https://github.com/zq2599/blog_demos
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
本文是《Flink的sink实战》系列的第二篇,前文《Flink的sink实战之一:初探》对sink有了基本的了解,本章来体验将数据sink到kafka的操作;
本次实战的环境和版本如下:
请确保上述环境和服务已经就绪;
如果您不想写代码,整个系列的源码可在GitHub下载到,地址和链接信息如下表所示(https://github.com/zq2599/blog_demos):
| 名称 | 链接 | 备注 |
|---|---|---|
| 项目主页 | https://github.com/zq2599/blog_demos | 该项目在GitHub上的主页 |
| git仓库地址(https) | https://github.com/zq2599/blog_demos.git | 该项目源码的仓库地址,https协议 |
| git仓库地址(ssh) | git@github.com:zq2599/blog_demos.git | 该项目源码的仓库地址,ssh协议 |
这个git项目中有多个文件夹,本章的应用在flinksinkdemo文件夹下,如下图红框所示:

准备完毕,开始开发;
正式编码前,先去官网查看相关资料了解基本情况:

./kafka-topics.sh --create --bootstrap-server 127.0.0.1:9092 --replication-factor 1 --partitions 4 --topic test006
./kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic test006
mvn archetype:generate -DarchetypeGroupId=org.apache.flink -DarchetypeArtifactId=flink-quickstart-java -DarchetypeVersion=1.9.2
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.9.0</version>
</dependency>
先尝试发送字符串类型的消息:
package com.bolingcavalry.addsink;
import org.apache.flink.streaming.connectors.kafka.KafkaSerializationSchema;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.nio.charset.StandardCharsets;
public class ProducerStringSerializationSchema implements KafkaSerializationSchema<String> {
private String topic;
public ProducerStringSerializationSchema(String topic) {
super();
this.topic = topic;
}
@Override
public ProducerRecord<byte[], byte[]> serialize(String element, Long timestamp) {
return new ProducerRecord<byte[], byte[]>(topic, element.getBytes(StandardCharsets.UTF_8));
}
}
package com.bolingcavalry.addsink;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
public class KafkaStrSink {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//并行度为1
env.setParallelism(1);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "192.168.50.43:9092");
String topic = "test006";
FlinkKafkaProducer<String> producer = new FlinkKafkaProducer<>(topic,
new ProducerStringSerializationSchema(topic),
properties,
FlinkKafkaProducer.Semantic.EXACTLY_ONCE);
//创建一个List,里面有两个Tuple2元素
List<String> list = new ArrayList<>();
list.add("aaa");
list.add("bbb");
list.add("ccc");
list.add("ddd");
list.add("eee");
list.add("fff");
list.add("aaa");
//统计每个单词的数量
env.fromCollection(list)
.addSink(producer)
.setParallelism(4);
env.execute("sink demo : kafka str");
}
}
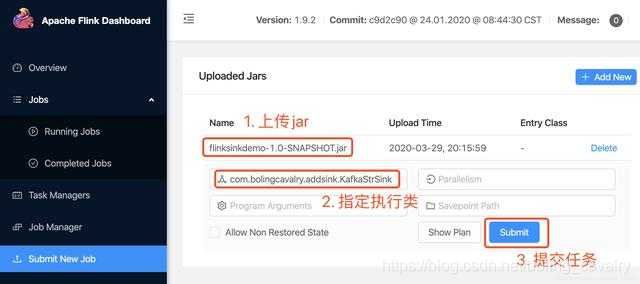
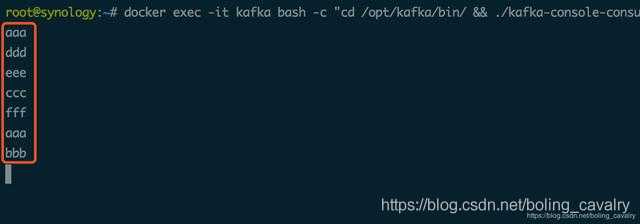
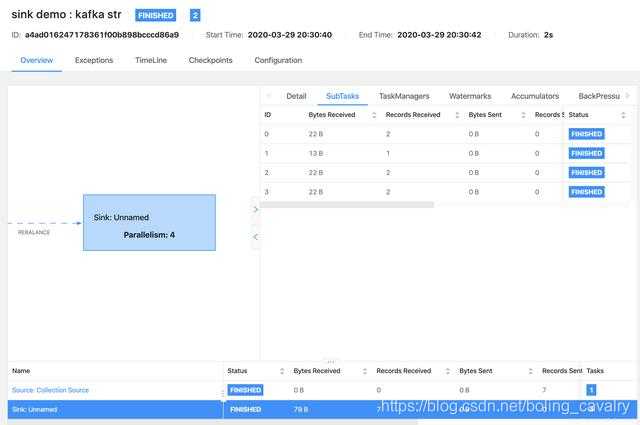
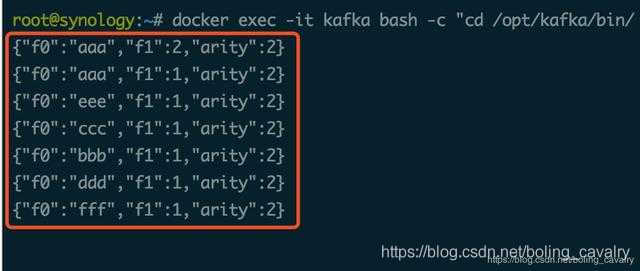
再来尝试如何发送对象类型的消息,这里的对象选择常用的Tuple2对象:
package com.bolingcavalry.addsink;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.core.JsonProcessingException;
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.flink.streaming.connectors.kafka.KafkaSerializationSchema;
import org.apache.kafka.clients.producer.ProducerRecord;
import javax.annotation.Nullable;
public class ObjSerializationSchema implements KafkaSerializationSchema<Tuple2<String, Integer>> {
private String topic;
private ObjectMapper mapper;
public ObjSerializationSchema(String topic) {
super();
this.topic = topic;
}
@Override
public ProducerRecord<byte[], byte[]> serialize(Tuple2<String, Integer> stringIntegerTuple2, @Nullable Long timestamp) {
byte[] b = null;
if (mapper == null) {
mapper = new ObjectMapper();
}
try {
b= mapper.writeValueAsBytes(stringIntegerTuple2);
} catch (JsonProcessingException e) {
// 注意,在生产环境这是个非常危险的操作,
// 过多的错误打印会严重影响系统性能,请根据生产环境情况做调整
e.printStackTrace();
}
return new ProducerRecord<byte[], byte[]>(topic, b);
}
}
package com.bolingcavalry.addsink;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
public class KafkaObjSink {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//并行度为1
env.setParallelism(1);
Properties properties = new Properties();
//kafka的broker地址
properties.setProperty("bootstrap.servers", "192.168.50.43:9092");
String topic = "test006";
FlinkKafkaProducer<Tuple2<String, Integer>> producer = new FlinkKafkaProducer<>(topic,
new ObjSerializationSchema(topic),
properties,
FlinkKafkaProducer.Semantic.EXACTLY_ONCE);
//创建一个List,里面有两个Tuple2元素
List<Tuple2<String, Integer>> list = new ArrayList<>();
list.add(new Tuple2("aaa", 1));
list.add(new Tuple2("bbb", 1));
list.add(new Tuple2("ccc", 1));
list.add(new Tuple2("ddd", 1));
list.add(new Tuple2("eee", 1));
list.add(new Tuple2("fff", 1));
list.add(new Tuple2("aaa", 1));
//统计每个单词的数量
env.fromCollection(list)
.keyBy(0)
.sum(1)
.addSink(producer)
.setParallelism(4);
env.execute("sink demo : kafka obj");
}
}
微信搜索「程序员欣宸」,我是欣宸,期待与您一同畅游Java世界...
https://github.com/zq2599/blog_demos
原文:https://www.cnblogs.com/bolingcavalry/p/13946789.html