函数是可重用的程序代码段,在Python中有常用的内置函数,例如len()、sum()等。 在Pyhon模块和程序中也可以自定义函数,使用函数可以提高编程效率
函数式编程使用一系列的函数解决问题。函数仅接受输入并产生输出,不包含任何能影响产生输出的内部状态。任何情况下,使用相同的参数调用函数始终能产生同样的结果。
在一个函数式的程序中,输入的数据“流过”一系列的函数,每一个函数根据它的输入产生输出。函数式风格避免编写有“边界效应”(side effects)的函数:修改内部状态,或者是其他无法反应在输出上的变化。完全没有边界效应的函数被称为“纯函数式的”(purely functional)。避免边界效应意味着不使用在程序运行时可变的数据结构,输出只依赖于输入。
可以认为函数式编程刚好站在了面向对象编程的对立面。对象通常包含内部状态(字段),和许多能修改这些状态的函数,程序则由不断修改状态构成;函数式编程则极力避免状态改动,并通过在函数间传递数据流进行工作。但这并不是说无法同时使用函数式编程和面向对象编程,事实上,复杂的系统一般会采用面向对象技术建模,但混合使用函数式风格还能让你额外享受函数式风格的优点。
函数式的风格通常被认为有如下优点:
这是一个学术上的优点:没有边界效应使得更容易从逻辑上证明程序是正确的(而不是通过测试)。
函数式编程推崇简单原则,一个函数只做一件事情,将大的功能拆分成尽可能小的模块。小的函数更易于阅读和检查错误。
小的函数更容易加以组合形成新的功能。
细化的、定义清晰的函数使得调试更加简单。当程序不正常运行时,每一个函数都是检查数据是否正确的接口,能更快速地排除没有问题的代码,定位到出现问题的地方。
不依赖于系统状态的函数无须在测试前构造测试桩,使得编写单元测试更加容易。
函数式编程产生的代码比其他技术更少(往往是其他技术的一半左右),并且更容易阅读和维护。
迭代器是一个可以记住遍历的位置的对象。
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
迭代器有两个基本的方法:iter() 和 next()。
创建一个迭代器:
把一个类作为一个迭代器使用需要在类中实现两个方法 __iter__() 与 __next__() 。
__iter__() 方法返回一个特殊的迭代器对象, 这个迭代器对象实现了 __next__() 方法并通过 StopIteration 异常标识迭代的完成。
__next__() 方法(Python 2 里是 next())会返回下一个迭代器对象。
示例:
创建一个返回数字的迭代器,初始值为 1,逐步递增 1:

在 Python 中,使用了 yield 的函数被称为生成器(generator)。
跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。
在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下一次执行 next() 方法时从当前位置继续运行。
调用一个生成器函数,返回的是一个迭代器对象。
示例:
使用 yield 实现斐波那契数列:
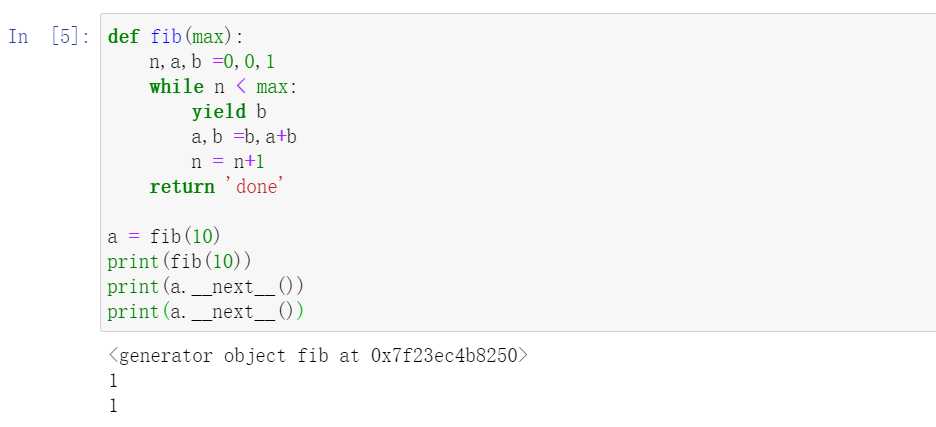
补充:yield 简述
yield 是一个类似 return 的关键字,迭代一次遇到yield时就返回yield后面(右边)的值,并且记住这个返回的位置,下次迭代就从这个位置后(下一行)开始。带有 yield的函数不再是一个普通函数,而是一个生成器generator,可用于迭代。
yield好处:
1.不会将所有数据取出来存入内存中,而是返回了一个对象,可以通过对象获取数据,用多少取多少,可以节省内容空间。
2.除了能返回一个值,还不会终止循环的运行;
通过next()可以恢复Generator执行,直到下一个yield。send()可以传递yield的值,send()在一定意义上与 next()作用相似的,next()和send(None)作用是一样的。注意:生成器刚启动时(第一次调用),请使用next()语句或是send(None),不能直接发送一个非None的值,否则会报TypeError,因为没有yield语句来接收这个值。
示例:

列表解析(List comprehensions)
列表解析式是将一个可迭代对象(如列表)转换成另一个列表的工具。在转换过程中,可以指定元素必须符合某一条件,并按照指定的表达式进行转换,才能添加至新的列表中。
语法: [expression for iter_var in iterable1] [expression for iter_var2 in iterable2 ... for iter_varN in iterableN] [expression for iter_var in iterable1 if condition] 执行: 迭代iterable中所有的元素,每一次迭代都把iterable中的内容放到iter_var对象中,然后把这个对象应用到表达式expression中,生成一个列表。
示例:

生成器表达式(Generator expressions)
不创建列表,只是返回一个生成器。这个生成器在每次计算出一个条目后,才把这个条目产生出来。所以在处理大量数据时更有优势。
语法: (expression for iter_var in iterable1) (expression for iter_var2 in iterable2 ... for iter_varN in iterableN) (expression for iter_var in iterable1 if condition) 执行: 迭代iterable中所有的元素,每一次迭代都把iterable中的内容放到iter_var对象中,然后把这个对象应用到表达式expression中,生成一个生成器。
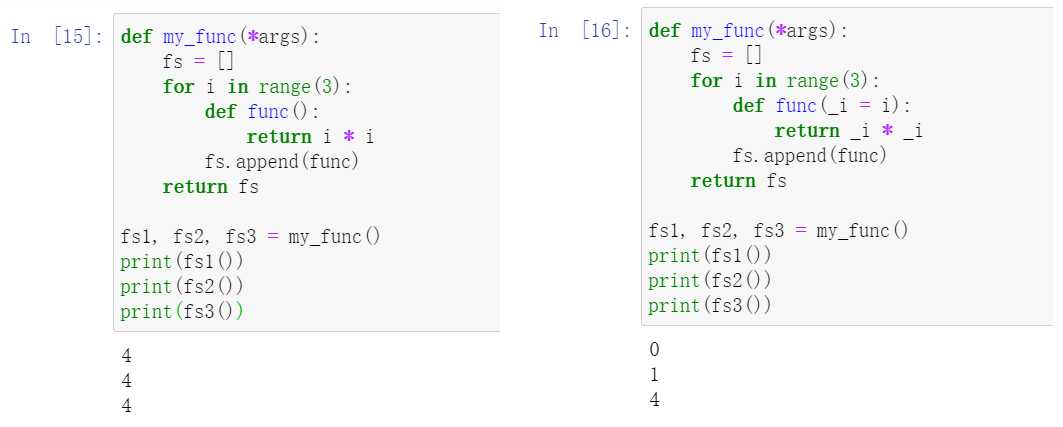
闭包的定义:
在一个外函数中定义了一个内函数,内函数里运用了外函数的临时变量,并且外函数的返回值是内函数的引用。这样就构成了一个闭包。
自由变量:
闭包所引用的外部作用域变量称为自由变量。闭包中的引用的自由变量只和具体的闭包有关联,闭包的每个实例引用的自由变量互不干扰。一个闭包实例对其自由变量的修改会被传递到下一次该闭包实例的调用。
闭包操作自由变量所需要的注意事项:
1.如果自由变量是可变对象(list,map...这里没有列出tuple是因为tuple是不可改变对象),那么闭包可以更新自由变量。
2.如果自由变量是不可变对象(数值,字符窜,tuple...),那么闭包不可以更新自由变量。
示例:
装饰器本质上是一个 Python 函数或类,它可以让其他函数或类在不需要做任何代码修改的前提下增加额外功能,装饰器的返回值也是一个函数/类对象。它经常用于有切面需求的场景,比如:插入日志、性能测试、事务处理、缓存、权限校验等场景,装饰器是解决这类问题的绝佳设计。有了装饰器,我们就可以抽离出大量与函数功能本身无关的雷同代码到装饰器中并继续重用。概括的讲,装饰器的作用就是为已经存在的对象添加额外的功能。
简单装饰器示例:
定义了一个打印出方法名及其参数的装饰器
import functools def log(func): @functools.wraps(func) def wrapper(*args, **kwargs): print(‘call %s():‘ % func.__name__) print(‘args = {}‘.format(*args)) return func(*args, **kwargs) return wrapper
使用语法糖@调用装饰器
@log def test(p): print(test.__name__ + " param: " + p) test("I‘m a param")
输出:
call test(): args = I‘m a param test param: I‘m a param
带参数的装饰器
携带了参数的装饰器将有三层函数,示例如下
import functools def log_with_param(text): def decorator(func): @functools.wraps(func) def wrapper(*args, **kwargs): print(‘call %s():‘ % func.__name__) print(‘args = {}‘.format(*args)) print(‘log_param = {}‘.format(text)) return func(*args, **kwargs) return wrapper return decorator @log_with_param("param") def test_with_param(p): print(test_with_param.__name__)
输出:
call test_with_param(): args = I‘m a param log_param = param test_with_param
注:@wraps接受一个函数来进行装饰,并加入了复制函数名称、注释文档、参数列表等等的功能。这可以让我们在装饰器里面访问在装饰之前的函数的属性。
python中如果将一个函数名传送给另一个函数作为形参,那么就成这个函数为高阶函数。
示例:

python 使用 lambda 来创建匿名函数。
? lambda只是一个表达式,函数体比def简单很多。
? lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
? lambda函数拥有自己的命名空间,且不能访问自有参数列表之外或全局命名空间里的参数。
? 虽然lambda函数看起来只能写一行,却不等同于C或C++的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。
语法
lambda函数的语法只包含一个语句,如下:
lambda [arg1 [,arg2,.....argn]]:expression
示例:

map() 会根据提供的函数对指定序列做映射。
第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的 Iterator。
语法
map() 函数语法:
map(function, iterable, ...)
参数
function -- 函数
iterable -- 一个或多个序列
返回值
存放结果的迭代器
示例:

reduce() 函数会对参数序列中元素进行累积。
函数将一个数据集合(链表,元组等)中的所有数据进行下列操作:用传给 reduce 中的函数 function(有两个参数)先对集合中的第 1、2 个元素进行操作,得到的结果再与第三个数据用 function 函数运算,最后得到一个结果。
语法
reduce() 函数语法:
reduce(function, iterable[, initializer])
参数
? function -- 函数,有两个参数
? iterable -- 可迭代对象
? initializer -- 可选,初始参数
返回值
返回函数计算结果
示例:

filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。
该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判断,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。
语法
filter() 方法的语法:
filter(function, iterable)
参数
? function -- 判断函数。
? iterable -- 可迭代对象。
返回值
过滤后的迭代器
示例:
筛选出所有含字符串 “str” 的单词

sorted() 函数对所有可迭代的对象进行排序操作。
sort 与 sorted 区别:
sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作。
list 的 sort 方法返回的是对已经存在的列表进行操作,无返回值,而内建函数 sorted 方法返回的是一个新的 list,而不是在原来的基础上进行的操作。
语法
sorted 语法:
sorted(iterable, cmp=None, key=None, reverse=False)
参数说明:
iterable -- 可迭代对象。
cmp -- 比较的函数,这个具有两个参数,参数的值都是从可迭代对象中取出,此函数必须遵守的规则为,大于则返回1,小于则返回-1,等于则返回0。
key -- 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
reverse -- 排序规则,reverse = True 降序 , reverse = False 升序(默认)。
返回值
返回重新排序的列表
示例:

zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的zip类型对象。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
语法
zip 语法:
zip([iterable, ...])
参数说明:
iterabl -- 一个或多个迭代器;
返回值
返回一个zip类型对象
示例:

注:博客部分内容转载于 Python函数式编程指南(一):概述
原文:https://www.cnblogs.com/keh123000/p/13958632.html