本文主要通过分析孟宁老师的menu小程序,介绍一些在编写较大的项目时,常用的软件工程思想。通过这些思想可以降低代码的耦合度,提高代码的内聚度,使我们的代码更易管理、维护和迭代。
本文中使用的工具为VSCode、MinGW-W64,系统环境为Windows10。
menu程序链接:menu代码打包下载、Github链接。
二、配置VSCode中的C/C++编译环境
1、在VSCode商店中下载C/C++官方插件。

2、下载安装C/C++编译器:MinGW。
点击链接前往下载地址:https://sourceforge.net/projects/mingw-w64/files/
往下找到如图所示的x86_64-posix-seh,单击进入下载页面进行下载。

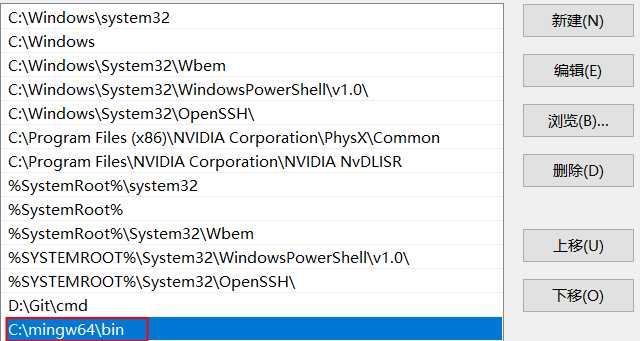
下载完成后得到一个压缩包,将其解压缩到一个不含中文路径名的目录下。然后找到文件中的bin文件夹所在目录,如“C:\mingw64\bin”,复制该路径名。
3、配置系统环境变量PATH。
右键单击“此电脑”,点击“属性”->“高级系统设置”->“环境变量”进入环境变量页面。在下方的系统变量列表中找到“Path”变量并双击进入编辑界面。单击“新建”并将刚刚复制的路径名粘贴上后点击确定,完成环境配置。
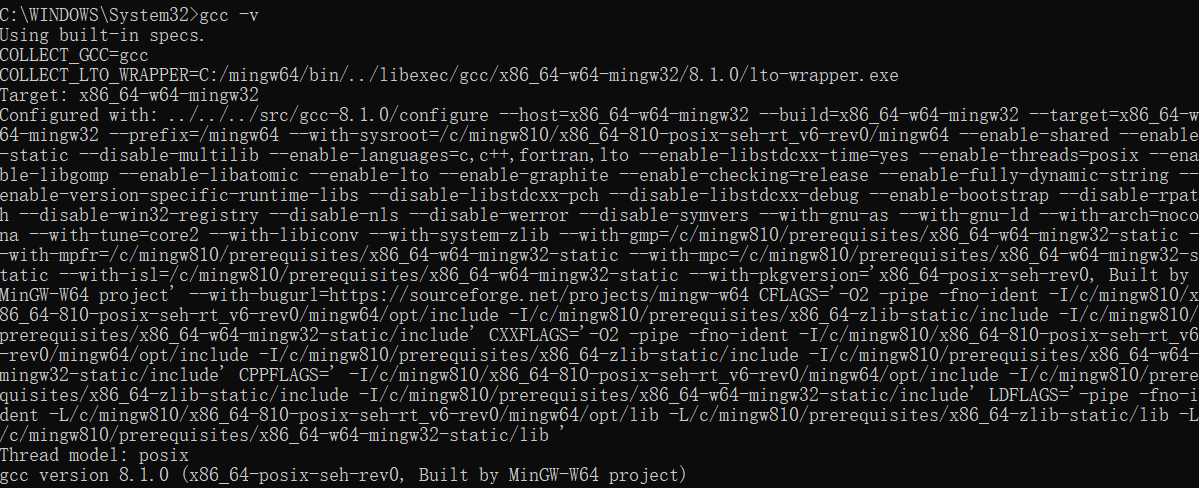
在开始菜单上单击右键,选择“命令提示符”进入命令窗口。输入“gcc -v”查看是否安装成功,若成功显示“gcc version”则表示配置成功。
4、配置launch.json和task.json文件
在VSCode中打开下载的menu代码所在文件夹,然后选择test.c文件,在VSCode左侧点击依次点击“运行和调试”->“C++(GDB/LLDB)”->“gcc.exe-生成和调试活动文件”。此时menu目录下生成了.vscode文件夹,该文件夹中生成了所需的launch.json和task.json。
把launch.json中的“preLaunchTask”的内容修改为“gcc”。

把task.json中的“label”的内容修改为“gcc”。

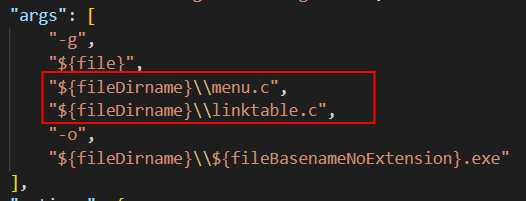
由于我们将menu的功能分离了出来,形成了menu.c和linktable.c以及test.c。主入口函数main在test.c中,因此需要在task.json中的args参数栏增加menu.c和linktable.c的编译信息,增加的位置如图:
然后运行test.c,此时在终端中即可看到成功运行的界面。
在这一节中,我将追踪menu程序的成长轨迹,并分析其中使用到的软件工程思想。menu程序将从一个简单地“hello world”程序开始,逐步成长为一个菜单小程序。
以下是menu在各个阶段的文件:
思想1、先使用伪代码描述程序逻辑,再进行具体实现。
设计通常为程序提供了一个框架,程序员需要用自己的专业知识和创造性来编写代码实现设计。在从设计到编码的过程中加入伪代码阶段要好于直接将设计翻译成实现代码。因为伪代码不需要考虑异常处理等一些编程细节,最大限度地保留了设计上的框架结构,使得设计上的逻辑结构在伪代码上体现出来。从伪代码到实现代码的过程就是反复重构的过程,这样
在menu.c中,先将命令程序的逻辑用伪代码表示出来。伪代码如下:
int main() { while(true)//持续接收用户的输入 { scanf(cmd);//获取用户输入的命令 int ret = strcmp(cmd, "help");//如果输入的是help命令,执行其对应操作 if(ret == 0) { dosth(); } int ret = strcmp(cmd, "others");//如果是其他命令,执行其操作 if(ret == 0) { dosth(); } } }
接下来用具体的代码实现:
//通过控制结构简化代码 int main() { char cmd[128]; while(1)//循环结构 { scanf("%s", cmd); if(strcmp(cmd, "help") == 0)//条件分支结构 { printf("This is help cmd!\n"); } else if(strcmp(cmd, "quit") == 0) { exit(0); } else { printf("Wrong cmd!\n"); } } }
通过这样的方式,避免了顺序翻译转换所造成的结构性损失。我们的代码结构也会更好一些。我们要有意识地用设计上的逻辑结构给代码提供一个编写框架,避免代码的无序生长,从而破坏设计上的逻辑结构。
思想2、通过控制结构和数据结构简化代码
通过观察不难发现,每条命令的构成元素都是一样的,包括命令名以及命令对应的操作。由此,我们可以使用一种统一的格式来描述每一条命令,这就形成了一种简单的数据结构。命令的结构如下:
//通过数据结构简化代码 typedef struct DataNode { char* cmd; char* desc; int (*handler)();//使用函数指针 struct DataNode *next; } tDataNode;
在这个结构中每个命令存储在一个DataNode节点中,这个节点包含了命令的名字cmd,命令的描述信息desc,命令相应的操作handler和下一个命令的位置next。如此我们就可以统一各种命令的格式进行存储。所谓磨刀不误砍柴工,一个合适的数据结构可以有效节省我们之后所费的精力。
使用数据结构后,menu主函数如下:
static tDataNode head[] = { {"help", "this is help cmd!", Help,&head[1]}, {"version", "menu program v1.0", NULL, &head[2]}, {"quit", "Quit from menu", Quit, NULL} }; int main() { /* cmd line begins */ while(1) { char cmd[CMD_MAX_LEN]; printf("Input a cmd number > "); scanf("%s", cmd); tDataNode *p = head; while(p != NULL)//逐个查找命令 { if(strcmp(p->cmd, cmd) == 0) { printf("%s - %s\n", p->cmd, p->desc); if(p->handler != NULL) { p->handler(); } break; } p = p->next; } if(p == NULL) { printf("This is a wrong cmd!\n "); } } }
可以看到使用数据结构进行抽象后,我们的命令选择相较于之前的分支选择结构更加简洁,分支选择语句的数量不会再随着命令种类的增加而一直增加下去了。
不过新的问题也出现了,主函数中的循环体结构现在看起来也更加复杂了,while循环结构中嵌套了while,嵌套的while中还有分支选择。为了使主函数看起来更加简洁,我们可以将这一部分代码根据其功能专门独立到一个或多个函数中去,而主函数只需要调用这些函数就可以了。改进后的主函数如下:
int main() { /* cmd line begins */ while(1) { char cmd[CMD_MAX_LEN]; printf("Input a cmd number > "); scanf("%s", cmd); tDataNode *p = FindCmd(head, cmd);//查找命令的函数 if( p == NULL)//用户输入的命令不存在 { printf("This is a wrong cmd!\n "); continue; } //用户输入的命令存在 printf("%s - %s\n", p->cmd, p->desc); if(p->handler != NULL) { p->handler(); } } }
将功能实现过程的代码从主函数中分离出来后,不仅使主函数体更加简洁清晰,也可以使该功能可以在其他地方被方便地调用,因此在编写程序的时候要多多使用函数简化代码。
思想3、模块化
在上面的思想2中我们提到通过使用数据结构和函数来简化主函数中的代码,然而随着功能的增加,主函数所在的文件中存在的函数与数据结构也势必会增加,这样就会使整个menu.c文件包含的代码越来越多。在如此多的代码中想要快速分清哪个数据结构和哪个函数是相关的,哪些又是无关的将会非常难。因此,与思想2中将功能的实现过程从主函数中分离出来成为函数的思想相近,我们可以把数据结构以及其相关的函数单独从主函数所在的.c文件中分离出来成为单独的文件。这就叫做“模块化”。
模块化(Modularity)是指,在软件系统设计时保持系统内各部分相对独立,以便每一个部分可以被独立地进行设计和开发。最终追求是每一个软件模块都将只有一个单一的功能目标,并相对独立于其他软件模块。一般通过“耦合度”和“内聚度”来衡量模块化的程度。
耦合度是指软件模块之间的依赖程度,一般可以分为紧密耦合(Tightly Coupled)、松散耦合(Loosely Coupled)和无耦合(Uncoupled)。一般在软件设计中我们追求松散耦合。
内聚度是指一个软件模块内部各种元素之间互相依赖的紧密程度。理想的内聚是功能内聚,也就是一个软件模块只做一件事,只完成一个主要功能点或者一个软件特性(Feather)。
在menu程序中,我们可以将命令列表的结构以及对命令列表的操作从菜单程序中分离出来,形成linklist.h和linklist.c。
在linklist.h中,声明命令列表的结构以及对其进行操作的函数:
/* data struct and its operations */ //将存储命令的数据结构及其对应函数分离到linklist模块中 typedef struct DataNode { char* cmd;//命令名称 char* desc;//命令描述 int (*handler)();//实现该命令的函数的指针 struct DataNode *next;//下一条命令所在节点的指针 } tDataNode; /* find a cmd in the linklist and return the datanode pointer */ tDataNode* FindCmd(tDataNode * head, char * cmd); /* show all cmd in listlist */ int ShowAllCmd(tDataNode * head);
然后在linklist.c中,实现linklist.h中声明的函数(为节省篇幅在此不列举其实现代码)。
这样,命令列表的结构和查找操作就被分离出去了,实现了与主程序的解耦。
思想4、可重用接口(lab4)
对于前文的命令存储结构,我们可以进一步将其可以复用的部分抽象出来,形成一个可复用的链表结构。
/* * LinkTable Node Type */ typedef struct LinkTableNode { struct LinkTableNode * pNext; }tLinkTableNode; /* * LinkTable Type */ typedef struct LinkTable { tLinkTableNode *pHead;//链表头指针 tLinkTableNode *pTail;//链表尾指针 int SumOfNode;//链表长度 pthread_mutex_t mutex;//线程锁 }tLinkTable; /* * Create a LinkTable */ tLinkTable * CreateLinkTable(); /* * Delete a LinkTable */ int DeleteLinkTable(tLinkTable *pLinkTable); /* * Add a LinkTableNode to LinkTable */ int AddLinkTableNode(tLinkTable *pLinkTable,tLinkTableNode * pNode); /* * Delete a LinkTableNode from LinkTable */ int DelLinkTableNode(tLinkTable *pLinkTable,tLinkTableNode * pNode); /* * get LinkTableHead */ tLinkTableNode * GetLinkTableHead(tLinkTable *pLinkTable); /* * get next LinkTableNode */ tLinkTableNode * GetNextLinkTableNode(tLinkTable *pLinkTable,tLinkTableNode * pNode);
在这一部分我们定义了一个通用的链表结构,并定义了对链表进行操作的一些函数,包括对链表的创建、删除、增加节点、删除节点等函数,这些函数就是我们定义的链表的“接口”。我们的命令列表结构tDataNode就可以在基础的链表节点tLinkTableNode的内容上增加与命令相关的信息,由于其具有底层链表接口需要的信息,所以可以通过调用底层链表的这些公共接口,实现对命令节点tDataNode的增加和删除这些基本操作,而不需要单独对命令节点设计增删操作。需要注意的是,由于我们的存储命令的结构名为tDataNode,而这些结构的操作对象是tLinkTableNode,我们在调用接口时需要将tDataNode*强制转换为tLinkTableNode*。由于底层链表操作时只需要使用其自身必须的基础信息,而不知道命令节点的其他信息,因此这就实现了向底层链表操作隐藏了高层业务层的具体信息,保护了业务层的信息不被泄露给底层,实现了业务对可重用接口的解耦。
思想5、使用callback
在对链表进行查找时,由于基础的链表结构无法知道上层查找该节点时具体进行的操作,导致查找操作需要在每个不同的业务中单独实现,造成一些不必要的重复代码的出现。例如对于命令列表的查找函数FindCmd:
/* find a cmd in the linklist and return the datanode pointer */ tDataNode* FindCmd(tLinkTable * head, char * cmd) { tDataNode * pNode = (tDataNode*)GetLinkTableHead(head); while(pNode != NULL) { if(strcmp(pNode->cmd, cmd) == 0) { return pNode; } pNode = (tDataNode*)GetNextLinkTableNode(head,(tLinkTableNode *)pNode); } return NULL; }
为了底层链表能够向各种在此底层结构上发展的结构可以调用公共的查找接口并进行其需要的操作,可以使用函数作为接口的参数,这个函数就是callback函数。以下是改进后链表的公共查找接口:
/* * Search a LinkTableNode from LinkTable * int Conditon(tLinkTableNode * pNode); */ //公用的查找接口 tLinkTableNode * SearchLinkTableNode(tLinkTable *pLinkTable, int Conditon(tLinkTableNode * pNode)) { if(pLinkTable == NULL || Conditon == NULL) { return NULL; } tLinkTableNode * pNode = pLinkTable->pHead; while(pNode != pLinkTable->pTail) { if(Conditon(pNode) == SUCCESS) { return pNode; } pNode = pNode->pNext; } return NULL; }
其中的 int Conditon(tLinkTableNode * pNode)参数即为callback函数。对于命令列表,其对应的查找时的callback函数如下:
//查找命令列表时对应的回调函数 int SearchCondition(tLinkTableNode * pLinkTableNode) { tDataNode * pNode = (tDataNode *)pLinkTableNode; if(strcmp(pNode->cmd, cmd) == 0) { return SUCCESS; } return FAILURE; }
这样,在调用查找函数时只需要将对应的callback作为参数传递给公用接口就可以了。
/* find a cmd in the linklist and return the datanode pointer */ tDataNode* FindCmd(tLinkTable * head, char * cmd) { return (tDataNode*)SearchLinkTableNode(head,SearchCondition); }
通过这种方式,我们不需要因为不同的业务去修改底层查找接口的实现代码,只需要修改各个业务自己的callback执行逻辑就可以了。此外我们发现回调函数依赖于一个公共变量cmd,这导致了公共耦合,因此需要将其作为参数传递。因此需要给公共接口和callback添加一个参数:
//公共查找接口 tLinkTableNode * SearchLinkTableNode(tLinkTable *pLinkTable, int Conditon(tLinkTableNode * pNode, void * args), void * args); //查找命令菜单的callback int SearchCondition(tLinkTableNode * pLinkTableNode, void * args);
此处args的类型为void*类型,是为了向底层隐藏业务的数据类型,解耦的同时实现了业务对底层的信息隐藏。
思想6、线程与可重入函数
为了提高程序的运行效率,一个进程有时候由多个线程并行完成一个任务,这是会产生一些不想发生的错误,例如多个线程同时运行同一段代码对同一个数据进行操作,导致与单线程时得到的结果不同,这就涉及到线程安全的问题。线程安全问题都是由全局变量及静态变量引起的。若每个线程中对全局变量、静态变量只有读操作,而无写操作,一般来说,这个全局变量是线程安全的;若有多个线程同时执行读写操作,一般都需要考虑线程同步,否则就可能影响线程安全。
而可重入(reentrant)函数就是可以由多于一个任务并发使用,而不必担心数据错误的函数。
在我们的menu程序中,对于链表的创建删除以及节点的增加删除就涉及到线程安全问题。因此需要添加互斥锁,保证各线程对链表的修改是互斥的。以增加链表节点为例:
/* * Add a LinkTableNode to LinkTable */ int AddLinkTableNode(tLinkTable *pLinkTable,tLinkTableNode * pNode) { if(pLinkTable == NULL || pNode == NULL) { return FAILURE; } pNode->pNext = NULL; pthread_mutex_lock(&(pLinkTable->mutex));//对链表上锁,阻止其他线程访问 if(pLinkTable->pHead == NULL) { pLinkTable->pHead = pNode; } if(pLinkTable->pTail == NULL) { pLinkTable->pTail = pNode; } else { pLinkTable->pTail->pNext = pNode; pLinkTable->pTail = pNode; } pLinkTable->SumOfNode += 1 ; pthread_mutex_unlock(&(pLinkTable->mutex));//操作结束,解除对链表上的互斥锁 return SUCCESS; }
通过menu程序的成长过程,我学习到了许多十分使用的软件工程思想,这些思想对今后编写代码以及较大项目时有十分重要的作用,使我们的代码变得更具可读性,更易于维护。通过软件工程思想,降低各个模块的耦合度,提高内聚度,使模块的复用性更高。在软件设计时,设计更多可复用的接口而不是具体的代码来提高代码的复用性,使软件整体的框架更加合理。
原文:https://www.cnblogs.com/LiJin19971112/p/13930044.html