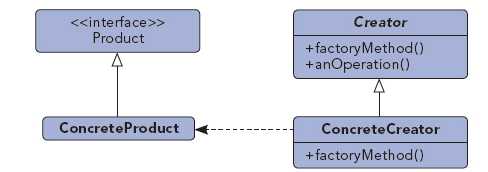
class Burger():
name=""
price=0.0
def getPrice(self):
return self.price
def setPrice(self,price):
self.price=price
def getName(self):
return self.name
class cheeseBurger(Burger):
def __init__(self):
self.name="cheese burger"
self.price=10.0
class spicyChickenBurger(Burger):
def __init__(self):
self.name="spicy chicken burger"
self.price=15.0
定义Burger类,包含了cheeseBurger和spicyChickenBurger(其继承了Burger类,父类一般不会实例化)
class Snack():
name = ""
price = 0.0
type = "SNACK"
def getPrice(self):
return self.price
def setPrice(self, price):
self.price = price
def getName(self):
return self.name
class chips(Snack):
def __init__(self):
self.name = "chips"
self.price = 6.0
class chickenWings(Snack):
def __init__(self):
self.name = "chicken wings"
self.price = 12.0
定义Snack类,包括chips和chickenWing(其继承了snack类,父类一般不会实例化)
class Beverage():
name = ""
price = 0.0
type = "BEVERAGE"
def getPrice(self):
return self.price
def setPrice(self, price):
self.price = price
def getName(self):
return self.name
class coke(Beverage):
def __init__(self):
self.name = "coke"
self.price = 4.0
class milk(Beverage):
def __init__(self):
self.name = "milk"
self.price = 5.0
定义Beverage类,包含coke和milk(其继承了snack类,父类一般不会实例化)
class foodFactory():
type=""
def createFood(self,foodClass):
print self.type," factory produce a instance."
foodIns=foodClass()
return foodIns
class burgerFactory(foodFactory):
def __init__(self):
self.type="BURGER"
class snackFactory(foodFactory):
def __init__(self):
self.type="SNACK"
class beverageFactory(foodFactory):
def __init__(self):
self.type="BEVERAGE"
定义foodFactory类,包含burgerFactory类,snackFactory类,beverageFactory类(继承了foodFactory类,父类一般不会实例化)
if __name__=="__main__":
burger_factory=burgerFactory()
snack_factorry=snackFactory()
beverage_factory=beverageFactory()
cheese_burger=burger_factory.createFood(cheeseBurger)
print cheese_burger.getName(),cheese_burger.getPrice()
chicken_wings=snack_factorry.createFood(chickenWings)
print chicken_wings.getName(),chicken_wings.getPrice()
coke_drink=beverage_factory.createFood(coke)
print coke_drink.getName(),coke_drink.getPrice()
首先实例化三个工厂类,再使用createFood方法(该方法在父类中定义,输入参数为具体的食物类别,也就是类名)
(首先实例化工厂,再调用工厂中的方法对产品进行实例化)
class simpleFoodFactory():
@classmethod
def createFood(cls,foodClass):
print "Simple factory produce a instance."
foodIns = foodClass()
return foodIns
使用@classmethod可以不用实例化,直接表明其是一个类方法
由如下方式调用
spicy_chicken_burger=simpleFoodFactory.createFood(spicyChickenBurger)
此处的类没有进行实例化,而是开箱即用
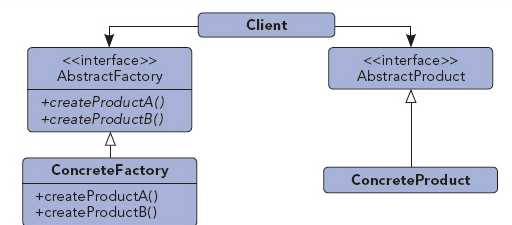
工厂模式、抽象工厂模式的优点:
1、工厂模式巨有非常好的封装性,代码结构清晰;在抽象工厂模式中,其结构还可以随着需要进行更深或者更浅的抽象层级调整,非常灵活;
2、屏蔽产品类,使产品的被使用业务场景和产品的功能细节可以分而开发进行,是比较典型的解耦框架。
工厂模式、抽象工厂模式的使用场景:
1、当系统实例要求比较灵活和可扩展时,可以考虑工厂模式或者抽象工厂模式实现。比如,
在通信系统中,高层通信协议会很多样化,同时,上层协议依赖于下层协议,那么就可以对应建立对应层级的抽象工厂,根据不同的“产品需求”去生产定制的实例
将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示
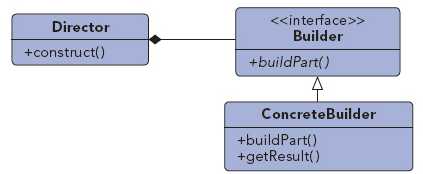
class order():
burger=""
snack=""
beverage=""
def __init__(self,orderBuilder):
self.burger=orderBuilder.bBurger
self.snack=orderBuilder.bSnack
self.beverage=orderBuilder.bBeverage
def show(self):
print "Burger:%s"%self.burger.getName()
print "Snack:%s"%self.snack.getName()
print "Beverage:%s"%self.beverage.getName()
所有的食品定义类和之前一致
只是此处不再采用工厂类,而是从订单的角度来进行,创建一个订单类
class orderBuilder():
bBurger=""
bSnack=""
bBeverage=""
def addBurger(self,xBurger):
self.bBurger=xBurger
def addSnack(self,xSnack):
self.bSnack=xSnack
def addBeverage(self,xBeverage):
self.bBeverage=xBeverage
def build(self):
return order(self)
同时要为订单创建一个建造者,也就是订单创建类(其方法内包含了属性的定义)
if __name__=="__main__":
order_builder=orderBuilder()
order_builder.addBurger(spicyChickenBurger())
order_builder.addSnack(chips())
order_builder.addBeverage(milk())
order_1=order_builder.build()
order_1.show()
首先实例化建造者,也就是订单创建类
其次调用建造者的方法,将类的实例(为所有食品的实例)作为参数传入,最后使用方法来返回订单的实例
实际上只有建造者进行显式的实例化,其他实例化都是通过建造者的方法实现的
在建造者模式中,还可以加一个Director类,用以安排已有模块的构造步骤。对于在建造者中有比较严格的顺序要求时,该类会有比较大的用处
class orderDirector():
order_builder=""
def __init__(self,order_builder):
self.order_builder=order_builder
def createOrder(self,burger,snack,beverage):
self.order_builder.addBurger(burger)
self.order_builder.addSnack(snack)
self.order_builder.addBeverage(beverage)
return self.order_builder.build()
优点:
1、封装性好,用户可以不知道对象的内部构造和细节,就可以直接建造对象;
2、系统扩展容易;
3、建造者模式易于使用,非常灵活。在构造性的场景中很容易实现“流水线”;
4、便于控制细节。
使用场景:
1、目标对象由组件构成的场景中,很适合建造者模式。例如,在一款赛车游戏中,车辆生成时,需要根据级别、环境等,选择轮胎、悬挂、骨架等部件,构造一辆“赛车”;
2、在具体的场景中,对象内部接口需要根据不同的参数而调用顺序有所不同时,可以使用建造者模式。例如:一个植物养殖器系统,对于某些不同的植物,浇水、施加肥料的顺序要求可能会不同,因而可以在Director中维护一个类似于队列的结构,在实例化时作为参数代入到具体建造者中
用原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象
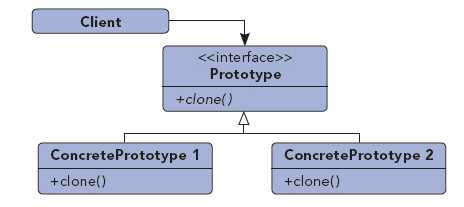
from copy import copy, deepcopy
class simpleLayer:
background=[0,0,0,0]
content="blank"
def getContent(self):
return self.content
def getBackgroud(self):
return self.background
def paint(self,painting):
self.content=painting
def setParent(self,p):
self.background[3]=p
def fillBackground(self,back):
self.background=back
def clone(self):
return copy(self)
def deep_clone(self):
return deepcopy(self)
if __name__=="__main__":
dog_layer=simpleLayer()
dog_layer.paint("Dog")
dog_layer.fillBackground([0,0,255,0])
print "Background:",dog_layer.getBackgroud()
print "Painting:",dog_layer.getContent()
another_dog_layer=dog_layer.clone()
print "Background:", another_dog_layer.getBackgroud()
print "Painting:", another_dog_layer.getContent()
与一般的类相比,其添加了clone和deep_clone两个新方法(使用了copy模块)
clone为浅复制,其会复制对象内容及内容的引用或者子对象的引用,但不会拷贝引用的内容和子对象本身
(也就是浅复制没有复制完全,某些元素还是使用的引用,例如引用的内容及子对象本身,而没有去使用副本)
deep_clone为深复制,不仅复制对象及内容的引用,也会复制引用的内容
if __name__=="__main__":
dog_layer=simpleLayer()
dog_layer.paint("Dog")
dog_layer.fillBackground([0,0,255,0])
print "Original Background:",dog_layer.getBackgroud()
print "Original Painting:",dog_layer.getContent()
another_dog_layer=dog_layer.clone()
another_dog_layer.setParent(128)
another_dog_layer.paint("Puppy")
print "Original Background:", dog_layer.getBackgroud()
print "Original Painting:", dog_layer.getContent()
print "Copy Background:", another_dog_layer.getBackgroud()
print "Copy Painting:", another_dog_layer.getContent()
此处使用了浅复制,输出如下
Original Background: [0, 0, 255, 0]
Original Painting: Dog
Original Background: [0, 0, 255, 128]
Original Painting: Dog
Copy Background: [0, 0, 255, 128]
Copy Painting: Puppy
其对浅拷贝后的对象设置rgba的第四个值以及paint后的参数
可以看出拷贝原对象中rgba的第四个值发生了变化,而paint后的参数并未改变
rgba为引用background这个列表,使用索引进行调用,因为浅复制不可能去更改引用的这个background列表(有些更改是通过更改外部引用的元素来进行的)
而paint为直接设定参数,没有外部引用
如果使用深复制,则输出如下
Original Background: [0, 0, 255, 0]
Original Painting: Dog
Original Background: [0, 0, 255, 0]
Original Painting: Dog
Copy Background: [0, 0, 255, 128]
Copy Painting: Puppy
拷贝的原元素完全没有变化,因为深复制会同时拷贝外部引用的元素
优点:
1、性能极佳,直接拷贝比在内存里直接新建实例节省不少的资源;
2、简化对象创建,同时避免了构造函数的约束,不受构造函数的限制直接复制对象,是优点,也有隐患,这一点还是需要多留意一些。
使用场景:
1、对象在修改过后,需要复制多份的场景。如本例和其它一些涉及到复制、粘贴的场景;
2、需要优化资源的情况。如,需要在内存中创建非常多的实例,可以通过原型模式来减少资源消耗。此时,原型模式与工厂模式配合起来,不管在逻辑上还是结构上,都会达到不错的效果;
3、某些重复性的复杂工作不需要多次进行。如对于一个设备的访问权限,多个对象不用各申请一遍权限,由一个设备申请后,通过原型模式将权限交给可信赖的对象,既可以提升效率,又可以节约资源。
原文:https://www.cnblogs.com/lixin2011/p/13937191.html