HDFS采用主/从架构。HDFS群集由单个NameNode和多个DataNode组成。
HDFS应用程序需要文件的一写多读访问模式。文件一旦创建、写入和关闭,除了追加和截断外,不需要更改。支持将内容追加到文件末尾,但不能在任意位置更新。此假设简化了数据一致性问题,并实现了高吞吐量数据访问。MapReduce应用程序或Web爬虫应用程序非常适合此模型。
“移动计算比移动数据更划算”(“Moving Computation is Cheaper than Moving Data”)
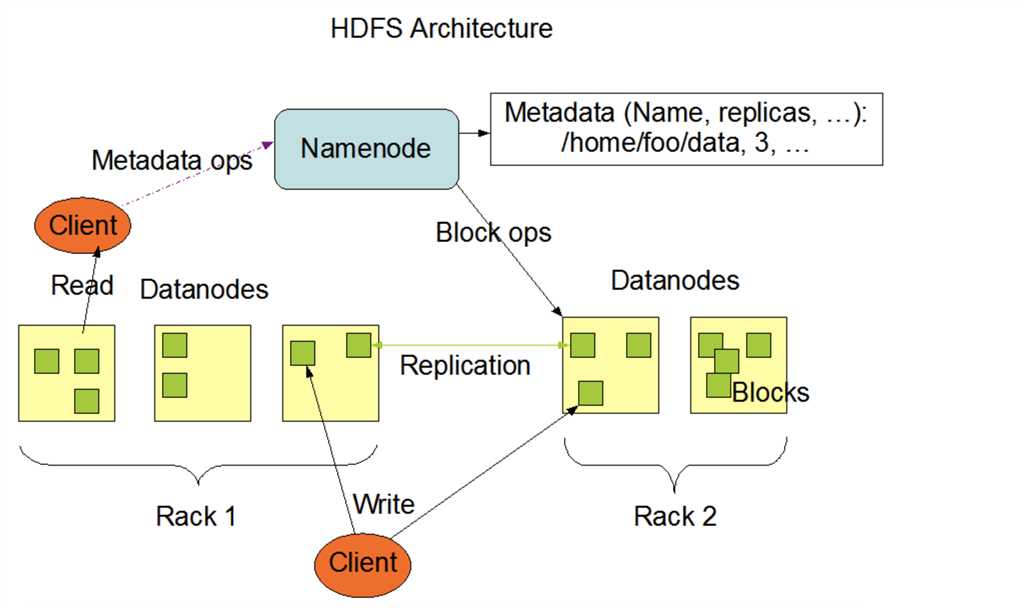
NameNode的职责:
DataNode的职责:
典型的部署有一台只运行NameNode软件的专用机器。集群中的每台其他机器都运行DataNode软件的一个实例。NameNode是所有HDFS元数据的仲裁器和存储库。系统的设计方式是用户数据永远不会流经NameNode。
原文:https://www.cnblogs.com/tantanli/p/13967187.html