无论是对于Flink、Spark这样的实时计算框架还是hive等离线计算框架,数据量从来不是问题,真正引起问题导致严重后果的是数据倾斜。所谓数据倾斜,是指在大规模并行处理的数据中,其中某个运行节点处理的数据远远超过其他部分,这会导致该节点压力极大,最终出现运行失败从而导致整个任务失败。
目前我们所知道的大数据处理框架,比如Flink、Spark、Hadoop等之所以能处理高达千亿的数据,是因为这些框架都利用了分布式计算的思想,集群中多个计算节点并行,使得数据处理能力得到线性扩展。
在实际生产中Flink是以集群的形式在运行,在运行的过程中包含两类进程。其中TaskManager实际负责执行计算的Worker,在其上执行Flink Job的一组Task,Task则是我们执行具体代码逻辑的容器。理论上只要我们的任务Task足够多就可以对足够大的数据进行处理。
但是实际上大数据量经常出现,一个Flink作业包含200个Task节点,其中有199个节点可以在很短的时间内完成计算。但是有一个节点执行时间远超其他结果,并且随着数据量的持续增加,导致该计算节点挂掉,从而整个任务失败重启。我们可以在Flink的管理界面中看到任务的某一个Task数据量远超其他节点。
Flink任务出现数据倾斜的直观表现是任务节点频繁出现反压,但是增加并行度后并不能解决问题;部分节点出现OOM异常,是因为大量的数据集中在某个节点上,导致该节点内存被爆,任务失败重启。
产生数据倾斜的原因主要有2个方面:
解决问题的思路也很清晰:
KeyBy是经常使用的分组聚合函数之一。在实际的业务中经常会碰到这样的场景:双11按照下单用户所在的省聚合求订单量最高的前10个省,或者按照用户的手机类型聚合求访问量最高的设备类型等。
上述场景在外面进行KeyBy时就会出现严重的数据倾斜,如下图所示:
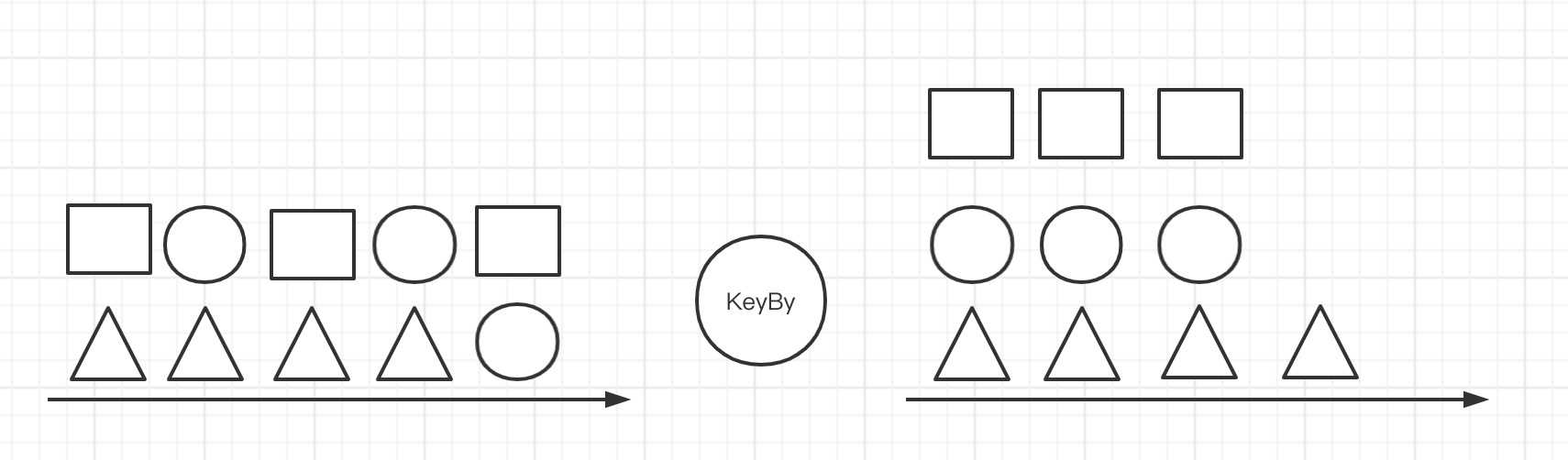
如果我们简单的使用KeyBy算子,模拟一个简单的统计PV的场景如下:
DataStream sourceStream = ...;
windowedStream = sourceStream.keyBy(‘type‘)
.window(TumblingEventTimeWindows.of(Time.minutes(1)));
windowedStream.process(new MyPVFunction())
.addSink(new MySink())...
env.execute()....
我们根据type进行keyBy时,如果数据的type分布不均匀就会导致大量的数据分配到一个task中去,发生数据倾斜。
解决思路:
DataStream sourceStream = ...;
resultStream = sourceStream
.map(record -> {
Record record = JSON.parseObject(record, Record.class);
String type = record.getType();
record.setType(type + "#" + new Random().nextInt(100));
return record;
})
.keyBy(0)
.window(TumblingEventTimeWindows.of(Time.minutes(1)))
.aggregate(new CountAggregate())
.map(count -> {
String key = count.getKey.substring(0, count.getKey.indexOf("#"));
return RecordCount(key,count.getCount);
})
//二次聚合
.keyBy(0)
.process(new CountProcessFunction);
resultStream.sink()...
env.execute()...
其中CountAggregate函数实现如下:
public class CountAggregate implements AggregateFunction<Record,CountRecord,CountRecord> {
@Override
public CountRecord createAccumulator() {
return new CountRecord(null, 0L);
}
@Override
public CountRecord add(Record value, CountRecord accumulator) {
if(accumulator.getKey() == null){
accumulator.setKey(value.key);
}
accumulator.setCount(value.count);
return accumulator;
}
@Override
public CountRecord getResult(CountRecord accumulator) {
return accumulator;
}
@Override
public CountRecord merge(CountRecord a, CountRecord b) {
return new CountRecord(a.getKey(),a.getCount()+b.getCount()) ;
}
}
CountProcessFunction的实现如下:
public class CountProcessFunction extends KeyedProcessFunction<String, CountRecord, CountRecord> {
private ValueState<Long> state = this.getRuntimeContext().getState(new ValueStateDescriptor("count",Long.class));
@Override
public void processElement(CountRecord value, Context ctx, Collector<CountRecord> out) throws Exception {
if(state.value()==0){
state.update(value.count);
ctx.timerService().registerProcessingTimeTimer(ctx.timerService().currentProcessingTime() + 1000L * 5);
}else{
state.update(state.value() + value.count);
}
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<CountRecord> out) throws Exception {
//这里可以做业务操作,例如每 5 分钟将统计结果发送出去
//out.collect(...);
//清除状态
state.clear();
//其他操作
...
}
}
通过上面打散聚合在二次聚合的方式,我们就可以实现热点key的打散,消除数据倾斜。
业务上通过groupby进行分组,然后紧跟一个SUM、COUNT等聚合函数操作是非常常见的。GroupBy函数会根据Key进行分组,完全依赖Key的设计,如果Key出现热点,那么会导致巨大的shuffle,相同key的数据会被发往同一个节点处理;如果某个key的数据量过大则会直接导致该节点成为计算瓶颈,引起反压。
按照上面的分组统计PV的场景,SQL语句如下:
select
date,
type,
sum(count) as pv
from table
group by
date,
type;
可以通过内外两层聚合的方式将SQL改为:
select date,
type,
sum(pv) as pv
from(
select
date,
type,
sum(count) as pv
from table
group by
date,
type,
floor(rand()*100) --随机打散成100份
)
group by
date,
type;
在上面的SQL拆成了内外两层,第一次通过随机打散100份的方式减少数据热点,当然这个打散的方式可以根据业务灵活指定。
在使用Flink处理实时业务时,上游一般都是消息系统,Kafka是使用最广泛的大数据消息系统。当使用Flink消费Kafka数据时,也会出现数据倾斜。
需要十分注意的是,Flink消费Kafka数据时,时推荐上下游并行去保持一致,即Kafka的分区数等于Flink Consumer的并行度。
但是有一种情况,为了加快数据的处理速度,来设置Flink消费者的并行度大于Kafka的分区数。如果不做任何的设置则会导致部分Flink Consumer现场永远消费不到数据。这时需要设置Flink的Redistributing,也就是数据重分配。Flink提供8种重分区策略,在接收到Kafka消息后,可以通过自定义数据分区策略实现数据的负载均衡,如:
dataStream
.setParallelism(2)
// 采用REBALANCE分区策略重分区
.rebalance() //.rescale()
.print()
.setParallelism(4);
rebalance分区策略,数据会以round-robin的方式对数据进行再次分区,可以全局负载均衡。rescale分区策略基于上下游的并行度,会讲数据以循环的方式输出到下游的每个实例中。
Flink一直在不断迭代,不断出现各种各样的手段解决遇到的数据倾斜问题,例如MiniBatch微批处理手段等,需要不断去发现。
原文:https://www.cnblogs.com/liufei-yes/p/13960807.html