.py文件
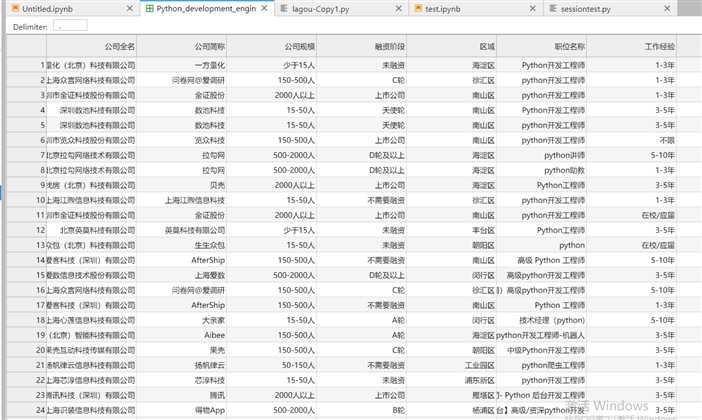
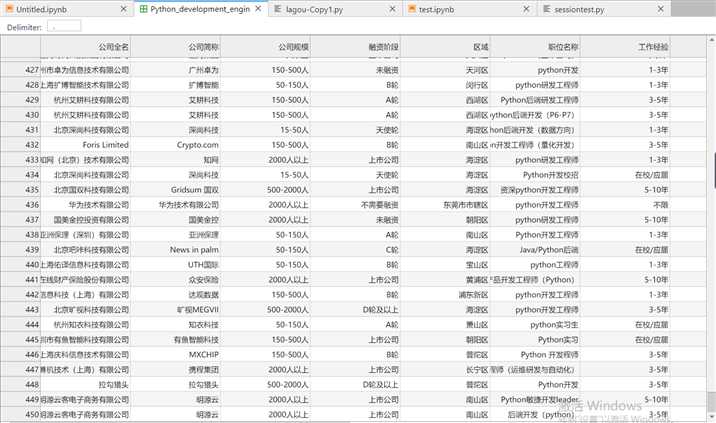
import requests import math import time import pandas as pd def get_json(url, num): """ 从指定的url中通过requests请求携带请求头和请求体获取网页中的信息, :return: """ url1 = ‘https://www.lagou.com/jobs/list_python%E5%BC%80%E5%8F%91%E5%B7%A5%E7%A8%8B%E5%B8%88?labelWords=&fromSearch=true&suginput=‘ headers = { ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36‘, ‘Host‘: ‘www.lagou.com‘, ‘Referer‘: ‘https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90?labelWords=&fromSearch=true&suginput=‘, ‘X-Anit-Forge-Code‘: ‘0‘, ‘X-Anit-Forge-Token‘: ‘None‘, ‘X-Requested-With‘: ‘XMLHttpRequest‘ } data = { ‘first‘: ‘true‘, ‘pn‘: num, ‘kd‘: ‘python工程师‘} s = requests.Session() print(‘建立session:‘, s, ‘\n\n‘) s.get(url=url1, headers=headers, timeout=3) cookie = s.cookies print(‘获取cookie:‘, cookie, ‘\n\n‘) res = requests.post(url, headers=headers, data=data, cookies=cookie, timeout=3) res.raise_for_status() res.encoding = ‘utf-8‘ page_data = res.json() print(‘请求响应结果:‘, page_data, ‘\n\n‘) return page_data def get_page_num(count): """ 计算要抓取的页数,通过在拉勾网输入关键字信息,可以发现最多显示30页信息,每页最多显示15个职位信息 :return: """ page_num = math.ceil(count / 15) if page_num > 30: return 30 else: return page_num def get_page_info(jobs_list): """ 获取职位 :param jobs_list: :return: """ page_info_list = [] for i in jobs_list: # 循环每一页所有职位信息 job_info = [] job_info.append(i[‘companyFullName‘]) job_info.append(i[‘companyShortName‘]) job_info.append(i[‘companySize‘]) job_info.append(i[‘financeStage‘]) job_info.append(i[‘district‘]) job_info.append(i[‘positionName‘]) job_info.append(i[‘workYear‘]) job_info.append(i[‘education‘]) job_info.append(i[‘salary‘]) job_info.append(i[‘positionAdvantage‘]) job_info.append(i[‘industryField‘]) job_info.append(i[‘firstType‘]) job_info.append(i[‘companyLabelList‘]) job_info.append(i[‘secondType‘]) job_info.append(i[‘city‘]) page_info_list.append(job_info) return page_info_list def main(): url = ‘ https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false‘ first_page = get_json(url, 1) total_page_count = first_page[‘content‘][‘positionResult‘][‘totalCount‘] num = get_page_num(total_page_count) total_info = [] time.sleep(10) print("python开发相关职位总数:{},总页数为:{}".format(total_page_count, num)) for num in range(1, num + 1): # 获取每一页的职位相关的信息 page_data = get_json(url, num) # 获取响应json jobs_list = page_data[‘content‘][‘positionResult‘][‘result‘] # 获取每页的所有python相关的职位信息 page_info = get_page_info(jobs_list) print("每一页python相关的职位信息:%s" % page_info, ‘\n\n‘) total_info += page_info print(‘已经爬取到第{}页,职位总数为{}‘.format(num, len(total_info))) time.sleep(20) # 将总数据转化为data frame再输出,然后在写入到csv各式的文件中 df = pd.DataFrame(data=total_info, columns=[‘公司全名‘, ‘公司简称‘, ‘公司规模‘, ‘融资阶段‘, ‘区域‘, ‘职位名称‘, ‘工作经验‘, ‘学历要求‘, ‘薪资‘, ‘职位福利‘, ‘经营范围‘, ‘职位类型‘, ‘公司福利‘, ‘第二职位类型‘, ‘城市‘]) df.to_csv(‘Python_development_engineer2.csv‘, index=False) print(‘python相关职位信息已保存‘) if __name__ == ‘__main__‘: main()
JupyterLab中通过 %load lagou-Copy1.py 和%run lagou-Copy1.py运行(注:这里df.to_csv(‘Python_development_engineer2.csv‘, index=False)的.csv文件它是自己会生成的不要预先创建)


原文:https://www.cnblogs.com/chenaiiu/p/13946540.html