一. 前言
本文通过分析孟宁老师的工程代码,从而理解软件工程。在实际的项目开发中,通过软件工程,我们可以让模块与模块之间的关系保持在一个”低耦合,高内聚“的状态。方便我们在大型项目上进行代码维护和迭代。
本文的编辑工具是Visual Code,编译链是MinGW-W64
二. 环境搭建
1.Visual Code
Visual Code到官方网站进行下载即可:https://code.visualstudio.com/
2.编译链
本文使用的是GCC在Windows下的版本MinGW-W64。下载地址:https://sourceforge.net/projects/mingw-w64/files/Toolchains%20targetting%20Win32/Personal%20Builds/mingw-builds/installer/mingw-w64-install.exe/download
指定安装目录,在线安装即可
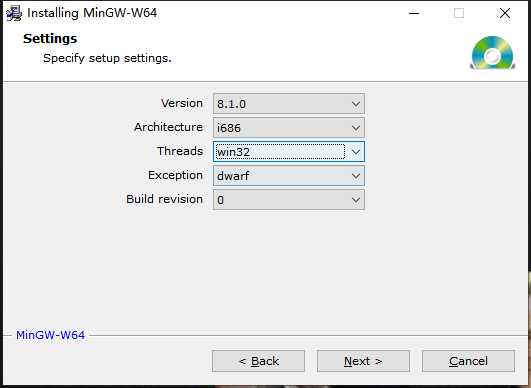
其中,Threads值为:Posix将启动C++11标准的std::thread,而Win32将关闭std::thread,创建新的线程只能通过Win32 API。
如果在线安装过慢的话,也可以选择离线安装。获取MinGW-W64的解压包之后,解压到某个地方即可。
3.系统环境变量
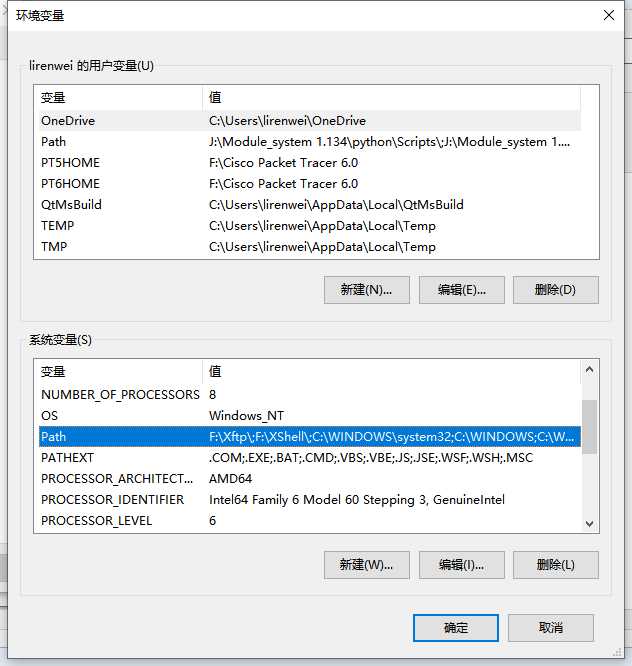
我们在安装好MinGW-W64之后,需要将其编译器(gcc,g++等),链接器(ld)等加入到系统环境变量中。
将bin目录加入即可,如图所示:
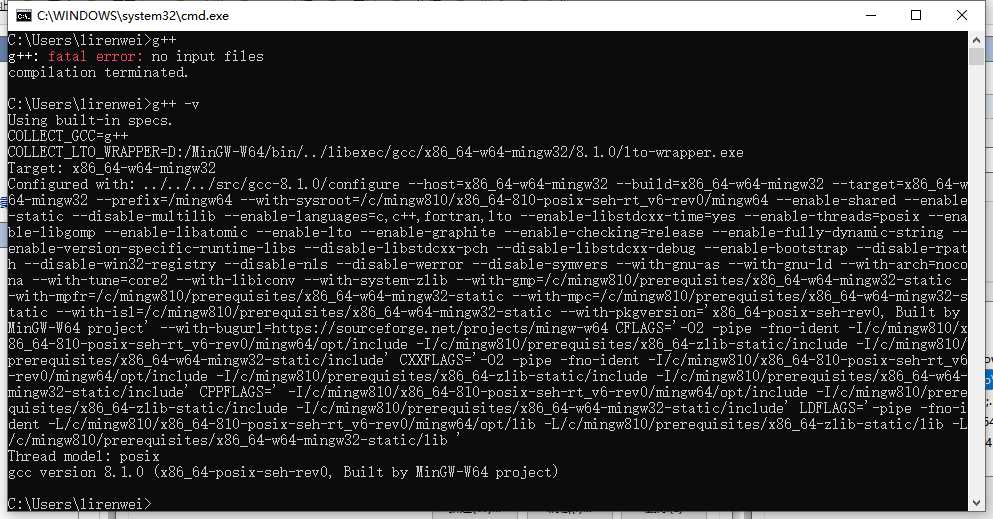
通过gcc,或g++命令来查看是否安装成功。如果出现如图所示的提示,则代表安装成功了。
4.项目配置
首先配置任务表(tasks.json),用于创建gcc的编译和链接等任务。如图所示
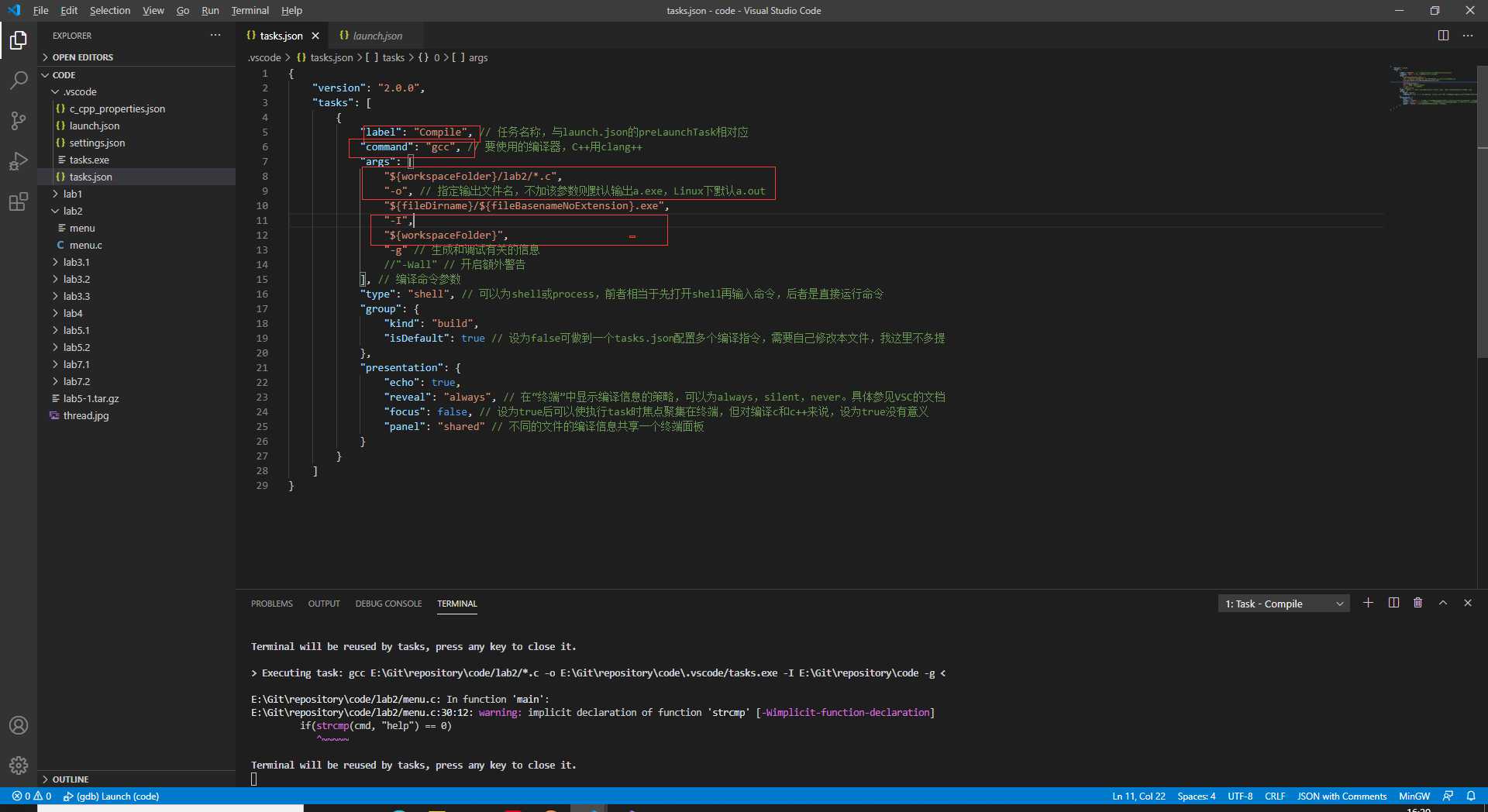
其中,label名指定任务名,要与接下来的launch表对应。编译命令我们填gcc就好。之后是gcc编译命令的参数列表:-o 是指定生成可执行文件的名称,-I 指定头文件查找目录
配置好tasks.json表之后,我们就可以配置launch.json表了。如图所示
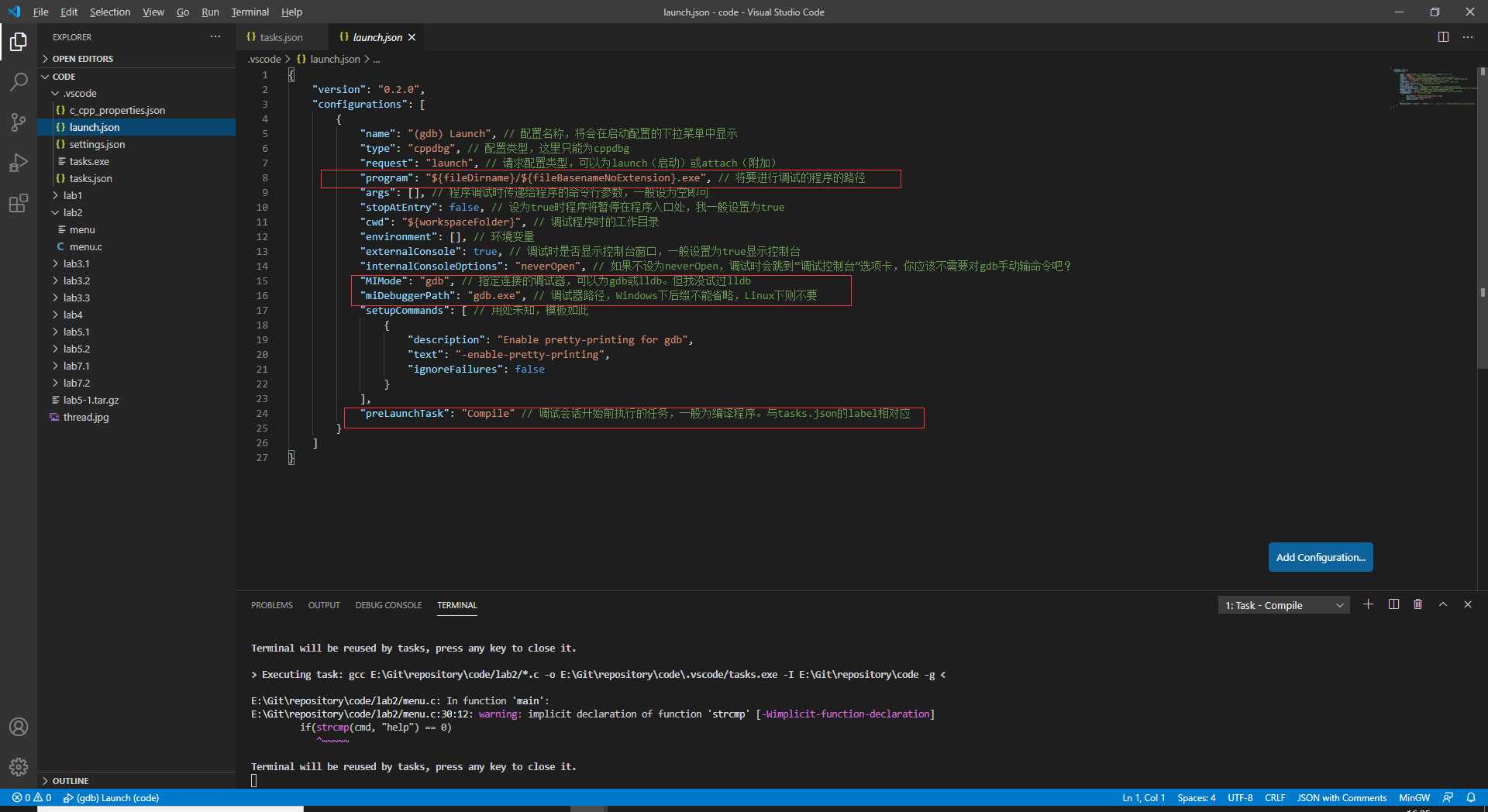
其中,program就是我们刚才指定的可执行文件的名称。preLaunchTask就是之前指定的tasks Label。而调试器我们选gdb就可以了。
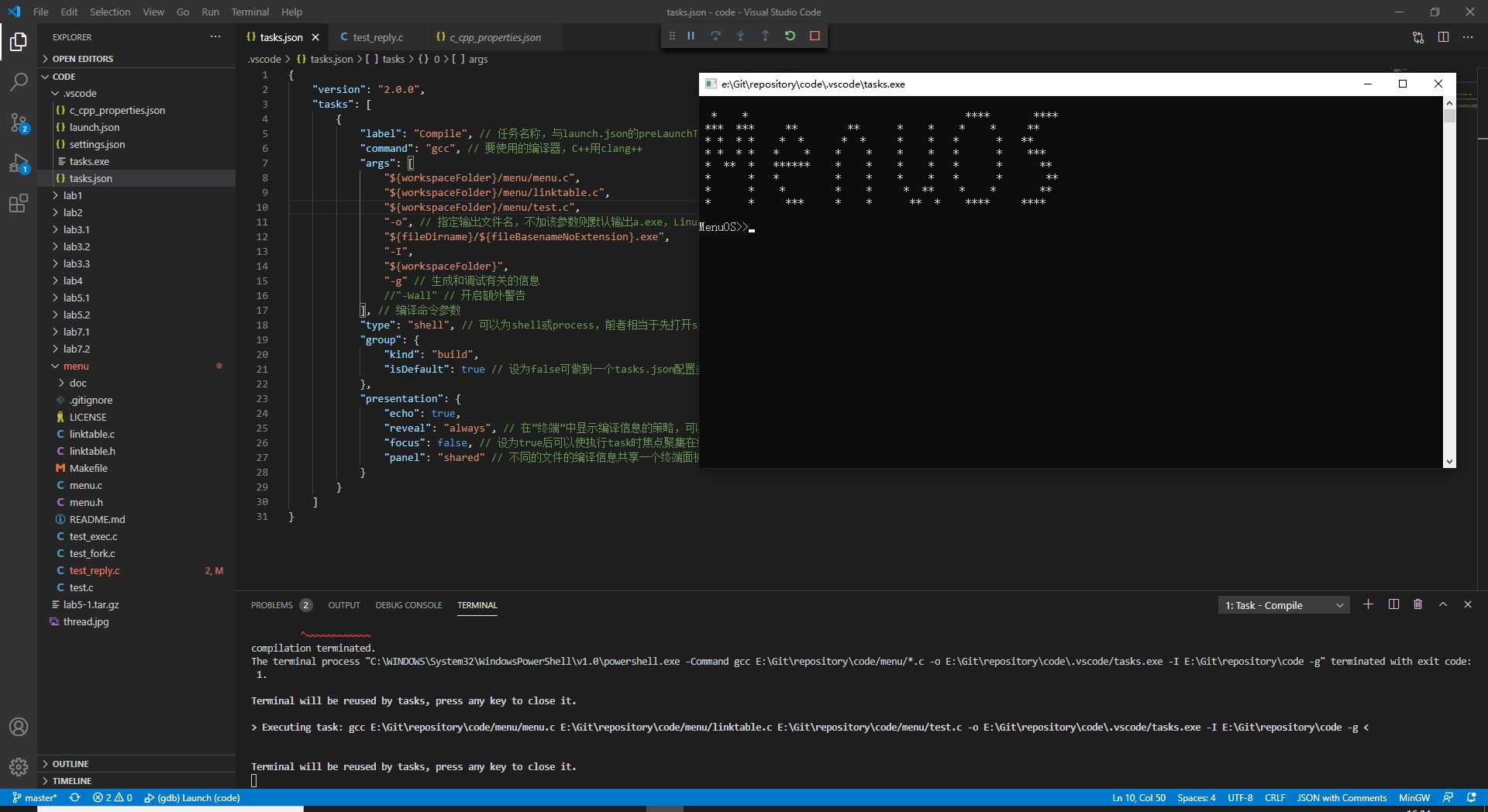
配置到此,就完成了。我们可以修改一下编译参数,让test.c运行起来。如图所示
三.代码中的软件工程
本文以孟宁老师的代码,进行一个软件工程化的设计。
首先判断一个项目的代码质量,我们用模块化程度来衡量。内聚程度越高,代码质量越好。耦合性越低,代码质量越好。反之,则说明代码还需要改进。
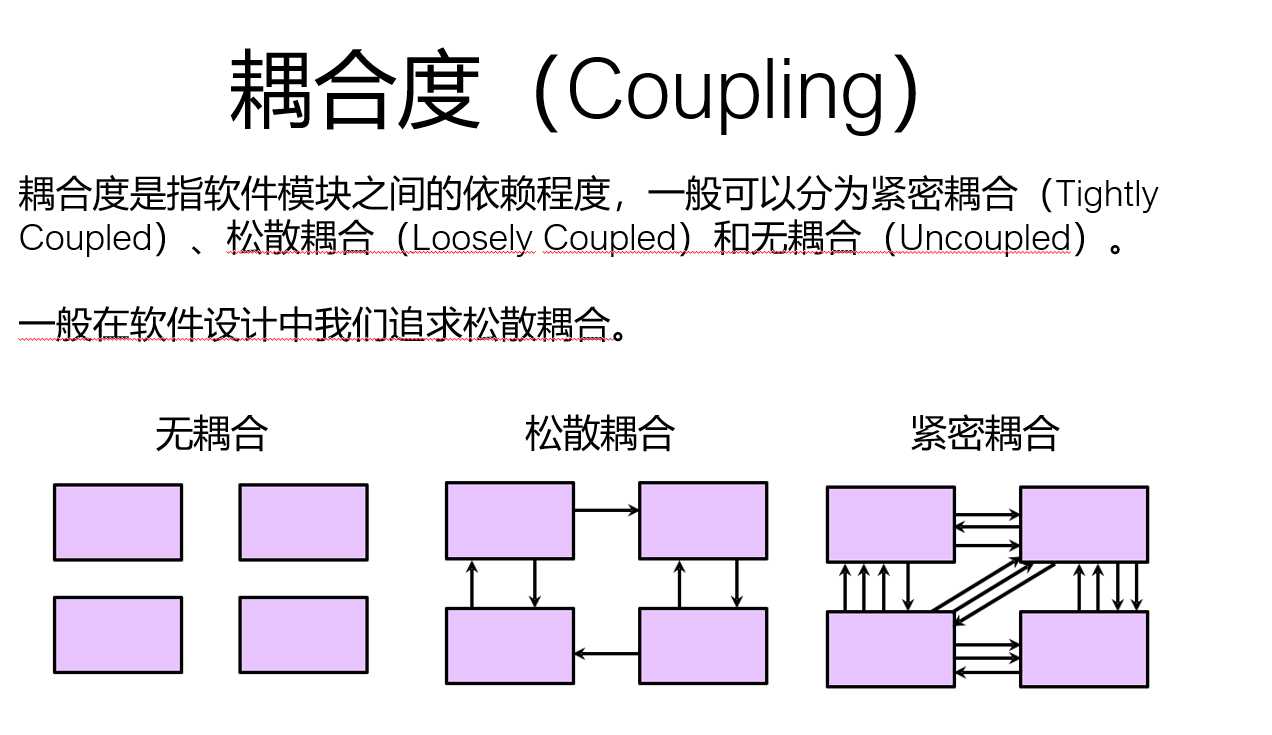
1.伪代码实现
设计通常为程序提供了一个框架,程序员需要用自己的专业知识和创造性来编写代码实现设计。在从设计到编码的过程中加入伪代码阶段要好于直接将设计翻译成实现代码。因为伪代码不需要考虑异常处理等一些编程细节,最大限度地保留了设计上的框架结构,使得设计上的逻辑结构在伪代码上体现出来。从伪代码到实现代码的过程就是反复重构的过程,这样就避免了顺序翻译转换所造成的结构损失。因此,先写伪代码的代码结构会更好一些。
伪代码实现的menu.c
int main()
{
while(true)
{
scanf(cmd);
int ret = strcmp(cmd, "help");
if(ret == 0)
{
dosth();
}
int ret = strcmp(cmd, "others");
if(ret == 0)
{
dosth();
}
}
}
代码实现menu.c
#include <stdio.h>
#include <stdlib.h>
int main()
{
char cmd[128];
while(1)
{
scanf("%s", cmd);
if(strcmp(cmd, "help") == 0)
{
printf("This is help cmd!\n");
}
else if(strcmp(cmd, "quit") == 0)
{
exit(0);
}
else
{
printf("Wrong cmd!\n");
}
}
}
2.代码简化
通过数据结构,根据不同的逻辑,配合相应的控制结构,可以大大简化程序结构。
我们可以看到,在menu.c中对每个命令的处理其实都是一样的。先输入,然后进行匹配,在执行相应的操作。因此,我们可以抽象出一种数据结构,简化代码,并且方便以后管理和复用。
typedef struct DataNode
{
tLinkTableNode * pNext;
char* cmd;
char* desc;
int (*handler)();
} tDataNode;
使用该数据结构后,menu.c的主程序变成了这样
main()
{
/* cmd line begins */
while(1)
{
char cmd[CMD_MAX_LEN];
printf("Input a cmd number > ");
scanf("%s", cmd);
tDataNode *p = FindCmd(head, cmd);
if( p == NULL)
{
printf("This is a wrong cmd!\n ");
continue;
}
printf("%s - %s\n", p->cmd, p->desc);
if(p->handler != NULL)
{
p->handler();
}
}
}
3.模块化
经过前文的简单修改,主函数已经很简洁了。但随着功能的增多,menu.c文件将会变得十分庞大。这对我们查找函数和结构是十分不方便的。于是,我们可以将同属一个模块的函数和数据结构从menu.c中抽离出来,进行模块化。
将其存储到linklist.h。这样以后我们修改或更新将十分方便
typedef struct DataNode { char* cmd; char* desc; int (*handler)(); struct DataNode *next; } tDataNode; /* find a cmd in the linklist and return the datanode pointer */ tDataNode* FindCmd(tDataNode * head, char * cmd); /* show all cmd in listlist */ int ShowAllCmd(tDataNode * head);
4.代码复用
经过前文的模块化,我们已经有了一个模块。但是这个模块是无法进行代码复用的,因为它跟业务高度相关。因此,我们还可以进行模块拆分,将该模块分成业务层和逻辑层。并且抽象逻辑层,让逻辑层与业务层实现”高内聚,内耦合“的特性。
从而实现逻辑层的代码复用。
/* * LinkTable Node Type */ typedef struct LinkTableNode { struct LinkTableNode * pNext; }tLinkTableNode; /* * LinkTable Type */ typedef struct LinkTable { tLinkTableNode *pHead; tLinkTableNode *pTail; int SumOfNode; pthread_mutex_t mutex; }tLinkTable; /* * Create a LinkTable */ tLinkTable * CreateLinkTable(); /* * Delete a LinkTable */ int DeleteLinkTable(tLinkTable *pLinkTable); /* * Add a LinkTableNode to LinkTable */ int AddLinkTableNode(tLinkTable *pLinkTable,tLinkTableNode * pNode); /* * Delete a LinkTableNode from LinkTable */ int DelLinkTableNode(tLinkTable *pLinkTable,tLinkTableNode * pNode); /* * Search a LinkTableNode from LinkTable * int Conditon(tLinkTableNode * pNode); */ tLinkTableNode * SearchLinkTableNode(tLinkTable *pLinkTable, int Conditon(tLinkTableNode * pNode)); /* * get LinkTableHead */ tLinkTableNode * GetLinkTableHead(tLinkTable *pLinkTable); /* * get next LinkTableNode */ tLinkTableNode * GetNextLinkTableNode(tLinkTable *pLinkTable,tLinkTableNode * pNode);
其中,像SearchLinkTableNode函数使用了callback方式,通过传递函数指针的形式进行解耦合 。这样Search函数就脱离了业务层,进一步降低了耦合性。
并且,将原来的数据结构中的业务数据,全部封装到了业务层。逻辑层专注于底层抽象逻辑的实现,从而提高了代码复用性。
typedef struct DataNode { tLinkTableNode * pNext; char* cmd; char* desc; int (*handler)(); } tDataNode; int SearchCondition(tLinkTableNode * pLinkTableNode) { tDataNode * pNode = (tDataNode *)pLinkTableNode; if(strcmp(pNode->cmd, cmd) == 0) { return SUCCESS; } return FAILURE; } /* find a cmd in the linklist and return the datanode pointer */ tDataNode* FindCmd(tLinkTable * head, char * cmd) { return (tDataNode*)SearchLinkTableNode(head,SearchCondition); } /* show all cmd in listlist */ int ShowAllCmd(tLinkTable * head) { tDataNode * pNode = (tDataNode*)GetLinkTableHead(head); while(pNode != NULL) { printf("%s - %s\n", pNode->cmd, pNode->desc); pNode = (tDataNode*)GetNextLinkTableNode(head,(tLinkTableNode *)pNode); } return 0; }
5.线程安全/可重入函数
为了提高程序的运行效率,一个进程有时候由多个线程并行完成一个任务,这是会产生一些不想发生的错误,如果多个线程同时对某个变量进行读写的时候。该变量的状态可能存在多种情况,这样就会引起程序执行的不一致性。线程安全问题都是由全局变量及静态变量引起的。若每个线程中对全局变量、静态变量只有读操作,而无写操作,一般来说,这个全局变量是线程安全的;若有多个线程同时执行读写操作,一般都需要考虑线程同步,否则就可能影响线程安全。
/* * Delete a LinkTableNode from LinkTable */ int DelLinkTableNode(tLinkTable *pLinkTable,tLinkTableNode * pNode) { if(pLinkTable == NULL || pNode == NULL) { return FAILURE; } pthread_mutex_lock(&(pLinkTable->mutex)); if(pLinkTable->pHead == pNode) { pLinkTable->pHead = pLinkTable->pHead->pNext; pLinkTable->SumOfNode -= 1 ; if(pLinkTable->SumOfNode == 0) { pLinkTable->pTail = NULL; } pthread_mutex_unlock(&(pLinkTable->mutex)); return SUCCESS; } tLinkTableNode * pTempNode = pLinkTable->pHead; while(pTempNode != NULL) { if(pTempNode->pNext == pNode) { pTempNode->pNext = pTempNode->pNext->pNext; pLinkTable->SumOfNode -= 1 ; if(pLinkTable->SumOfNode == 0) { pLinkTable->pTail = NULL; } pthread_mutex_unlock(&(pLinkTable->mutex)); return SUCCESS; } pTempNode = pTempNode->pNext; } pthread_mutex_unlock(&(pLinkTable->mutex)); return FAILURE; }
四.总结
通过对menu项目的迭代更新,我了解了如何将软件工程的思想体现在项目中。通过分离模块,解耦合。让各个模块相对独立,提高代码的错误率。并且在这个基础上可以进一步对模块抽象化,让其能够复用。
参考资料
原文:https://www.cnblogs.com/lirenwei/p/13949300.html